
Hive on Spark、spark on yarn、hadoop HA集群搭建
一、版本选择
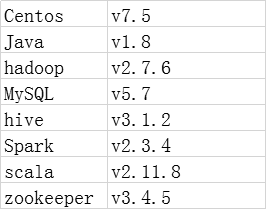
二、集群规划

三、准备工作
1、修改Linux主机名
2、修改IP
3、修改主机名和IP的映射关系
4、关闭防火墙
5、ssh免登陆
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ ssh-copy-id -i master-101
6、安装JDK,配置环境变量等
四、hadoop集群安装步骤
1、安装配置zooekeeper集群(在master-104上)
1.1、解压
$ tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/opt
1.2、修改配置
$ cd /home/hadoop/opt/zookeeper-3.4.5/conf/
$ cp zoo_sample.cfg zoo.cfg
$ vim zoo.cfg
#修改dataDir路径
dataDir=/home/hadoop/opt/zookeeper-3.4.5/tmp
#在最后添加
server.1=master-104:2888:3888
server.2=master-105:2888:3888
server.3=master-106:2888:3888
#创建相关目录及文件
$ mkdir /home/hadoop/opt/zookeeper-3.4.5/tmp
$ touch /home/hadoop/opt/zookeeper-3.4.5/tmp/myid
$ echo 1 > /home/hadoop/opt/zookeeper-3.4.5/tmp/myid
1.3、将配置好的zookeeper拷贝到其他节点
$ scp -r /home/hadoop/opt/zookeeper-3.4.5/ master-105:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/zookeeper-3.4.5/ master-106:/home/hadoop/opt/
##注意:修改master-105、master-106对应/home/hadoop/opt/zookeeper-3.4.5/tmp/myid内容
master-105节点下:
$ echo 2 > /home/hadoop/opt/zookeeper-3.4.5/tmp/myid
master-106节点下:
$ echo 3 > /home/hadoop/opt/zookeeper-3.4.5/tmp/myid
2、安装配置hadoop集群(在master-100上操作)
2.1解压
$ tar -zxvf hadoop-2.7.6.tar.gz -C /home/hadoop/opt
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
2.2.1、将hadoop添加到环境变量中
$ vim /etc/profile
export HADOOP_HOME=/home/hadoop/opt/hadoop-2.7.6 export HADOOP_CONF_DIR=/home/hadoop/opt/hadoop-2.7.6/etc/hadoop export YARN_CONF_DIR=/home/hadoop/opt/hadoop-2.7.6/etc/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.2.2、切换到hadoop配置文件目录
$ cd /home/hadoop/opt/hadoop-2.7.6/etc/hadoop
2.2.3、修改hadoop-env.sh
$ vim hadoop-env.sh
#jdkl路径
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_181
2.2.4、创建hadoop临时文件目录
$ mkdir -p /home/hadoop/opt/hadoop-2.7.6/tmp
2.2.5、修改core-site.xml
$ vim core-site.xml
<configuration> <!-- 指定hdfs的nameservice为ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://ns1/</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/opt/hadoop-2.7.6/tmp</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>master-104:2181,master-105:2181,master-106:2181</value> </property> <!--后面hive远程登录会用到--> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>hadoop</value> <description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>192.168.116.100,127.0.0.1,localhost</value> <description>The superuser can connect only from host1 and host2 to impersonate a user</description> </property> </configuration>
2.2.6、修改hdfs-site.xml
$ vi hdfs-site.xml
<configuration> <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>master-100:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>master-100:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>master-101:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>master-101:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master-104:8485;master-105:8485;master-106:8485/ns1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/opt/hadoop-2.7.6/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <!-- dfs权限设置为false,不然后面root缺少权限dfs.permissions=false --> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
2.2.7、修改mapred-site.xml
$ vi mapred-site.xml
<configuration> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master-102</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master-103</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>master-104:2181,master-105:2181,master-106:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>3072</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>3072</value> </property> <!-- 虚拟机资源少配置的,内存检查,CPU检查为false,生产不需设置--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--##NodeManager总的可用虚拟CPU个数--> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> </configuration>
2.2.8、修改slaves
$ vi slaves
master-104
master-105
master-106
2.3、将配置好的hadoop拷贝到其他节点
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-101:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-102:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-103:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-104:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-105:/home/hadoop/opt/
$ scp -r /home/hadoop/opt/hadoop-2.7.6/ master-106:/home/hadoop/opt/
2.4、启动zookeeper集群(分别在master-104、master-105、master-106上启动zk)
$ cd /home/hadoop/opt/zookeeper-3.4.5/bin/
$ ./zkServer.sh start
# 查看状态:一个leader,两个follower
$ ./zkServer.sh status
2.5、启动journalnode(分别在在master-104、master-105、master-106上执行)
$ cd /home/hadoop/opt/hadoop-2.7.6/
$ sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,master-104、master-105、master-106上多了JournalNode进程
2.6、格式化HDFS(在master-100上执行命令)
$ hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/home/hadoop/opt/hadoop-2.7.6/tmp,然后将/home/hadoop/opt/hadoop-2.7.6/tmp拷贝到master-101的/home/hadoop/opt/hadoop-2.7.6/下。
$ scp -r /home/hadoop/opt/hadoop-2.7.6/tmp/ master-101:/home/hadoop/opt/hadoop-2.7.6
# 也可以这样,建议hdfs namenode -bootstrapStandby
2.7、格式化ZKFC(在master-100上执行即可)
$ hdfs zkfc -formatZK
2.8、启动HDFS(在master-100上执行)
$ cd /home/hadoop/opt/hadoop-2.7.6/
$ sbin/start-dfs.sh
2.9、启动YARN(#####注意#####:是在master-102上执行start-yarn.sh)
$ cd /home/hadoop/opt/hadoop-2.7.6/
$ sbin/start-yarn.sh
2.10、验证
http://192.168.116.100:50070
NameNode 'master-100:9000' (active)
ResourceManager :http://192.168.116.102:8088/
http://192.168.116.101:50070
NameNode 'master-100:9000' (standby)
ResourceManager :http://192.168.116.103:8088/
五、spark on yarn安装
#####解压等略
1、环境变量配置
1.1、配置spark-env.sh
$ cd /home/hadoop/opt/spark-2.3.4-bin-hadoop276-without-hive/conf
$ cp spark-env.sh.template spark-env.sh
$ vi spark-env.sh
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_181
export HADOOP_HOME=/home/hadoop/opt/hadoop-2.7.6
export SCALA_HOME=/home/hadoop/opt/scala-2.12.6
export HADOOP_CONF_DIR=/home/hadoop/opt/hadoop-2.7.6/etc/hadoop
export HADOOP_YARN_CONF_DIR=/home/hadoop/opt/hadoop-2.7.6/etc/hadoop
export SPARK_HOME=/home/hadoop/opt/spark-2.3.4-bin-hadoop27-without-hive
export SPARK_WORKER_MEMORY=512m
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_DRIVER_MEMORY=512m
export SPARK_YARN_AM_MEMORY=512m
export SPARK_DIST_CLASSPATH=$(/home/hadoop/opt/hadoop-2.7.6/bin/hadoop classpath)
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=100 -Dspark.history.fs.logDirectory=hdfs://master-100:9000/spark/historyLog"
1.2、配置spark-defaults.conf
$ cp spark-defaults.conf.template spark-defaults.conf
$ vi spark-defaults.conf
spark.master yarn
spark.deploy.mode cluster
spark.yarn.historyServer.address master-100:18080
spark.history.ui.port 18080
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master-100:9000/spark/historyLog
spark.history.fs.logDirectory hdfs://master-100:9000/spark/historyLog
spark.eventLog.compress true
spark.executor.instances 1
spark.worker.cores 1
spark.worker.memory 512M
spark.eventLog.enabled true
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.yarn.jars=hdfs://master-100:9000/spark_jars/*
1.3、配置slaves
$ cp slaves.template slaves
$ vim slaves
master-104
master-105
master-106
1.4、将spark 的jars下的包上传到集群,防止每次发布job都从本地上传
$ cd /home/hadoop/opt/spark-2.3.4-bin-hadoop27-without-hive/jars
$ hadoop fs -mkdir /spark_jars
$ hadoop fs -put ./* /spark_jars
1.5、同步到其他两台机器上,(注意环境变量同步)
$ scp -r spark-2.3.4-bin-hadoop27-without-hive/ master-105:/home/hadoop/opt/
$ scp -r spark-2.3.4-bin-hadoop27-without-hive/ master-106:/home/hadoop/opt/
1.6、验证spark-shell
$ sh spark-shell --master yarn-client
1.7、启动spark
$ cd /home/hadoop/opt/spark-2.3.4-bin-hadoop27-without-hive/sbin
$ ./start-all.sh
1.8、 验证
$ cd /home/hadoop/opt/spark-2.3.4-bin-hadoop27-without-hive/
$ bin/spark-submit --master spark://master-104:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.3.0.jar 100
六、hive安装
1、安装mysql
参照:https://www.cnblogs.com/wishwzp/p/7113403.html
2、环境变量配置
2.1、配置hive-site.xml
$ cd /home/hadoop/opt/apache-hive-3.1.2-bin/conf
$ cp hive-default.xml.template hive-site.xml
$ vi hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.116.102:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://master-102:9083</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>master-102</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.client.user</name> <value>hive</value> <description>Username to use against thrift client</description> </property> <property> <name>hive.server2.thrift.client.password</name> <value>hive</value> <description>Password to use against thrift client</description> </property>
2.2、修改HADOOP_HOME
$ cp hive-env.sh.template hive-env.sh
$ vi hive-env.sh
HADOOP_HOME=/home/hadoop/opt/hadoop-2.7.6
2.3、放入数据库驱动
下载mysql-connector-java-5.1.39-bin.jar 包,复制放到/home/hadoop/opt/apache-hive-3.1.2-bin/lib/目录下就可以了
七、hive on spark配置
1、添加hive依赖的scala包,(在master-104节点机上执行)
$ cd /home/hadoop/opt/spark-2.3.4-bin-hadoop27-without-hive/jars/
$ scp -r scala-library-2.11.8.jar master-102:/home/hadoop/opt/apache-hive-3.1.2-bin/lib
$ scp -r spark-core_2.11-2.3.0.jar master-102:/home/hadoop/opt/apache-hive-3.1.2-bin/lib
$ scp -r spark-network-common_2.11-2.3.0.jar master-102:/home/hadoop/opt/apache-hive-3.1.2-bin/lib
注: 起初只添加了这三个依赖包,但是在后面的验证过程中,提示找不到相关类,故此处我将jars下面的所有jar包都复制到hive的lib目录中了。
2、配置相关文件(在master-102节点机上)
2.1 配置hive-site.xml
$ cd /home/hadoop/opt/apache-hive-3.1.2-bin/conf
$ vi hive-site.xml
<!--spark engine --> <property> <name>hive.execution.engine</name> <value>spark</value> </property> <property> <name>hive.enable.spark.execution.engine</name> <value>true</value> </property> <!--sparkcontext --> <property> <name>spark.master</name> <value>yarn</value> </property> <property> <name>spark.deploy.mode</name> <value>cluster</value> </property> <property> <name>spark.serializer</name> <value>org.apache.spark.serializer.KryoSerializer</value> </property> <property> <name>spark.executor.memory</name> <value>512m</value> </property> <property> <name>spark.driver.memory</name> <value>512m</value> </property> <property> <name>spark.eventLog.enabled</name> <value>true</value> </property> <property> <name>spark.yarn.historyServer.address</name> <value>master-100:18080</value> </property> <property> <name>spark.history.ui.port</name> <value>18080</value> </property> <property> <name>spark.yarn.jars</name> <value>hdfs://master-100:9000/spark_jars/*</value> </property> <property> <name>spark.eventLog.dir</name> <value>hdfs://master-100:9000/spark/historyLog</value> </property> <property> <name>spark.history.fs.logDirectory</name> <value>hdfs://master-100:9000/spark/historyLog</value> </property> <property> <name>spark.executor.extraJavaOptions</name> <value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value> </property>
2.2、初始化,在hive2.0以后的版本,初始化hive指令
$ schematool -dbType mysql -initSchema
2.3、启动hive元数据服务
$ nohup hive --service metastore > metastore.log 2>&1 &
$ nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
2.4、验证
$ beeline
beeline> !connect jdbc:hive2://master-102:10000 hive hive
create table tb_user(id int,name string ,age int);
insert into tb_user values(1,'name1',11),(2,'name2',12),(3,'name3',13);
注:HQL执行debug命令
$ hive --hiveconf hive.root.logger=DEBUG,console -e "insert into tb_user values(1,'name1',11),(2,'name2',12),(3,'name3',13)"
后序
后来在进一步理解hive on spark(yarn)的原理后,就有一个疑问,既然spark在这里只是作为一个计算引擎的话,还需要启动Master和Worker?,带着这个疑问,我将Master和Worker的进程都kill掉,并将spark的整个目录删除掉,再启动hive,操作后发现一切照常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号