

小刘的深度学习---Faster RCNN
前言:
对于目标检测Faster RCNN有着广泛的应用,其性能更是远超传统的方法。
正文:
R-CNN(第一个成功在目标检测上应用的深度学习的算法)
从名字上可以看出R-CNN是 Faster RCNN 的基础。正是通过不断的改进才有了后面的Fast RCNN 和 Faster RCNN。
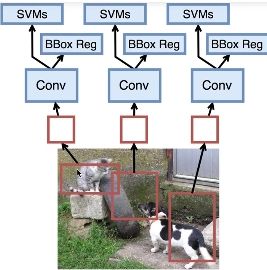
R-CNN的流程可以分为4个步骤: 用SS(Sekective Search) 找候选区域 >>> CNN提取特征 >>> 用提取的特征训练SVM中做物体识别 >>> 用提取的特征训练回归器提议区域
Sekective Search(选择性搜索)是一种基于区域的目标检测方法。先将图像划分成很多尺寸不同的区域(满足目标多尺寸要求),再将这些区域的层次聚类。其中的相似度计算包含4个方面:颜色,纹理,尺寸和空间交叠
颜色相似度是转HSV,每个通道以bins=25计算直方图,再除以区域尺寸做归一化
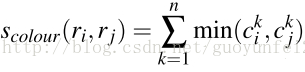
纹理相似度采用方差为1的高斯分布在8个方向上做梯度统计,以bins=10计算直方图

尺寸相似度

空间交叠相似度

最终的相似度

点击查看 CNN 部分
点击查看 SVM 部分
以上是R-CNN的基本流程,但是由于一张图可能会生成大约2千个候选区域,导致它运行的非常的慢。
Fast R-CNN(R-CNN的续作)
考虑到R-CNN中候选区域会有许多重叠部分,这里会先抽取特征再用SS选区域。并且会用softmax代替SVM。

其中的Rol Pooling 类似于Max Pooling ,它是将一个区域划分为几个小区域后再进行Max Pooling
但由于其本身还是沿用的SS,通常速度还是很慢。
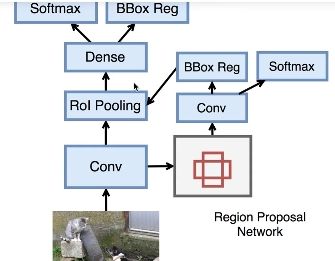
Faster R-CNN
通过用区域提议网络来提速。这里不再直接寻找目标在哪里,而是将问题分为锚点是否包含目标和如何将锚框更好的拟合目标。
以每个像素点为中心生成几种固定尺寸的锚框
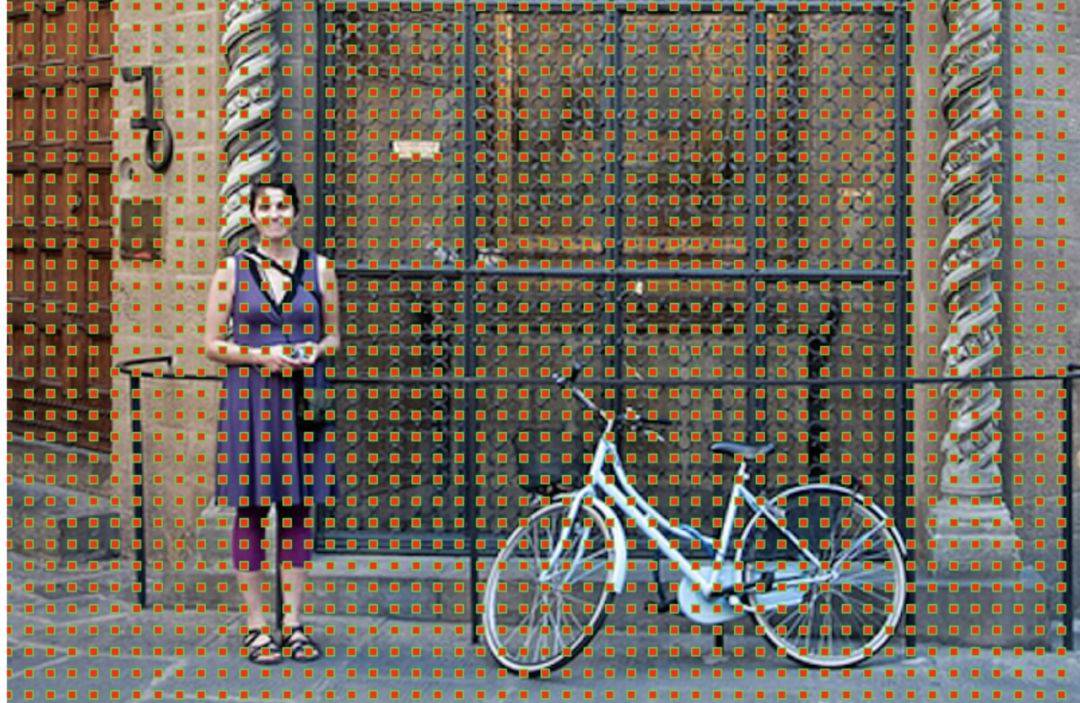

具体来说,先做3x3的卷积得到一个与公共尺寸相同的特征图(256x(HxW),再通过1x1的卷积得到2个输出,分别用于BBox 和用于区分前景与背景的softmax 。
往后的步骤与Fast RCNN相同。
放一张效果图

具体代码可以去GitHub上查看。
续:
因为最近在追妹纸,关于代码详解可能要等些时日了。just do it♥

