python(jupyter)实现餐饮企业订单信息分析
1.导入所需要的包
# 导入包
import os
import numpy as np
import pandas as pd
from numpy import NaN
from pandas import DataFrame,Series
import matplotlib.pyplot as plt
from wordcloud import WordCloud
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
# 绘图魔术命令
%matplotlib inline
2.定义后面用到的函数
# 数组中元素大写转小写(返回list)
def arrayToLower(array:list):
return [a.lower() for a in array if isinstance(a,str)==True]
# 打开数据源(返回DataFrame)
def dataOpen(filepath:str,sheetindex:int,isData:bool):
try:
# 截取路径字符串
filetype=filepath.split('.')[1]
# 判断文件类型
rdata:DataFrame
if filetype=='csv':
data=pd.read_csv(open(filepath))# 读取数据源
rdata=pd.DataFrame.copy(data)# 复制数据源
if filetype=='xlsx':
if sheetindex<0:
data=pd.read_excel(filepath,0)
rdata=pd.DataFrame.copy(data)
else:
data=pd.read_excel(filepath,sheetindex)
rdata=pd.DataFrame.copy(data)
# 判断是否数据文件
if isData:
# 重命名
rdata.columns=arrayToLower(rdata.columns)# 列转小写
# 转换中文列名称
for i in range(0,len(all_tz)):
if rdata.columns.values.tolist()==all_tz[i]:
rdata.columns=all_sm[i]
#数据源处理
rdata=rdata.dropna(axis=1,how='all',thresh=1,inplace=False)# 删除无意义的空列
return rdata
except Exception as ex:
print(ex)
# 创建文件夹
def mkDirectory(path):
# 去除首位空格
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip(r'/')
# 判断路径是否存在
isExists=os.path.exists(path) # 存在True,不存在False
# 判断结果
if not isExists:# 如果不存在则创建文件夹
os.makedirs(path)
print(path+' 文件夹创建成功')
return True
else:# 如果目录存在则不创建,并提示目录已存在
print(path+' 文件夹已存在')
return False
#定义函数来显示柱状上的数值
def autoBarLabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x(),height+.1,height,fontsize=30)
3.数据源地址
源数据下载,非网盘,可直接下载 ,下载完解压在D盘即可
# 读取数据源或数据源地址
file_users=r'D:/DataSet/餐饮企业订单信息/users.xlsx'
file_meal_order_info=r'D:/DataSet/餐饮企业订单信息/meal_order_info.csv'
file_meal_order_detail=r'D:/DataSet/餐饮企业订单信息/meal_order_detail.xlsx's
file_state=r'D:/DataSet/餐饮企业订单信息/数据特征说明.xlsx'
4.打开数据源
4.1.打开数据特征说明表
# 原始数据
data_state_sourse=dataOpen(file_state,0,False)
# 填充NaN的数据
data_state_sourse=data_state_sourse.ffill()
# 处理后数据
data_state=data_state_sourse
# ---------------表特征说明字段-------------------
# 所有列名称
data_state_col=[column for column in data_state]
data_state_col_bm=data_state_col[0]# 表名
data_state_col_bz=data_state_col[1]# 备注
data_state_col_tz=data_state_col[2]# 特征
data_state_col_sm=data_state_col[3]# 说明
# 数据分组
data_group=data_state.groupby(by=data_state_col_bm)
data_group_all=[x for x in data_group]# 所有表分组
data_group_users=data_group_all[2]# 用户信息表
data_group_meal_order_info=data_group_all[1]# 订单表
data_group_meal_order_detail=data_group_all[0]# 订单详情表
# ---------用户信息表------------
users_tz=arrayToLower(data_group_users[1][data_state_col_tz])# 特征列数据
users_sm=data_group_users[1][data_state_col_sm].values.tolist()# 说明列数据
# -----------订单表--------------
info_tz=arrayToLower(data_group_meal_order_info[1][data_state_col_tz])# 特征列数据
info_sm=data_group_meal_order_info[1][data_state_col_sm].values.tolist()# 说明列数据
# ----------订单详情表-------------
detail_tz=arrayToLower(data_group_meal_order_detail[1][data_state_col_tz])# 特征列数据
detail_sm=data_group_meal_order_detail[1][data_state_col_sm].values.tolist()# 说明列数据
# 封装
all_tz=[users_tz,info_tz,detail_tz]# 特征
all_sm=[users_sm,info_sm,detail_sm]# 说明
4.2.打开用户信息表(返回data_users)
# 原始数据
data_users_sourse=dataOpen(file_users,0,True)
# 重命名指定列
data_users_sourse=data_users_sourse.rename(columns = {"用户ID": "会员ID"})
# 删除无用列
del data_users_sourse['用户自编码']
del data_users_sourse['组织代码']
del data_users_sourse['密码']
del data_users_sourse['QQ']
del data_users_sourse['微信']
del data_users_sourse['电子邮箱']
del data_users_sourse['备注']
del data_users_sourse['创建人']
del data_users_sourse['修改人']
del data_users_sourse['修改日期']
del data_users_sourse['姓名']
del data_users_sourse['算法ID']
del data_users_sourse['算法名称']
del data_users_sourse['创造日期']
# 删除管理员,老师无用行
#data_users_sourse.drop([0,1],axis = 0,inplace = True)
# 通过~取反,选取不含管理员,老师的行
data_users_sourse=data_users_sourse[~data_users_sourse['账号'].isin(['超级管理员','老师'])]
# 删除存在NaN的无用行
data_users_sourse.dropna(axis=0, how='any',inplace=True)
# 处理后数据
data_users=data_users_sourse
4.3.打开订单表(返回data_info)
# 原始数据
data_info_sourse=dataOpen(file_meal_order_info,0,True)
# 重命名指定列
data_info_sourse=data_info_sourse.rename(columns = {"订单状态:0:未结算;1:结算;2:已锁单": "订单状态"})
data_info_sourse=data_info_sourse.rename(columns = {"门店ID(org_info.id)": "门店ID"})
# 删除无用列
del data_info_sourse['订单状态']
del data_info_sourse['门店ID']
del data_info_sourse['桌子ID']
del data_info_sourse['电话']
# 删除存在NaN的无用行
data_info_sourse.dropna(axis=0, how='any',inplace=True)
# 处理后数据
data_info=data_info_sourse
4.4.打开订单详情表(返回data_detail)
# 选择读第几页
def dataSheet(sheetindex:int):
# 原始数据
data_detail_sourse=dataOpen(file_meal_order_detail,sheetindex,True)
# 清除菜品名称列的\n\r和空格
col_dishes_name=data_detail_sourse[detail_sm[5]]
data_detail_sourse[detail_sm[5]]=[col.replace('\n', '').replace('\r', '').replace(' ', '') for col in col_dishes_name]
# 删除无用列
del data_detail_sourse['订单详情ID']
del data_detail_sourse['会员ID']
del data_detail_sourse['菜品ID']
del data_detail_sourse['是否为添加菜']
del data_detail_sourse['添加价格']
del data_detail_sourse['图片']
return data_detail_sourse
# 读所有页
df0=dataSheet(0)
df1=dataSheet(1)
df2=dataSheet(2)
data_detail_sourse_all=pd.concat([df0,df1,df2],axis=0,ignore_index=True)# 纵向合并
# 删除存在NaN的无用行
data_detail_sourse_all.dropna(axis=0, how='any',inplace=True)
# 处理后数据
data_detail=data_detail_sourse_all
4.5.所有表合并(返回data_all)
# 根据订单ID合并订单表和订单详情表
data_all1=pd.merge(data_info,data_detail,how='outer',on=['订单ID'])
# 根据订会员ID合并用户信息表
data_all=pd.merge(data_all1,data_users,how='inner',on=['会员ID'])
# 删除无用列
del data_all['订单ID']
del data_all['会员ID']
del data_all['学号']
del data_all['桌子名称']
del data_all['账号']
del data_all['电话']
del data_all['第一次登录']
del data_all['最后一次登录']
del data_all['付费金额']
# 删除存在NaN的无用行
data_all.dropna(axis=0, how='any',inplace=True)
# 打印
file_data_all=r'D:/DataSet/餐饮企业订单信息/data_all.csv'
data_all.to_csv(file_data_all,index=False)
5.表分析
5.1.用户信息表分析
data_users
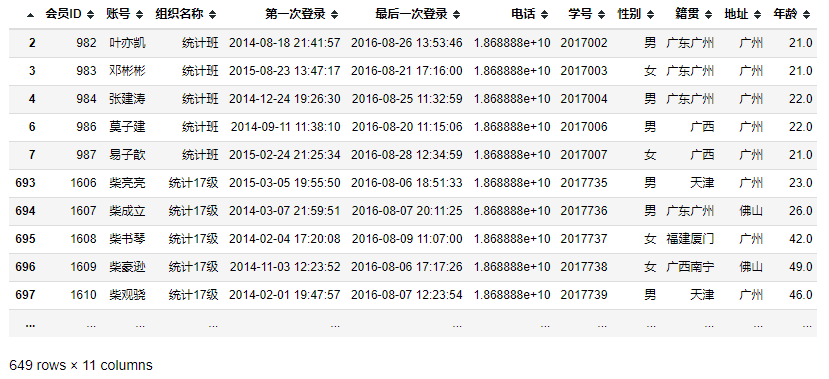
5.1.1.注册用户的籍贯分析
users_jg=data_users.groupby(by='籍贯').count()
users_jg_df1=pd.DataFrame({'籍贯':data_users['籍贯'].unique()})
users_jg_df2=pd.DataFrame({'数量':[0]*len(users_jg.values)})
# 合并
users_jg_df=pd.concat([users_jg_df1,users_jg_df2],axis=1,ignore_index=False)
users_jg_df['数量']=users_jg.values
# 引入数据
plt_x=users_jg_df['籍贯'].values
plt_y=users_jg_df['数量'].values
# 画图数据
plt.figure(figsize=(50,20),dpi=100) #设置画布大小
x=plt.bar(plt_x,plt_y,color='red',width=.8,label='籍贯')# 设置条形图
plt.xticks(users_jg_df['籍贯'],rotation=90,fontsize=30)# 设置X轴的数目与取值
plt.yticks(fontsize=20)# 设置Y轴标签的数目与取值
# 画图设置
plt.title('注册用户的籍贯分析条形图',fontsize=60)# 设置标题
plt.legend(loc='upper right',fontsize=40)# 设置图例
plt.xlabel('籍贯',fontsize=40)# 设置X轴标签
plt.ylabel('数量',fontsize=40)# 设置Y轴标签
plt.margins(0,.2)# 调节左右上下留白
autoBarLabel(x)# 显示数值
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/用户信息表分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'注册用户的籍贯分析条形图.png')
# 画图显示
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/用户信息表分析 文件夹创建成功
图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/用户信息表分析/ 下查看
5.2.订单表分析
data_info
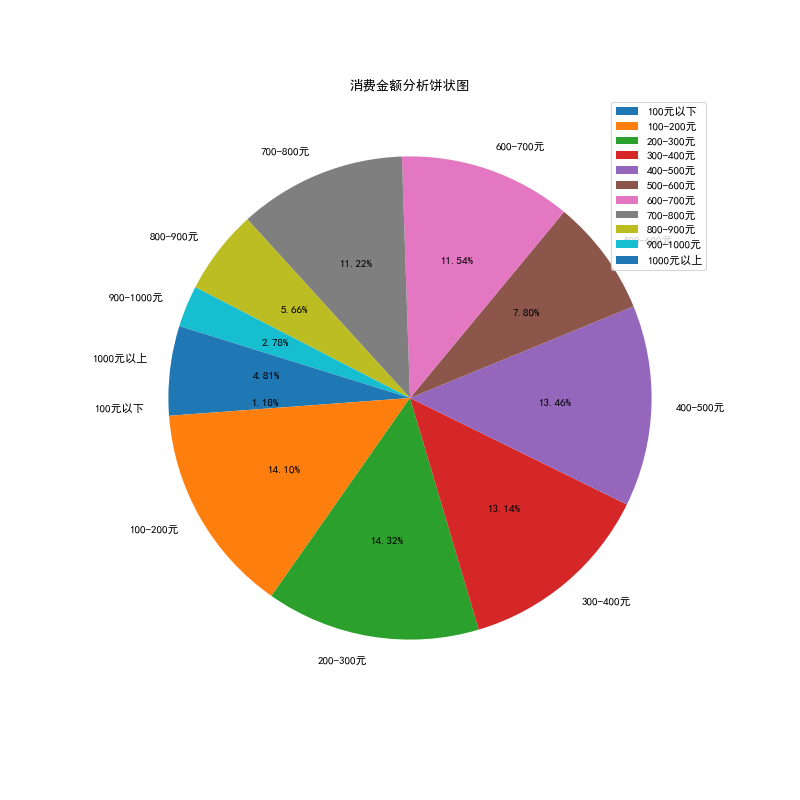
5.2.1.订单消费金额分析
# 引入数据
data_info_qj=[0,100,200,300,400,500,600,700,800,900,1000]
data_info_qj_cut=pd.cut(list(data_info['消费金额']),data_info_qj)
data_info_qj_cut_data=data_info_qj_cut.describe()
data_info_qj_percentage=(data_info_qj_cut_data['freqs'].values)*100
# 画图数据
plt.figure(figsize=(10,10),dpi=80) #设置画布大小
plt.title("消费金额分析饼状图",loc='center')
labels=['100元以下','100-200元','200-300元','300-400元','400-500元','500-600元','600-700元','700-800元','800-900元','900-1000元','1000元以上']
plt.pie(x=data_info_qj_percentage,labels=labels,autopct='%.2f%%',pctdistance=0.6,labeldistance=1.1,startangle=180)
plt.legend(loc='upper right',fontsize=10)
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/订单表分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'消费金额分析饼状图.png')
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/订单表分析 文件夹创建成功
图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/订单表分析/ 下查看
5.3.订单详情表分析
data_detail
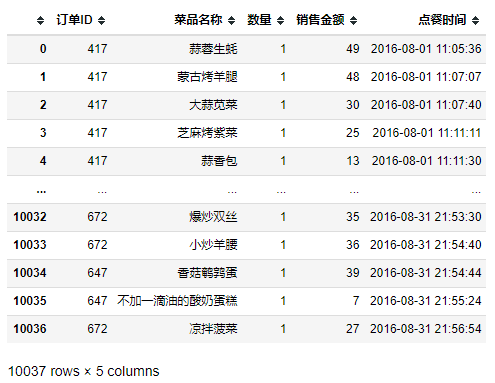
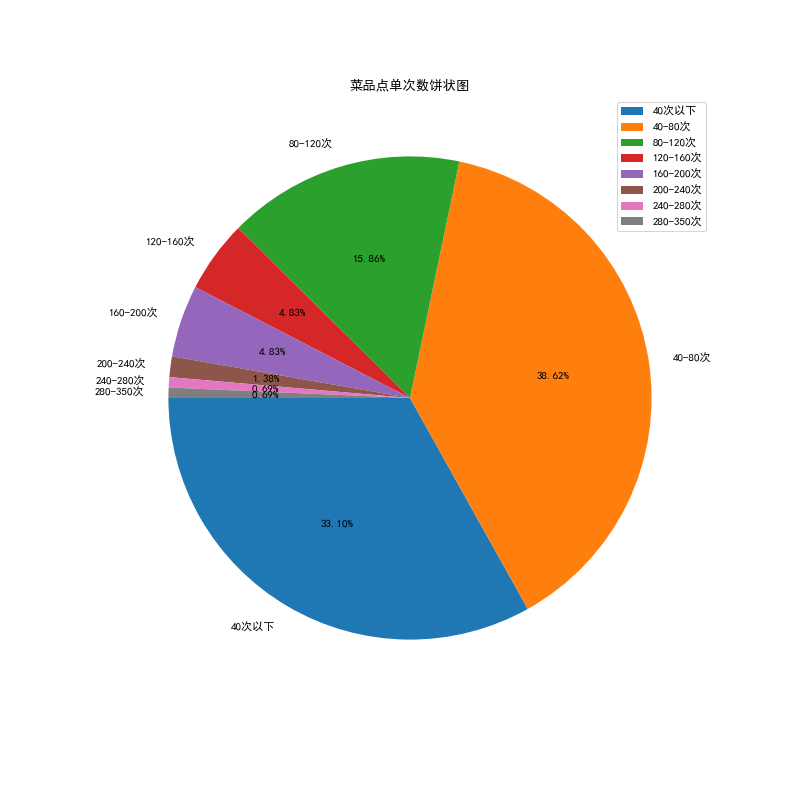
5.3.1.菜品点单次数分析
detail_cp=data_detail.groupby(by='菜品名称').count()
cpdd_df1=pd.DataFrame({'菜品名称':data_detail['菜品名称'].unique()})
cpdd_df2=pd.DataFrame({'数量':[0]*len(detail_cp.values)})
# 合并
cpdd_df=pd.concat([cpdd_df1,cpdd_df2],axis=1,ignore_index=False)
cpdd_df['数量']=detail_cp.values
5.3.1.1.菜品点单次数饼状图
# 引入数据
cpdd_df_qj=[1,40,80,120,160,200,240,280,350]
cpdd_df_qj_cut=pd.cut(list(cpdd_df['数量']),cpdd_df_qj)
cpdd_df_qj_cut_data=cpdd_df_qj_cut.describe()
cpdd_df_qj_percentage=(cpdd_df_qj_cut_data['freqs'].values)*100
# 画图数据
plt.figure(figsize=(10,10),dpi=80) #设置画布大小
plt.title("菜品点单次数饼状图",loc='center')
labels=['40次以下','40-80次','80-120次','120-160次','160-200次','200-240次','240-280次','280-350次']
plt.pie(x=cpdd_df_qj_percentage,labels=labels,autopct='%.2f%%',pctdistance=0.6,labeldistance=1.1,startangle=180)
plt.legend(loc='upper right',fontsize=10)
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/订单详情表分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'菜品点单次数饼状图.png')
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/订单详情表分析 文件夹创建成功
图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/订单详情表分析/ 下查看
5.3.1.2.菜品点单次数条形图
# 引入数据
plt_x=cpdd_df['菜品名称'].values
plt_y=cpdd_df['数量'].values
# 画图数据
plt.figure(figsize=(100,52),dpi=100) #设置画布大小
x=plt.bar(plt_x,plt_y,color='red',width=.8,label='菜品')# 设置条形图
plt.xticks(cpdd_df['菜品名称'],rotation=90,fontsize=30)# 设置X轴的数目与取值
plt.yticks(fontsize=20)# 设置Y轴标签的数目与取值
# 画图设置
plt.title('菜品点单次数条形图',fontsize=60)# 设置标题
plt.legend(loc='upper right',fontsize=40)# 设置图例
plt.xlabel('菜品名称',fontsize=40)# 设置X轴标签
plt.ylabel('数量',fontsize=40)# 设置Y轴标签
plt.margins(0,.2)# 调节左右上下留白
autoBarLabel(x)# 显示数值
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/订单详情表分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'菜品点单次数条形图.png')
# 画图显示
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/订单详情表分析 文件夹已存在
图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/订单详情表分析/ 下查看
5.4.总表综合分析
data_all
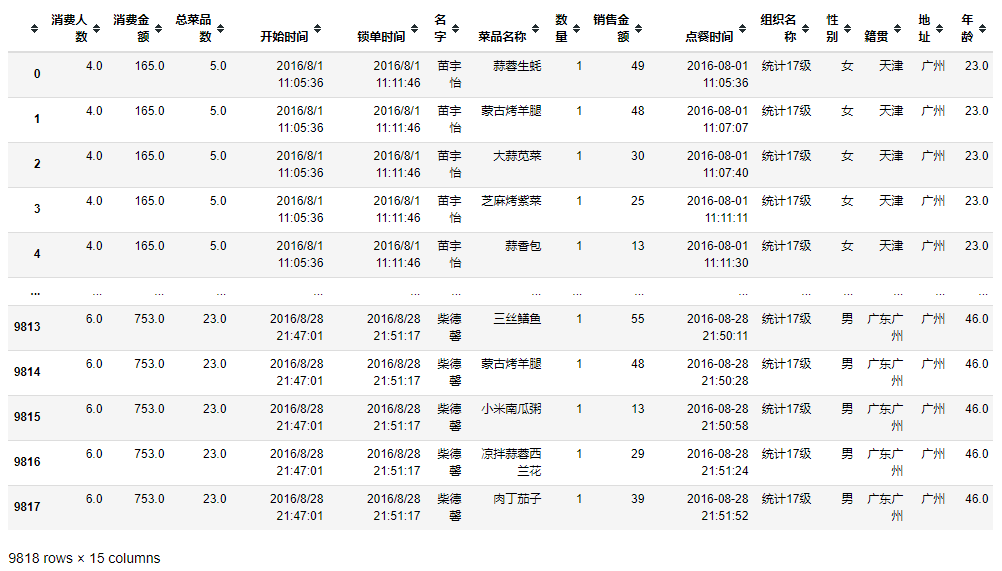
5.4.1.重点客户分析
textname=""
for i in data_all['名字'].tolist():
textname+=i+" "
textname
wordcloud = WordCloud(font_path=r'D:/DataSet/餐饮企业订单信息/font.ttf',background_color='white').generate("".join(textname))
plt.figure("",figsize=(50,20),dpi=200)
plt.imshow(wordcloud)
plt.axis("off")
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/总表综合分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'重点客户姓名词云图.png')
# 画图显示
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/总表综合分析 文件夹创建成功

图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/总表综合分析/ 下查看
5.4.2.菜品点单种类分析
textname=""
for i in data_all['菜品名称'].tolist():
textname+=i+" "
textname
wordcloud = WordCloud(font_path=r'D:/DataSet/餐饮企业订单信息/font.ttf',background_color='white').generate("".join(textname))
plt.figure("",figsize=(50,20),dpi=200)
plt.imshow(wordcloud)
plt.axis("off")
# 画图保存
savepath=r'Desktop/摘繁华数据分析文件/总表综合分析/'
mkDirectory(savepath)# 创建文件夹
plt.savefig(savepath+r'重点菜品词云图.png')
# 画图显示
plt.show()
print('图片保存成功!请在文件夹 '+savepath+' 下查看')
Desktop/摘繁华数据分析文件/总表综合分析 文件夹已存在

图片保存成功!请在文件夹 Desktop/摘繁华数据分析文件/总表综合分析/ 下查看
如果你觉得这篇文章还不错,请动动小指头点赞、收藏和关注哦!
若本文带给你很大帮助,也可以打赏博主一杯可乐ღゝ◡╹)ノ♡
摘繁华版权所有,转发或引用请附上原文链接哦!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理