
第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图:

item位于原理图的最左边
item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误。
1、创建item
在创建item时需要继承scrapy.Item类,并且定义scrapy.Field字段。由于我们在上一节Scrapy爬虫框架之项目创建spider文件数据爬取当中提取了id、url、title、thumb四个字段。所以我们在item.py文件当中需要创建者四个字段。
# -*- coding: utf-8 -*- # item.py import scrapy class Bole_mode(scrapy.Item): id = scrapy.Field() # id url = scrapy.Field() # 图片链接 title = scrapy.Field() # 标题 thumb = scrapy.Field() # 缩略图
2、spider使用item
之前说过item文件是报存爬取数据的容器,所以我们在上一节当中爬取下来的数据需要使用item进行暂存。
在进行使用之前需要对这个item进行实例化 item = Bole_mode()。
代码如下
1 # BLZXSPider.py 2 3 import scrapy 4 import json 5 import sys 6 7 sys.path.append(r'D:\spider\bole\item.py') 8 from bole.items import Bole_mode 9 10 class BoleSpider(scrapy.Spider): 11 name = 'boleSpider' 12 13 def start_requests(self): 14 url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1" 15 page = self.settings.get("MAX_PAGE") 16 for i in range(int(page)+1): 17 yield scrapy.Request(url=url.format(i*30)) 18 19 def parse(self,response): 20 photo_list = json.loads(response.text) 21 item = Bole_mode() 22 for image in photo_list.get("list"): 23 item["id"] = image["id"] 24 item["url"] = image["qhimg_url"] 25 item["title"] = image["group_title"] 26 item["thumb"] = image["qhimg_thumb_url"] 27 yield item
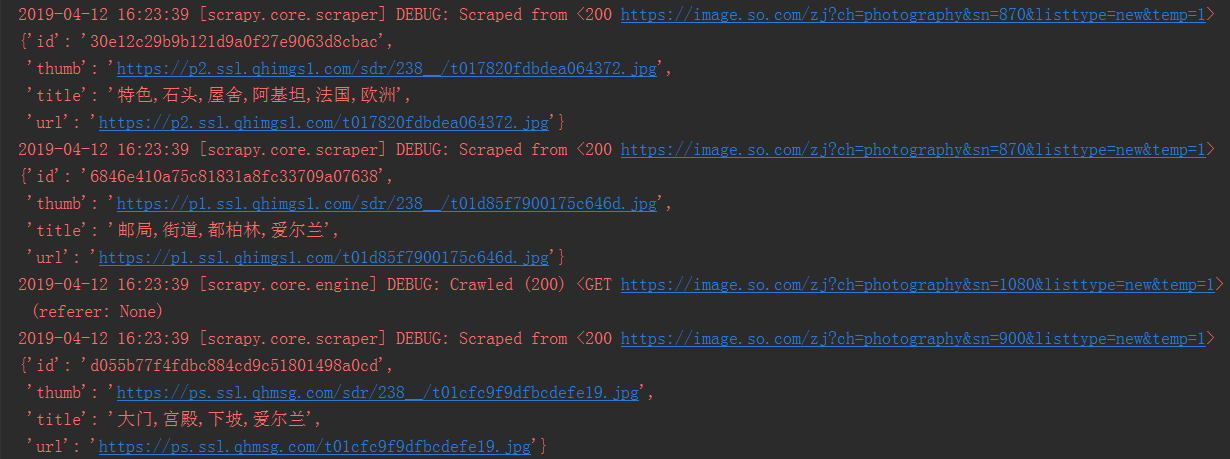
运行结果如下,可以看到每个url都已经请求成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号