
改题记录
https://blog.csdn.net/qq_45353993/article/details/129109027
记录一下欠的账吧
9/22
✘园艺 斜率优化dp,某人说我能改
9/23
✘光纤 听说能学到新东西,貌似是旋转凸壳?🤔🤔
9/24
✔ 三分 至少得会个板子吧🤔🤔
✔价值 貌似目前我解决地很困难😜😜
✘货币 好歹赛时写了这么久,还是把他改了吧,顺便学习网络流👍👍
9/27
记住两个式子:
and
根据它们可以推导得到:在
✔字符串 “少改一半,集训两个月就损失了一个月”
考虑贪心,首先分析题目性质:
-
对于
-
对于
考虑枚举
-
先考虑把
- 如果此时
- 如果还有剩,就将多余的
- 如果此时
-
此时再考虑
- 如果序列的末尾是
- 考虑用剩余的
- 如果序列的末尾是
✔奇怪的函数 听说可做,我应该能改?
感觉这题非常有意义啊,不仅启发了一些做题的性质,而且我觉得这题的代码还非常的巧妙。
- 考虑部分分
- 对于测试点
- 对于测试点
- 对于测试点
- 对于测试点
- 对于测试点
- 考虑正解
对于任意一段操作区间
我觉得代码里值得深思的东西有很多,Estelle_N 代码写的太好了
#include<bits/stdc++.h>
#define int long long
#define ls rt<<1
#define rs rt<<1|1
using namespace std;
const int maxx=1e5+5;
const int maxn=3e5+5;
const int INF=1e9;
int read(){
int x=0,f=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') f=-1;c=getchar();}
while (c>='0'&&c<='9') {x=(x<<1)+(x<<3)+(c^48);c=getchar();}
return x*f;
}
int n,q,a[maxn],b[maxn];
struct Node{
int l,r,o,v;
}f[10];
struct Segtree{
int l,r,c;
Node t[3];
}tr[maxn<<2];
void push_up(int rt){
int k=-1;
for (int i=0;i<tr[ls].c;i++)
for (int j=0;j<tr[rs].c;j++)
if (!tr[ls].t[i].o){//f(x) 一条直线
if (tr[ls].t[i].v>=tr[rs].t[j].l&&tr[ls].t[i].v<=tr[rs].t[j].r){
if (tr[rs].t[j].o)//g(x) 一条斜线
f[++k]=Node{tr[ls].t[i].l,tr[ls].t[i].r,0,tr[ls].t[i].v+tr[rs].t[j].v};
else//g(x) 一条直线
f[++k]=Node{tr[ls].t[i].l,tr[ls].t[i].r,0,tr[rs].t[j].v};
}
}
else{//f(x) 一条斜线
int L=tr[ls].t[i].l+tr[ls].t[i].v;
int R=tr[ls].t[i].r+tr[ls].t[i].v;
if (L<=tr[rs].t[j].r&&R>=tr[rs].t[j].l){//有交集
L=max(L,tr[rs].t[j].l)-tr[ls].t[i].v;
R=min(R,tr[rs].t[j].r)-tr[ls].t[i].v;
if (tr[rs].t[j].o)
f[++k]=Node{L,R,1,tr[ls].t[i].v+tr[rs].t[j].v};
else
f[++k]=Node{L,R,0,tr[rs].t[j].v};
}
}
tr[rt].c=0;
for (int i=0;i<=k;i++)//去重
if (i!=0&&f[i-1].o==f[i].o&&f[i-1].v==f[i].v)
tr[rt].t[tr[rt].c-1].r=f[i].r;
else tr[rt].t[tr[rt].c++]=f[i];
tr[rt].t[0].l=0;tr[rt].t[tr[rt].c-1].r=INF;
}
void solve(int rt,int l){
if (a[l]==1){
tr[rt].c=1;
tr[rt].t[0]=Node{0,INF,1,b[l]};//x+v
}
else if (a[l]==2){
tr[rt].c=2;
tr[rt].t[0]=Node{0,b[l],1,0};//x
tr[rt].t[1]=Node{b[l],INF,0,b[l]};//A
}
else{
tr[rt].c=2;
tr[rt].t[0]=Node{0,b[l],0,b[l]};//B
tr[rt].t[1]=Node{b[l],INF,1,0};//x
}
}
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
if (l==r) return solve(rt,l),void();
int mid=(l+r)>>1;build(ls,l,mid);
build(rs,mid+1,r);push_up(rt);
}
void update(int rt,int pos){
if (tr[rt].l==tr[rt].r)
return solve(rt,tr[rt].l),void();
int mid=(tr[rt].l+tr[rt].r)>>1;
if (pos<=mid) update(ls,pos);
else update(rs,pos);
push_up(rt);
}
void Work(int o,int pos,int v){
o=read();
if (o<=3){
pos=read();v=read();
a[pos]=o;b[pos]=v;
update(1,pos);
}
else{
v=read();
for (int i=0;i<tr[1].c;i++)
if (v>=tr[1].t[i].l&&v<=tr[1].t[i].r){
if (tr[1].t[i].o) printf("%lld\n",v+tr[1].t[i].v);
else printf("%lld\n",tr[1].t[i].v);
break;
}
}
}
signed main(){
freopen("function.in","r",stdin);
freopen("function.out","w",stdout);
n=read();
for (int i=1;i<=n;i++)
a[i]=read(),b[i]=read();
build(1,1,n);q=read();
while (q--) Work(0,0,0);
}
9/28
✔斯坦纳树 估计今天打了 ABC 后是改不完了
首先不难看出,点集在树上的斯坦纳树即为其虚树。虚树上的边权和即为其正确答案。
考虑题目的一个性质:设虚树上的点集为
证:假设虚树上有虚点(即在
得出了这个性质,这道题就迎刃而解了。但是还有一些小细节:
-
比如说怎么动态维护虚树上的点:开一个
-
对于边权为
-
这道题的根节点并不一定是
9/30
✔median 应该是签到题,签到题又没签上到
设序列编号为
考虑枚举每一个数为中位数的情况,此时就能确定该中位数的序列编号为多少,同时枚举它前面的另外两个序列编号为多少,这样就能确定它后面的连个序列编号了。
我们对于除了中位数序列的其它序列,考虑确定该位置能填多少数,设中位数的序列编号为
-
-
-
-
-
-
-
-
以上可以通过
✔travel 最重要的是读懂题
首先
题目就是求是否有一个点对
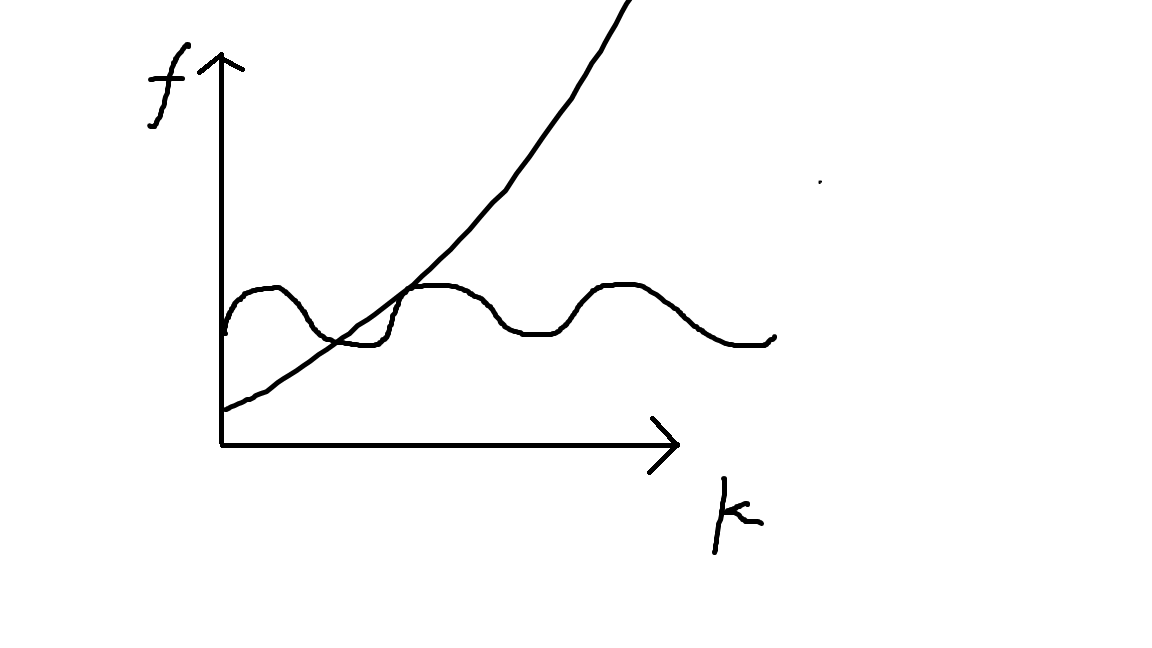
-
图中的波浪线可以看出是一个周期函数,考虑什么时候能有这样的周期:存在环,且环的大小不为
-
考虑什么时候有图中的斜线:如果存在两个连通的自环,那么它就可以在第一个自环一直绕圈(想走多少走多少)假设走
代码中有一些小细节,判环可以用拓扑排序判,注意一个点上有两个自环也算在情况二内。
✔game 博弈论,不用 SG 函数
-
法一
取自 Estelle_N,打表猜结论。结论为:所有数的出现次数都为偶数则先手必败,否则先手必胜。
证明 :
- 考虑只有两堆石子分别为
- 考虑只有两堆石子分别为
- 剩下的懒得证了
- 考虑只有两堆石子分别为
记录一个打表代码
#include<bits/stdc++.h>
#define se second
#define fi first
#define pb push_back
#define pp pop_back
using namespace std;
const int maxn=2e5+5;
int read(){
int x=0,f=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') f=-1;c=getchar();}
while (c>='0'&&c<='9') {x=(x<<1)+(x<<3)+(c^48);c=getchar();}
return x*f;
}
vector<int>x;
int T,n,sum,a[maxn];
map<vector<int>,bool>f;
bool find(vector<int> x);
bool dfs(vector<int> x,int pos,int k){
if (!k){//石子分配完了
sort(x.begin(),x.end());
return find(x);
}
//石子没分配完,但是已经分配了所有的石子堆
if (pos==(int)x.size()) return 1;
for (int i=0;i<=k;i++){
x[pos]+=i;
if (!dfs(x,pos+1,k-i))
return 0;
x[pos]-=i;
}
return 1;
}
bool find(vector<int> x){
//记忆化
if (f.count(x)) return f[x];
else sum=0;
for (auto it:x) sum+=it;
//边界条件
if (!sum) return 0;
if (x.size()==1) return 1;
vector<int>y;
for (int i=0;i<(int)x.size();i++)//枚举对 i 进行操作
for (int j=1;j<=x[i];j++){//枚举拿走了 j 个石子
y.clear();//不分配
for (int k=0;k<(int)x.size();k++)
if (k!=i) y.pb(x[k]);
if (x[i]-j)
y.push_back(x[i]-j);
sort(y.begin(),y.end());
if (!find(y)) return f[x]=1;
if (x[i]==j) continue;
y.clear();//分配
for (int k=0;k<(int)x.size();k++)
if (k!=i) y.pb(x[k]);
for (int k=1;k<=x[i]-j;k++){//枚举分配了 k 个石子
if (x[i]-j-k) y.pb(x[i]-j-k);
if (!dfs(y,0,k)) return f[x]=1;
if (x[i]-j-k) y.pp();
}
}
return f[x]=0;
}
void Work(){
n=read();x.clear();
for (int i=1;i<=n;i++)
a[i]=read();
sort(a+1,a+n+1);
for (int i=1;i<=n;i++)
x.push_back(a[i]);
printf("%s\n",find(x)?"Yes":"No");
}
signed main(){
freopen("game.in","r",stdin);
freopen("game.out","w",stdout);
T=read();while (T--) Work();return 0;
}
最后记录一个博弈论的定理:
-
一个必胜状态的后继状态至少有一个为必败状态
-
一个必败状态的后继状态都为必胜状态
✔counter 很清奇的做法,感觉改完后,码力++
首先需要读出,这道题是让你求
注意到我们每次最多移动 9 个点,所以从一段区间的左半部分移动到右半部分肯定会经过中间我觉得我可能一辈子都联想不到分治
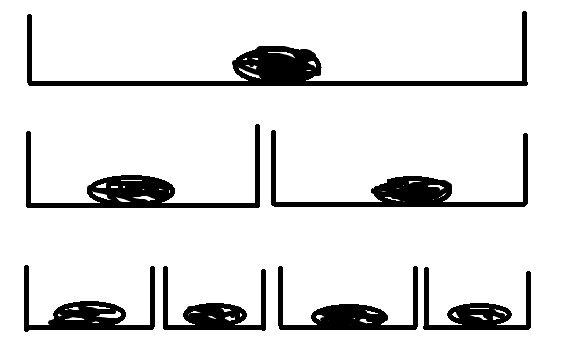
每段区间中的黑圈为中间点,我们预处理出区间
查询,当
小技巧:
-
处理正向距离(中间点到其它点)的时候,由
-
在存区间
记录改题的一次胜利
#include<bits/stdc++.h>
using namespace std;
const int N=20;
const int maxn=1e5+105;
const int INF=1e9;
int read(){
int x=0,f=1;char c=getchar();
while (c<'0'||c>'9') {if (c=='-') f=-1;c=getchar();}
while (c>='0'&&c<='9') {x=(x<<1)+(x<<3)+(c^48);c=getchar();}
return x*f;
}
bool vis[maxn];
int f[N][maxn][10][2];
int T,las,dis[maxn],tag[maxn];
vector<int>e[maxn];
void dij(int s){
queue<int>q;
dis[s]=0;q.push(s);
while (q.size()){
int x=q.front();q.pop();
if (vis[x]) continue;
vis[x]=1;
for (auto to:e[x])
if (!vis[to]&&dis[to]>dis[x]+1)
dis[to]=dis[x]+1,q.push(to);
}
}
void caldis(int d,int l,int r,int s,int id){
for (int i=1;i<=9;i++) tag[i]=0;
int L=max(l-30,0),R=r+30;
for (int i=L;i<=R;i++){
int x=i;e[i].clear();
dis[i]=INF;vis[i]=0;
while (x){
if (x%10&&tag[x%10]!=i){
int u=x%10;tag[u]=i;
if (i+u<=R) e[i].push_back(i+u);
if (i-u>=L) e[i].push_back(i-u);
}
x/=10;
}
}
dij(s);
for (int i=l;i<=r;i++)
f[d][i][id][1]=dis[i];//me to other
for (int i=1;i<=9;i++) tag[i]=0;
for (int i=L;i<=R;i++) e[i].clear();
for (int i=L;i<=R;i++){
int x=i;dis[i]=INF;vis[i]=0;
while (x){
if (x%10&&tag[x%10]!=i){
int u=x%10;tag[u]=i;
if (i+u<=R) e[i+u].push_back(i);
if (i-u>=L) e[i-u].push_back(i);
}
x/=10;
}
}
dij(s);
for (int i=l;i<=r;i++)
f[d][i][id][0]=dis[i];//other to me
}
void build(int d,int l,int r){
if (r-l+1<=9){
for (int i=l;i<=r;i++)
caldis(d,l,r,i,i-l);
return ;
}
int mid=(l+r)>>1,L=mid-4,R=mid+4;
for (int i=L;i<=R;i++)
caldis(d,l,r,i,i-L);
if (l<L) build(d+1,l,L-1);
if (r>R) build(d+1,R+1,r);
}
int query(int d,int l,int r,int x,int y,int o){
if (r-l+1<=9){
int ans=INF;
for (int i=l;i<=r;i++)
ans=min(f[d][x][i-l][o]+f[d][y][i-l][!o],ans);
return ans==INF?-1:ans;
}
int mid=(l+r)>>1,L=mid-4,R=mid+4;
if (x<=R&&y>=L){
int ans=INF;
for (int i=L;i<=R;i++){
ans=min(f[d][x][i-L][o]+f[d][y][i-L][!o],ans);
}
return ans==INF?-1:ans;
}
if (y<L) return query(d+1,l,L-1,x,y,o);
else return query(d+1,R+1,r,x,y,o);
}
void Work(){
int x=read(),y=read(),o;
x^=(las+1);y^=(las+1);o=0;
if (x>y) swap(x,y),o^=1;
if (x==y) las=0;
else las=query(0,0,1e5+30,x,y,o);
printf("%d\n",las);
}
signed main(){
freopen("counter.in","r",stdin);
freopen("counter.out","w",stdout);
memset(f,0x3f,sizeof(f));
T=read();
build(0,0,1e5+30);
while (T--) Work();return 0;
}
10/1
✔score and rank 思路清奇,甚至看了题解后都有点不明白为什么
题意简述:删掉序列中的若干个数,使得任意一个区间的和
容易得出当
那么就只需考虑
-
如果
-
如果
-
当前最大后缀的
-
否则一定能找到某几个较小的数,使得它们相加恰好
-
代码真的又少又清晰
#include<bits/stdc++.h>
#define int long long
#define in insert
#define er erase
#define cl clear
using namespace std;
const int maxn=1e6+5;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
multiset<int>s;
int n,m,ans;
int sum,a[maxn];
signed main(){
freopen("score.in","r",stdin);
freopen("score.out","w",stdout);
n=read();m=read();
if (m<=0){
for (int i=1;i<=n;i++)
ans+=read()>=m;
return printf("%lld\n",ans),0;
}
for (int i=1,x;i<=n;i++){
x=read();
if (x>0){
sum+=x,s.in(x);
if (sum>=m){
auto it=prev(s.end());
sum-=*it;s.er(it);++ans;
}
}
else if (x<0){
if (sum+x<=0) sum=0,s.cl();
else{
sum+=x;
while (x<0){
auto it=s.begin();
x+=*it;s.erase(it);
}
s.insert(x);
}
}
}
return printf("%lld\n",ans),0;
}
✔HZOI大作战 主要是倍增的状态设计
怎么求解
for (int i=1,u=i;i<=n;i++){
for (int j=log2(d[i]);j>=0;j--)
if (val[u][j]<=a[i]) u=f[u][j];
g[i][0]=u;u=i+1;
}
话不多说,看代码
#include<bits/stdc++.h>
#define pb push_back
using namespace std;
const int maxn=5e5+5;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
vector<int>he[maxn];
int ans=1,val[maxn][21];
int n,q,a[maxn],d[maxn];
int f[maxn][21],g[maxn][21];
void dfs(int x,int fa){
d[x]=d[fa]+1;f[x][0]=fa;
val[x][0]=a[x];
for (auto to:he[x])
if (to!=fa) dfs(to,x);
}
void init(){
for (int j=1;j<=log2(n);j++)
for (int i=1;i<=n;i++){
f[i][j]=f[f[i][j-1]][j-1];
val[i][j]=max(val[i][j-1],val[f[i][j-1]][j-1]);
}
for (int i=1;i<=n;i++){
int to=i;
for (int j=log2(d[i]);j>=0;j--)
if (val[to][j]<=a[i])
to=f[to][j];
g[i][0]=to;
}
for (int j=1;j<=log2(n);j++)
for (int i=1;i<=n;i++)
g[i][j]=g[g[i][j-1]][j-1];
}
signed main(){
freopen("accepted.in","r",stdin);
freopen("accepted.out","w",stdout);
n=read();q=read();
for (int i=1;i<=n;i++)
a[i]=read();
for (int i=1,x,y;i<n;i++){
x=read();y=read();
he[x].pb(y);he[y].pb(x);
}
dfs(1,0);init();
for (int i=1,u,v,c;i<=q;ans=1,i++){
u=read();v=read();c=read();
for (int j=log2(d[u]);j>=0;j--)
if (val[u][j]<=c) u=f[u][j];
if (d[u]<d[v]){printf("0\n");continue;}
if (d[u]==d[v]){printf("1\n");continue;}
for (int j=log2(d[u]);j>=0;j--)
if (d[g[u][j]]>=d[v])
ans+=(1<<j),u=g[u][j];
printf("%d\n",ans);
}
}
10/3
✔构造字符串 就是没最后连边,挂了 30 分
对于相同的位置用并查集维护,看成一个点
对于不相同的位置连边,每次贪心的从小到大枚举
补:
注意在维护并查集的时候应该把编号大的父亲设为编号小的,同时在连边时,应先把操作离线下来,最后再连
✔寻宝 啊啊啊,这么简单的题,我赛时的时候干嘛去了
我们把所有相连的“.”看成一个连通块,用并查集维护,传送门即为在这些连通块之间连边,跑一遍弗洛伊德看是否连通就好。
注意弗洛伊德的复杂度为
✔序列 趁这个机会学习了一下李超线段树

首先我们可以发现对于答案的区间 我并没发现
那我们现在就只需要讨论一种情况就好了,设
前面的已知,我们只需求后面括号中的最小值,就变成了李超树的板子题,直接套就好
✘构树

10/4
✔挤压 我一直弄不清的期望。。。
对于一个异或和
考虑对于每一位分别计算
看做把
那么剩下的问题就是求对于每个
if (check(a[i])){//表示可以转移
f[i][0]=f[i-1][1]*p[i]+f[i-1][0]*(1-p[i]+mod)%mod;
f[i][1]=f[i-1][0]*p[i]+f[i-1][1]*(1-p[i]+mod)%mod;
}
考虑
✔工地难题 只会打 20 分暴力
开局首先记住两个公式:
-
-
正解:
最长连续段恰好为
考虑我们用这些
这时我们再来考虑
最后一步容斥,思考为什么会减重复了,假设
用总方案数
设
for (int k=1,las=0;k<=m;k++){
int ans=0;f[0][0][0]=1;
for (int i=1;i<=n;i++)
for (int j=0;j<=min(i,m);j++)
for (int o=0;o<=min(j,k);o++){
if (i-j&&i-j<=m) f[i][j][0]+=f[i-1][j][o];
if (o) f[i][j][o]+=f[i-1][j-1][o-1];
}
for (int i=0;i<=k;i++)
ans+=f[n][m][i];
printf("%lld ",ans-las);
las=ans;
}
此时算出来的
✔星空遗迹 关键是要想到维护单调栈
可以发现当一段字符为“强弱强”时,比如
结论:我们可以维护一个单调递减的栈,栈顶为
正解:
对于每一段区间
考虑
这个和
把
✘纽带 题读不懂,暴力也不会打。。。
鉴于正解超出能力范围,故只写暴力。
首先如果你知道一个小函数 next_permutation(a+1,a+n+1) 生成给定序列的下一个字典序排列,它将会减少点你的代码量
其次,对于
还有,别去枚举 我真傻,真的
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=15;
const int maxn=105;
const int INF=1e18;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int n,m[N];
int p[N],ans[maxn];
signed main(){
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
n=read();
for (int i=1;i<=n;i++)
p[i]=i,m[i]=read();
do{
bool flag=1;int cnt=0;
for (int l=1;l<=n;l++){
for (int r=l,mi=p[l],ma=p[l];r<=m[l];r++){
mi=min(mi,p[r]);ma=max(ma,p[r]);
if (mi==l&&ma==r){flag=0;break;}
}
if (!flag) break;
}
if (!flag)continue;
for (int l=1;l<=n;l++)
for (int r=l,mi=p[l],ma=p[l];r<=n;r++){
mi=min(mi,p[r]);ma=max(ma,p[r]);
if (mi==l&&ma==r) ++cnt;
if (mi<l) break;
}
ans[cnt]++;
}
while (next_permutation(p+1,p+n+1));
for (int i=1;i<=n*(n+1)/2;i++)
printf("%lld ",ans[i]);
}
10/11
✔好数(number) 签到题签上到了耶
考虑
✔SOS字符串(sos) 赛时一眼简单题,发现思路假了破大防,后来一眼没看
考虑 DP 做法:
设
怎么优化,接下来就是今天的重头戏 “正难则反”,考虑当
✔集训营的气球(balloon) 写了个线段树维护 DP 的做法,结果发现正解在它下面
-
直接考虑 DP,设
-
又又考虑到 “正难则反”,发现
-
我们发现这题实际上是一个动态
-
正解做法为退背包,参考 P4141 消失之物 。我们空间优化后的转移方程式为
线段树代码
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=21;
const int maxn=2e6+1;
const int mod=1e9+7;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int cnt=1,n,c,q,a[maxn],b[maxn];
struct Segtree{
int l,r,tot;
int f[N],ls,rs;
}tr[maxn];
void push_up(int rt){
for (int i=0;i<c;i++)
tr[rt].f[i]=0;
for (int i=0;i<c;i++)
for (int j=0;i+j<c;j++)
tr[rt].f[i+j]=(tr[rt].f[i+j]+(ll)tr[tr[rt].ls].f[i]*tr[tr[rt].rs].f[j]%mod)%mod;
tr[rt].tot=(ll)tr[tr[rt].ls].tot*tr[tr[rt].rs].tot%mod;
}
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
if (l==r){
tr[rt].f[0]=b[l];
tr[rt].f[1]=a[l];
tr[rt].tot=a[l]+b[l];
return void();
}
tr[rt].ls=++cnt;tr[rt].rs=++cnt;
int mid=(l+r)>>1;build(tr[rt].ls,l,mid);
build(tr[rt].rs,mid+1,r);push_up(rt);
}
void update(int rt,int pos){
if (tr[rt].l==tr[rt].r){
tr[rt].f[0]=b[tr[rt].l];
tr[rt].f[1]=a[tr[rt].l];
tr[rt].tot=a[tr[rt].l]+b[tr[rt].l];
return void();
}
int mid=(tr[rt].l+tr[rt].r)>>1;
if (pos<=mid) update(tr[rt].ls,pos);
else update(tr[rt].rs,pos);push_up(rt);
}
signed main(){
freopen("balloon.in","r",stdin);
freopen("balloon.out","w",stdout);
n=read();c=read();
for (int i=1;i<=n;i++)
a[i]=read();
for (int i=1;i<=n;i++)
b[i]=read();
q=read();build(1,1,n);
for (int i=1,o,x,y;i<=q;i++){
o=read();x=read();y=read();
a[o]=x;b[o]=y;update(1,o);
int sum=tr[1].tot,ans=0;
for (int j=0;j<c;j++)
ans=(ans+tr[1].f[j])%mod;
printf("%d\n",(sum-ans+mod)%mod);
}
}
退包
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=21;
const int maxn=1e6+1;
const int mod=1e9+7;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int tot,n,c,q,a[maxn],b[maxn];
int f[N],fac[maxn],inv[maxn],ifa[maxn];
void init(){
tot=f[0]=1;
for (int i=1;i<=n;i++){
for (int j=c-1;j>0;j--)
f[j]=(f[j]*b[i]%mod+f[j-1]*a[i]%mod)%mod;
f[0]=f[0]*b[i]%mod;tot=tot*(a[i]+b[i])%mod;
}
}
int qpow(int a,int b){
int res=1;
while (b){
if (b&1) res=res*a%mod;
a=a*a%mod;b>>=1;
}
return res;
}
signed main(){
freopen("balloon.in","r",stdin);
freopen("balloon.out","w",stdout);
n=read();c=read();
for (int i=1;i<=n;i++)
a[i]=read();
for (int i=1;i<=n;i++)
b[i]=read();
q=read();init();
for (int i=1,o,x,y;i<=q;i++){
o=read();x=read();y=read();
//-> back
tot=tot*qpow(a[o]+b[o],mod-2)%mod;
int t=qpow(b[o],mod-2);f[0]=f[0]*t%mod;
for (int j=1;j<c;j++)
f[j]=(f[j]-f[j-1]*a[o]%mod+mod)*t%mod;
//-> go
a[o]=x;b[o]=y;int ans=0;
for (int j=c-1;j>0;j--)
f[j]=(f[j]*b[o]%mod+f[j-1]*a[o]%mod)%mod,ans=(ans+f[j])%mod;
tot=tot*(x+y)%mod;f[0]=f[0]*y%mod;;
printf("%lld\n",(tot-ans-f[0]+2*mod)%mod);
}
}
✘连通子树与树的重心(tree) 赛时看半天没看懂样例是怎么得出来的,就弃了
P4582 [FJOI2014] 树的重心 貌似是上面那题的弱化版
P2680 [NOIP2015 提高组] 运输计划 图论没做完的题
10/12
✔小 Z 的手套(gloves) 我居然也会在赛时写二分了
签到题没什么好说的,“最大值最小” 一眼二分,数据范围
多带一个
code
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+5;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int n,m,L[maxn],R[maxn];
bool check(int x){
int las=1;
for (int i=1;i<=n;i++){
if (las>m) return 0;
int t=lower_bound(R+las,R+m+1,L[i]-x)-R;
if (t>m) return 0;
if (R[t]>L[i]+x) return 0;
las=t+1;
}
return 1;
}
int binary_search(int l,int r){
while (l<r){
int mid=(l+r)>>1;
if (check(mid)) r=mid;
else l=mid+1;
}
return l;
}
signed main(){
freopen("gloves.in","r",stdin);
freopen("gloves.out","w",stdout);
n=read();m=read();
for (int i=1;i<=n;i++)
L[i]=read();
for (int i=1;i<=m;i++)
R[i]=read();
sort(L+1,L+n+1);
sort(R+1,R+m+1);
if (n>m){
for (int i=1;i<=m;i++)
swap(L[i],R[i]);
for (int i=m+1;i<=n;i++)
R[i]=L[i],L[i]=0;
swap(n,m);
}
int MAX=max(L[n]-R[1],R[n]-L[1]);
printf("%d\n",binary_search(0,MAX));
}
✔小 Z 的字符串(string) 贪了半天啥也没贪出来,还挂了20分
赛时尝试想了想 DP,设
正解:设
if (j>0) f[i][j][k][l][0]=min(f[i][j-1][k][l][1],f[i][j-1][k][l][2])+abs(pos-i);
其中
还有一种写法是不用除以
if (j>0) f[i][j][k][l][0]=min(f[i][j-1][k][l][1],f[i][j-1][k][l][2])+max(0,pos-i);
此时的转移明显是
赛时为什么挂了
if (check()) return printf("-1");
其实应该是。。。。
if (check()) return printf("-1"),0;
code
#include<bits/stdc++.h>
using namespace std;
const int maxx=405;
const int maxn=205;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
char s[maxx];
int cnt0,cnt1,cnt2;
int n,a[maxx],r[3][maxx];
int f[maxn][maxn][maxn][3];
bool check(){
if (cnt0>(n+1)/2) return 1;
if (cnt1>(n+1)/2) return 1;
if (cnt2>(n+1)/2) return 1;
return 0;
}
signed main(){
freopen("string.in","r",stdin);
freopen("string.out","w",stdout);
scanf("%s",s+1);
n=strlen(s+1);
for (int i=1;i<=n;i++){
a[i]=s[i]-'0';
if (a[i]==0) r[0][++cnt0]=i;
if (a[i]==1) r[1][++cnt1]=i;
if (a[i]==2) r[2][++cnt2]=i;
}
if (check()) return printf("-1\n"),0;
memset(f,0x3f,sizeof(f));
f[0][0][0][0]=f[0][0][0][1]=f[0][0][0][2]=0;
for (int i=0;i<=cnt0;i++)
for (int j=0;j<=cnt1;j++)
for (int k=0;k<=cnt2;k++){
int p=i+j+k;
if (i) f[i][j][k][0]=min(f[i][j][k][0],min(f[i-1][j][k][1],f[i-1][j][k][2])+max(0,r[0][i]-p));
if (j) f[i][j][k][1]=min(f[i][j][k][1],min(f[i][j-1][k][0],f[i][j-1][k][2])+max(0,r[1][j]-p));
if (k) f[i][j][k][2]=min(f[i][j][k][2],min(f[i][j][k-1][1],f[i][j][k-1][0])+max(0,r[2][k]-p));
}
printf("%d\n",min({f[cnt0][cnt1][cnt2][0],f[cnt0][cnt1][cnt2][1],f[cnt0][cnt1][cnt2][2]}));
}
✔一个真实的故事(truth) 第一次模拟赛场切两道,虽然是由于数据太水??
赛时由于 但是赛后被卡了。
错解:
对于每一个
对于每一个询问
code
#include<bits/stdc++.h>
#define ls rt<<1
#define rs rt<<1|1
using namespace std;
const int maxn=5e4+5;
const int INF=1e9;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int a[maxn][35];
int n,m,k,b[maxn];
int c[35],ans=INF;
struct Segtree{
int l,r,val;
}tr[maxn<<2];
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
tr[rt].val=INF;
if (l==r) return ;
int mid=(l+r)>>1;
build(ls,l,mid);
build(rs,mid+1,r);
}
void update(int rt,int pos,int val){
if (tr[rt].l==tr[rt].r)
return tr[rt].val=val,void();
int mid=(tr[rt].l+tr[rt].r)>>1;
if (pos<=mid) update(ls,pos,val);
else update(rs,pos,val);
tr[rt].val=min(tr[ls].val,tr[rs].val);
}
signed main(){
freopen("truth.in","r",stdin);
freopen("truth.out","w",stdout);
n=read();k=read();
m=read();build(1,1,n);
for (int i=1;i<=k;i++)
a[0][i]=c[i]=-INF;
for (int i=1;i<=n;i++){
b[i]=read();c[b[i]]=i;
int mi=INF;
for (int j=1;j<=k;j++)
a[i][j]=c[j],mi=min(mi,c[j]);
update(1,i,i-mi+1);
}
for (int i=1,op,p,x,y;i<=m;i++){
op=read();
if (op==2) printf("%d\n",tr[1].val>5e4?-1:tr[1].val);
else {
p=read();x=read();y=b[p];
if (x==y) continue;
bool flagx=0,flagy=0;
for (int j=p;j<=n;j++){
if (flagx&&flagy) break;
if (j!=p&&!flagy&&b[j]==y) flagy=1;
if (!flagx&&b[j]==x) flagx=1;
if (!flagy) a[j][y]=a[p-1][y];
if (!flagx) a[j][x]=p;
int mi=INF;
for (int o=1;o<=k;o++)
mi=min(mi,a[j][o]);
update(1,j,j-mi+1);
}
b[p]=x;
}
}
}
正解:
同样是用线段树维护答案,对于线段树上的每个点记录最右的
考虑是否可以合并,我们发现合并时更新前两个很好更新,关键时怎么更新
思考怎么计算中间过渡部分的
code
#include<bits/stdc++.h>
#define pai pair<int,int>
#define fi first
#define se second
#define mk make_pair
#define ls rt<<1
#define rs rt<<1|1
using namespace std;
const int maxn=5e4+5;
const int INF=1e9;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int n,k,m,a[maxn];
struct Segtree{
int l,r,ans,rc[31],lc[31];
}tr[maxn<<2];
void push_up(int rt){
int res=INF,sum=0,vis[k+1]={0};
int cnt=0;pai t[2*k+1];
for (int i=1;i<=k;i++){
if (tr[ls].lc[i]) tr[rt].lc[i]=tr[ls].lc[i];
else tr[rt].lc[i]=tr[rs].lc[i];
if (tr[rs].rc[i]) tr[rt].rc[i]=tr[rs].rc[i];
else tr[rt].rc[i]=tr[ls].rc[i];
if (tr[ls].rc[i]) t[++cnt]=mk(tr[ls].rc[i],i);
if (tr[rs].lc[i]) t[++cnt]=mk(tr[rs].lc[i],i);
}
for (int i=1;i<=k;i++)
if (!tr[rt].lc[i])
return tr[rt].ans=INF,void();
sort(t+1,t+cnt+1,[](pai x,pai y){
return x.fi<y.fi;});
for (int i=1,j=1;i<=cnt;i++){
if (t[i].fi==0) continue;
while (j<=cnt&&sum<k){
if (t[j].fi!=0){
if (!vis[t[j].se]) sum++;
vis[t[j].se]++;
}j++;
}
if (sum==k) res=min(res,t[j-1].fi-t[i].fi+1);
if (--vis[t[i].se]==0) sum--;
}
tr[rt].ans=min({res,tr[ls].ans,tr[rs].ans});
}
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
tr[rt].ans=INF;
if (l==r){
tr[rt].rc[a[l]]=l;
tr[rt].lc[a[l]]=l;
return void();
}
int mid=(l+r)>>1;build(ls,l,mid);
build(rs,mid+1,r);push_up(rt);
}
void update(int rt,int pos,int val){
if (tr[rt].l==tr[rt].r){
tr[rt].rc[val]=tr[rt].l;
tr[rt].lc[val]=tr[rt].l;
tr[rt].rc[a[tr[rt].l]]=0;
tr[rt].lc[a[tr[rt].l]]=0;
return void();
}
int mid=(tr[rt].l+tr[rt].r)>>1;
if (pos<=mid) update(ls,pos,val);
else update(rs,pos,val);push_up(rt);
}
signed main(){
freopen("truth.in","r",stdin);
freopen("truth.out","w",stdout);
n=read();k=read();m=read();
for (int i=1;i<=n;i++)
a[i]=read();
build(1,1,n);
for (int i=1,o,p,v;i<=m;i++){
o=read();
if (o==2) printf("%d\n",tr[1].ans>5e4?-1:tr[1].ans);
else {
p=read();v=read();
if (v==a[p]) continue;
update(1,p,v);a[p]=v;
}
}
}
✘异或区间(xor) 怎么还得学笛卡尔树啊,不想学
10/17
✔传送 (teleport) 哎,签到题没签上 😦
首先一眼看到
其实还是没有理解这类题为什么要排序的本质,一般都是因为排序后和相邻点的贡献是最优的。怎么理解这道题排序后和相邻点连边?考虑前面部分分的做法,排序后的点权就相当于放在了一条数轴上,传送就相当与是在数轴上走了一段连续的距离。设当前要从
那想拿到满分怎么办呢?其实还是一样的,分别把
✔排列 (permutation) 一眼感觉很可做,然后发现读假了
我再说一遍,当你想 DP 的时候,发现转移写不出来,一定要多设几维!!!能不能别转不出来硬转啊,你就不能多设几维吗?数据范围摆在那儿,你设个
正解:设
✔战场模拟器 (simulator) 狂写线段树,本来以为能捞个
赛后线段树调了半天,觉得自己写的相当没问题,可它就是 WA,发现我TM线段树空间开成了 maxn<<1。。。
对于第一档部分分,直接暴力就好,得分
对于第二档部分分,考虑用线段树维护,由于它保证了不会死亡,对于每个点记录区间的最小值,以及最小值的个数。查询时当区间最小值等于
对于第三档部分分,发现每次只是对一个人加护盾,最多只有
部分分代码
#include<bits/stdc++.h>
#define int long long
#define ls rt<<1
#define rs rt<<1|1
using namespace std;
const int maxn=2e5+5;
const int INF=1e18;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int n,a[maxn],Q,pro[maxn];
struct Query{
int o,l,r,x;
}q[maxn];
void solve1(){
for (int i=1,o,l,x;i<=Q;i++){
o=q[i].o;l=q[i].l;x=q[i].x;
if (o==1){
if (pro[l]) pro[l]--;
else{
a[l]-=x;
if (a[l]<0) a[l]=-INF;
}
}
else if (o==2) a[l]+=x;
else if (o==3) pro[x]++;
else if (o==4) printf(a[l]<0?"1\n":"0\n");
else printf(a[l]==0?"1\n":"0\n");
}
}
struct Segtree{
int l,r,val,tag,tot;
}tr[maxn<<2];
void push_up(int rt){
tr[rt].tot=0;
tr[rt].val=min(tr[ls].val,tr[rs].val);
if (tr[rt].val==tr[ls].val)
tr[rt].tot+=tr[ls].tot;
if (tr[rt].val==tr[rs].val)
tr[rt].tot+=tr[rs].tot;
}
void upd(int rt,int k){
tr[rt].tag+=k;tr[rt].val+=k;
}
void push_down(int rt){
if (!tr[rt].tag) return ;
int t=tr[rt].tag;tr[rt].tag=0;
return upd(ls,t),upd(rs,t),void();
}
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
if (l==r){
tr[rt].val=a[l];
tr[rt].tot=1;
return void();
}
int mid=(l+r)>>1;build(ls,l,mid);
build(rs,mid+1,r);push_up(rt);
}
void update(int rt,int l,int r,int k){
if (tr[rt].l>=l&&tr[rt].r<=r)
return upd(rt,k),void();
push_down(rt);
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) update(ls,l,r,k);
if (mid<r) update(rs,l,r,k);
push_up(rt);
}
int query(int rt,int l,int r){
if (tr[rt].l>=l&&tr[rt].r<=r){
if (!tr[rt].val) return tr[rt].tot;
return 0;
}
if (tr[rt].val>0) return 0;
push_down(rt);int res=0;
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) res+=query(ls,l,r);
if (mid<r) res+=query(rs,l,r);
return res;
}
int stk[maxn],top;
set<int>s;
void solve2(){
build(1,1,n);
for (int i=1,o,l,r,x;i<=Q;i++){
o=q[i].o;l=q[i].l;r=q[i].r;x=q[i].x;
if (o==1){
update(1,l,r,-x);
auto it=s.lower_bound(l);
while (it!=s.end()&&*it<=r){
update(1,*it,*it,x);
pro[*it]--;
if (!pro[*it]) stk[++top]=*it;
it=next(it);
}
while (top) s.erase(stk[top--]);
}
else if (o==2) update(1,l,r,x);
else if (o==3) {pro[x]++;s.insert(x);}
else if (o==4) printf("0\n");
else printf("%lld\n",query(1,l,r));
}
}
signed main(){
freopen("simulator.in","r",stdin);
freopen("simulator.out","w",stdout);
n=read();
for (int i=1;i<=n;i++)
a[i]=read();
Q=read();bool flag=1;
for (int i=1,o,l,r,x;i<=Q;i++){
o=read();
if (o<3){
l=read();r=read();x=read();
if (l!=r) flag=0;
q[i]=Query({o,l,r,x});
}
else if (o==3){
x=read();q[i]=Query({o,0,0,x});
}
else{
l=read();r=read();
if (l!=r) flag=0;
q[i]=Query({o,l,r,0});
}
}
if (flag) return solve1(),0;
else return solve2(),0;
}
第四档部分分,线段树维护区间最小值,区间最小值的个数,区间已经死亡的人数。由于每个人只会死一次,因此当区间最小值小于这次的伤害值,就暴力到叶子更新就行,均摊复杂度
满分做法,综合上述,线段树维护区间最小值,最小值个数,区间死亡人数,区间护甲个数。每次遇到护甲和死亡的情况直接暴力到叶子节点更新即可,均摊复杂度
code
#include<bits/stdc++.h>
#define int long long
#define ls rt<<1
#define rs rt<<1|1
#define _4781 0
using namespace std;
const int maxn=2e5+5;
const int INF=1e18;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
int n,a[maxn],Q;
struct Segtree{
int l,r,val,tag;
int pro,tot,die;
}tr[maxn<<2];
void push_up(int rt){
tr[rt].tot=0;
tr[rt].die=tr[ls].die+tr[rs].die;
tr[rt].pro=tr[ls].pro+tr[rs].pro;
tr[rt].val=min(tr[ls].val,tr[rs].val);
if (tr[rt].val==tr[ls].val)
tr[rt].tot+=tr[ls].tot;
if (tr[rt].val==tr[rs].val)
tr[rt].tot+=tr[rs].tot;
}
void upd(int rt,int k){
tr[rt].tag+=k;tr[rt].val+=k;
}
void push_down(int rt){
if (!tr[rt].tag) return ;
int t=tr[rt].tag;tr[rt].tag=0;
return upd(ls,t),upd(rs,t),void();
}
void build(int rt,int l,int r){
tr[rt].l=l;tr[rt].r=r;
if (l==r){
tr[rt].val=a[l];
tr[rt].tot=1;
return void();
}
int mid=(l+r)>>1;build(ls,l,mid);
build(rs,mid+1,r);push_up(rt);
}
void del(int rt,int l,int r,int k){
if (tr[rt].l>=l&&tr[rt].r<=r){
if (tr[rt].pro){
if (tr[rt].l==tr[rt].r)
return tr[rt].pro--,void();
push_down(rt);del(ls,l,r,k);
del(rs,l,r,k);push_up(rt);
return void();
}
if (tr[rt].val<k){
if (tr[rt].l==tr[rt].r){
tr[rt].val=INF;
tr[rt].die=1;
return void();
}
push_down(rt);del(ls,l,r,k);
del(rs,l,r,k);push_up(rt);
return void();
}
return upd(rt,-k),void();
}
push_down(rt);
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) del(ls,l,r,k);
if (mid<r) del(rs,l,r,k);
push_up(rt);
}
void add(int rt,int l,int r,int k){
if (tr[rt].l>=l&&tr[rt].r<=r)
return upd(rt,k),void();
push_down(rt);
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) add(ls,l,r,k);
if (mid<r) add(rs,l,r,k);
push_up(rt);
}
int dead(int rt,int l,int r){
if (tr[rt].l>=l&&tr[rt].r<=r)
return tr[rt].die;
push_down(rt);int res=0;
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) res+=dead(ls,l,r);
if (mid<r) res+=dead(rs,l,r);
return res;
}
void pro(int rt,int pos,int k){
if (tr[rt].l==tr[rt].r)
return tr[rt].pro+=k,void();
push_down(rt);
int mid=(tr[rt].l+tr[rt].r)>>1;
if (pos<=mid) pro(ls,pos,k);
else pro(rs,pos,k);
push_up(rt);
}
int danger(int rt,int l,int r){
if (tr[rt].l>=l&&tr[rt].r<=r){
if (!tr[rt].val) return tr[rt].tot;
return 0;
}
if (tr[rt].val>0) return 0;
push_down(rt);int res=0;
int mid=(tr[rt].l+tr[rt].r)>>1;
if (l<=mid) res+=danger(ls,l,r);
if (mid<r) res+=danger(rs,l,r);
return res;
}
signed main(){
freopen("simulator.in","r",stdin);
freopen("simulator.out","w",stdout);
n=read();
for (int i=1;i<=n;i++)
a[i]=read();
Q=read();build(1,1,n);
for (int i=1,o,l,r,x;i<=Q;i++){
o=read();
if (o==1) l=read(),r=read(),x=read(),del(1,l,r,x);
else if (o==2) l=read(),r=read(),x=read(),add(1,l,r,x);
else if (o==3) x=read(),pro(1,x,1);
else if (o==4) l=read(),r=read(),printf("%lld\n",dead(1,l,r));
else l=read(),r=read(),printf("%lld\n",danger(1,l,r));
}
return _4781;
}
✘ 点亮 (light) 发现自己连暴力分都不会打时就弃了
10/19
✔排列最小生成树 (pmst) 赛时以为 T1 是签,想不出来破防了
第一个转化,思考对于
第二个转化,我们怎么找到边权为
第三个转化,排序和是
✔卡牌游戏 (cardgame) 策略很差+心态不好,没看出来是签
首先对于前几档部分分,很容易看出当
考虑当 我都不知道我赛时连手摸样例都没直接打暴力是怎么想的)规律就是每个
考虑怎么证这个结论啊,对于每一轮
我们发现整数
✔比特跳跃 (jump) 连暴力分也挂了,特殊性质也没想其实通过大样例应该是看的出来的
-
按位与 &
这一部分应该是最好想的:对于二进制结尾为
但是有一个特例,例如
-
按位异或 ^
每一次异或产生的贡献主要由有多少个不同的
那我们就可以只考虑只有一个不同的
-
按位或 |
还是看性质吧:对于或操作来说,贡献与原来的
做法如下:由于我们不可能对于每个
✘区间 (interval) 区间历史版本和线段树,学学学!!!
10/29
✔追逐游戏 (chase) 赛时就知道这是签到题,但是赛时就知道自己没签上...
我也不知道赛时怎么就想了一个超级无敌巨多细节的分讨,而我甚至都不知道某些情况该怎么写判断条件,就这样我赛时硬磕了 跑的还特慢。最后花了
我跑的很慢的写法:
正解:发现其实就只有两种情况,一是
✔统计 感觉自己每次都想不到用哈希解决问题
我们对于
考虑当一段区间
设
这样我们处理出
✔软件工程 也是骗上暴力分了耶
感觉最近老是忘了写贪心这个东西,可能是被真正的贪心题老是贪假弄怕了。但是什么思路都没有的时候,写写贪心还是挺好的。
-
把所有线段按长度从小到大排序,前
-
枚举
这两种情况具体是怎么分出来的我还不是很清楚,咕。
✘命运的X 也是读不懂题了耶
10/31
✔四舍五入 签到题没签上,硬控
我们先考虑对于每个
正难则反,考虑对于每个
✔填算符 DP 写完了才发现这玩意儿根本不能用 DP
赛时硬控一小时读错题了,赛后又读错题了,直到讲题的时候才发现。
首先题目有一个结论:把所有的“与”运算符放在前 愣是没发现
然后我们就有了一种
思考怎么优化,对于
那如果不是
✔道路修建 赛时调了两个小时暴力都没调出来
感觉这道题最重要的两个套路就是:把路径长度转化为边经过的次数,把边的信息挂在点上倍增处理。
首先有个很明显的性质,加了边后
先处理出加边前的贡献,在加上加边后的贡献。加边前的贡献很好处理,dfs 的时候直接预处理就行了,每条边的贡献为
以下我们的讨论基于
-
“环边”产生的贡献
考虑新加了一条边后,每一个点都可以经过两条路径到达与它不是同一颗子树内的点,则该答案为
但是这样我们发现对于一条“环边”,我们是把它在加边前的贡献也算进去了的,我们还需要减去这部分多算的,所以“环边”产生的总贡献为
-
“环点子树内的边”产生的贡献
首先为了计算这部分答案,我们肯定要对于每个“环点”预处理出其子树内每个点到它的距离,什么时候会产生贡献,就是考虑它到与它不在同一颗子树内的点的路径的时候。答案即为
讲一下怎么特判
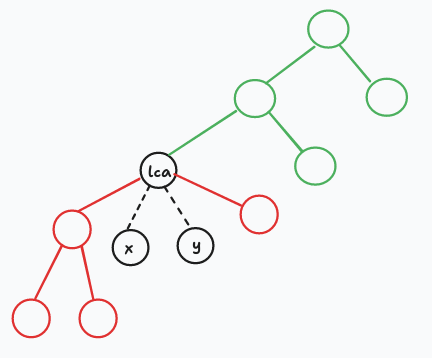
注意特判一下同一条链的清空即可。
code
#include<bits/stdc++.h>
#define int long long
#define pb push_back
#define pp pop_back
using namespace std;
const int maxn=3e5+5;
const int mod=998244353;
int read(int x=0,bool f=1,char c=0){
while (!isdigit(c=getchar())) f=c^45;
while (isdigit(c)) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return f?x:-x;
}
vector<int>he[maxn];
int n,q,type,las,sum;
int d[maxn],siz[maxn],f[maxn][22];
int ans,dis[maxn],up[maxn],ny2;
int g1[maxn][22],g2[maxn][22],g3[maxn][22];
int qp(int x){return x*x%mod;}
int qpow(int a,int b){
int res=1;
while (b){
if (b&1) res=res*a%mod;
a=a*a%mod;b>>=1;
}
return res;
}
void dfs1(int x,int fa){
d[x]=d[fa]+1;f[x][0]=fa;
for (int j=1;j<=log2(n);j++)
f[x][j]=f[f[x][j-1]][j-1];
for (auto to:he[x])
if (to!=fa){
dfs1(to,x);siz[x]+=siz[to];
dis[x]+=dis[to]+siz[to];
}
}
void dfs2(int x,int fa){
for (int j=1;j<=log2(n);j++){
g1[x][j]=g1[x][j-1]+g1[f[x][j-1]][j-1];
g2[x][j]=g2[x][j-1]+g2[f[x][j-1]][j-1];
g3[x][j]=g3[x][j-1]+g3[f[x][j-1]][j-1];
g1[x][j]%=mod;g2[x][j]%=mod;g3[x][j]%=mod;
}
for (auto to:he[x])
if (to!=fa){
g2[to][0]=siz[to]*(n-siz[to])%mod;
up[to]=(up[x]+n-siz[to]+dis[x]-dis[to]-siz[to])%mod;
g3[to][0]=(dis[x]-dis[to]-siz[to])%mod*(n-siz[x]+siz[to])%mod;
g1[to][0]=qp(siz[x]-siz[to]);sum=(sum+g2[to][0])%mod;dfs2(to,x);
}
}
int lca(int x,int y){
if (x==y) return x;
if (d[x]<d[y]) swap(x,y);
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>=d[y]) x=f[x][j];
if (x==y) return x;
for (int j=log2(d[x]);j>=0;j--)
if (f[x][j]!=f[y][j])
x=f[x][j],y=f[y][j];
return f[x][0];
}
int getsiz2(int x,int y,int o){
if (o){
int res=qp(siz[x]);
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>d[y])
res+=g1[x][j],x=f[x][j];
return (res+qp(n-siz[x]))%mod;
}
int res=qp(siz[x])+qp(siz[y]);
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>=d[y])
res+=g1[x][j],x=f[x][j];
for (int j=log2(d[x]);j>=0;j--)
if (f[x][j]!=f[y][j]){
res+=g1[x][j]+g1[y][j];
x=f[x][j];y=f[y][j];
}
return (res+qp(n-siz[x]-siz[y]))%mod;
}
int getsur(int x,int y,int o){
int res=0;
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>=d[y])
res+=g2[x][j],x=f[x][j];
if (o) return res%mod;
for (int j=log2(d[x]);j>=0;j--)
if (f[x][j]!=f[y][j]){
res+=g2[x][j]+g2[y][j];
x=f[x][j];y=f[y][j];
}
return (res+g2[x][0]+g2[y][0])%mod;
}
int getdis(int x,int y,int o){
if (o){
int res=dis[x]%mod*(n-siz[x])%mod;
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>d[y])
res+=g3[x][j],x=f[x][j];
return (res+(dis[y]-dis[x]-siz[x]+up[y])%mod*siz[x]%mod)%mod;
}
int res=dis[x]%mod*(n-siz[x])%mod;
res+=dis[y]%mod*(n-siz[y])%mod;
for (int j=log2(d[x]);j>=0;j--)
if (d[f[x][j]]>=d[y])
res+=g3[x][j],x=f[x][j];
for (int j=log2(d[x]);j>=0;j--)
if (f[x][j]!=f[y][j]){
res+=g3[x][j]+g3[y][j];
x=f[x][j],y=f[y][j];
}
int tmp=up[f[x][0]]+dis[f[x][0]];
tmp+=-dis[x]-dis[y]-siz[x]-siz[y];
return (res+tmp%mod*(siz[x]+siz[y])%mod)%mod;
}
void solve(int x,int y,int lc){
if (x==y) return ans=sum,void();
if (d[x]<d[y]) swap(x,y);
int len=d[x]+d[y]-2*d[lc]+1;
bool t=(lc==y)?1:0;
ans=sum+len*(qp(n)-getsiz2(x,y,t)+mod)%mod*ny2%mod;
ans=(ans-getsur(x,y,t)+getdis(x,y,t)+mod)%mod;
}
signed main(){
freopen("tree.in","r",stdin);
freopen("tree.out","w",stdout);
n=read();q=read();
type=read();ny2=qpow(2,mod-2);
for (int i=1,x,y;i<n;i++){
x=read();y=read();siz[i]=1;
he[x].pb(y);he[y].pb(x);
}
siz[n]=1;dfs1(1,0);dfs2(1,0);
for (int i=1,x,y;i<=q;i++){
x=read();y=read();
if (type) x^=las,y^=las;
ans=0;solve(x,y,lca(x,y));
printf("%lld\n",ans);las=ans;
}
}
11/2
✔网格 以为是签到题,赛后发现大家都没过
没手模第二个样例,导致题一直读假了,最后还剩
通过写暴力我们发现,在计算一种方案的值的时候,其实就是一堆乘积的和,我们只需要三个维护东西:当前的结果
那现在是要同时计算多种方案的值,我们 DP 就好。设
✔矩形 数据比较水,很容易骗分
赛时
正解:来源于
✔图书管理 签到题没签上
考虑每个
对于
✔函数 感觉也是签到题
找出
否则每次二分
找到



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】