kafka 副本机制和容错处理 -2
文章来源于本人的印象笔记,如出现格式问题可访问该链接查看原文
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
副本机制
Kafka的副本机制会在多个服务端节点上对每个主题分区的日志进行复制,当集群中的某个节点上出现故障时,访问故障节点的请求会被转移到其他正常节点的副本上,副本的单位是主题的分区;
kafka每个主题的每个分区都会有一个主副本(Leader)以及0个或多个备份副本(Follower),主副本负责客户端的读和写,备份副本则负责向主副本拉取数据,以便和主副本的数据同步,当主副本挂掉后,kafka会在备份副本中选择一个作为主副本,继续为客户端提供读写服务;

分区的主副本应该均匀的分布在各个服务器上,如上图所示,通常主题分区的数量要比服务器的数量多很多,所以每个服务器都可以成为一些分区的主副本,也能同时成为一些分区的备份副本;
备份副本始终尽量保持与主副本的数据同步,备份副本的日志文件和主副本的日志总是相同的,它们都有相同的偏移量和相同顺序的消息。
容错处理
分布式系统处理故障容错时,需要明确的定义节点是否处于存活状态,kafka对节点的存活定义有如下两个条件
- 节点必须和ZK保持会话
- 如果这个节点是某个分区的备份副本,他必须对分区主副本的写操作进行复制,并且复制的进度不能落后太多
满足上述两个条件,叫做(in - sync)正在同步中,每个分区的主副本会跟踪正在同步中的备份副本节点(In Sync Replicas 即ISR ),如果一个备份副本挂掉,没有响应或者同步进度落户太多,主副本就会将其从同步副本集合中移除,反之,如果备份副本重新赶上主副本,它就会加入到主副本的同步集合中;(这个主副本的同步集合,包含主副本自己以及主副本保持一定同步的备份副本 则统称为ISR)
在Kafka 中,一条消息只有被ISR集合的所有副本都运用到本地的日志文件,才会认为消息被成功
提交了, 任何时刻,只要ISR至少有一个副本是存活的, Kafka就可以保证“一条消息一旦被提交,就不会丢失” 只有已经提交的消息才能被消费者消费,因此消费者不用担心会看到因为主副本失败而
丢失的消息;
对于生产者所发送的一条消息已经写入到主副本中,但是此时备份副本还没来及进行数据copy时,主副本就挂掉的情况,那么此时消息就不算写入成功,生产者会重新发送该消息,当所发送的一条消息成功的复制到ISR的所有副本后,它们才会被认为是提交的,此时才对消费者是可见的。
服务验证
验证kafka的服务副本机制和容错处理。
验证kafka的副本机制,只需部署一台测试用kafka即可,验证kafka的容错处理,及服务节点down机后的处理方式,则需要最低3个服务搭建kafka集群进行模拟;
单节点验证
先官网下载一个kafka,也可以在此处网盘直接下载
链接:https://pan.baidu.com/s/1_tmQA1AqTgh4T81HuW8OlA
提取码:zc1q
修改config目录下server.properties内容的基本信息,此处修改内容如下
broker.id=1
listeners=PLAINTEXT://10.0.3.17:9092
log.dirs=/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp
zookeeper.connect=10.0.3.17:2181
zookeeper.properties内容保持不变,然后启动kafka默认自带的zk服务,以及kafka服务即可;
启动zk
./zookeeper-server-start.sh -daemon /opt/gangtise/kafka/kafka_2.11-2.1.0/config/zookeeper.properties
启动kafka
./kafka-server-start.sh -daemon /opt/gangtise/kafka/kafka_2.11-2.1.0/config/server.properties
新建一个只有一个副本一个分区的topic主题
[root@dev bin]# ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic arnold_test
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "arnold_test".
此时在我们所配置的tmp文件夹下则对应新建了一个相同topic名称的日志文件,由于我们此时新建
arnold_test topic时只指定创建了一个分区,所以该日志目录下只创建了一个分区文件夹;索引位为0;
除此之外,还可以看到在我们所产生的分区文件同级别的目录下,存在如下4个 checkpoint结尾的文件,其中 replication-offset-checkpoint(复制偏移检查点) 记录对应的各主题分区的偏移量;recovery-point-offset-checkpoint(恢复点偏移检查点) 记录对应的各主题分区的恢复点的偏移量;做个标记,后续给详细的说明
[root@dev kakfa_tmp]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp
[root@dev kakfa_tmp]# ll
total 16
drwxr-xr-x. 2 root root 141 Nov 25 17:21 arnold_test-0
-rw-r--r--. 1 root root 0 Nov 25 17:12 cleaner-offset-checkpoint
-rw-r--r--. 1 root root 4 Nov 25 17:24 log-start-offset-checkpoint
-rw-r--r--. 1 root root 54 Nov 25 17:12 meta.properties
-rw-r--r--. 1 root root 20 Nov 25 17:24 recovery-point-offset-checkpoint
-rw-r--r--. 1 root root 20 Nov 25 17:24 replication-offset-checkpoint
查看arnold_test-0这个分区下的内容如下,其中 .log 结尾的文件则是二进制的日志文件,该日志文件中所存储的内容则是我们通过kafka生产者向这个topic中所输入的消息内容;可以使用 string 命令查看该二进制文件的内容。
[root@dev arnold_test-0]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp/arnold_test-0
[root@dev arnold_test-0]# ll
total 4
-rw-r--r--. 1 root root 10485760 Nov 25 17:21 00000000000000000000.index
-rw-r--r--. 1 root root 0 Nov 25 17:21 00000000000000000000.log
-rw-r--r--. 1 root root 10485756 Nov 25 17:21 00000000000000000000.timeindex
-rw-r--r--. 1 root root 8 Nov 25 17:21 leader-epoch-checkpoint
再新建一个只有一个副本三个分区的topic主题
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic arnold_test_many
查看日志分区文件如下
[root@dev kakfa_tmp]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp
[root@dev kakfa_tmp]# ll
total 16
drwxr-xr-x. 2 root root 141 Nov 25 17:21 arnold_test-0
drwxr-xr-x. 2 root root 141 Nov 25 19:18 arnold_test_many-0
drwxr-xr-x. 2 root root 141 Nov 25 19:18 arnold_test_many-1
drwxr-xr-x. 2 root root 141 Nov 25 19:18 arnold_test_many-2
-rw-r--r--. 1 root root 0 Nov 25 17:12 cleaner-offset-checkpoint
-rw-r--r--. 1 root root 4 Nov 25 19:19 log-start-offset-checkpoint
-rw-r--r--. 1 root root 54 Nov 25 17:12 meta.properties
-rw-r--r--. 1 root root 83 Nov 25 19:19 recovery-point-offset-checkpoint
-rw-r--r--. 1 root root 83 Nov 25 19:20 replication-offset-checkpoint
使用console 生产者,向arnold_test_many topic生产6条数据,可以看到此时我们生成6条content内容,按照我们上一章的说法,由于我们没有使用key值的方式进行存储,而是直接存储的内容,那么此时所产生的6条内容,则会按照轮训的方式依次插入对应的分区中。
[root@dev bin]# ./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_test_many
>message1
>message2
>message3
>message4
>message5
>message6
此时我们直接查看kafka分区偏移量记录的文件,可以看到arnold_test_many 0,arnold_test_many 1,arnold_test_many 2 所对应的分区 所对应的偏移量都是2,因为我们此时插入了6条数据,轮训均衡的插入到了3个分区中,所以各个分区中的检查点偏移量都为2。
[root@dev kakfa_tmp]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp
[root@dev kakfa_tmp]# cat replication-offset-checkpoint
0
4
arnold_test_many 2 2
arnold_test_many 1 2
arnold_test 0 0
arnold_test_many 0 2
此时我们使用strings 直接查看各分区中所存储的日志内容
[root@dev arnold_test_many-0]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp/arnold_test_many-0
[root@dev arnold_test_many-0]# strings 00000000000000000000.log
message2
message5
[root@dev arnold_test_many-1]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp/arnold_test_many-1
[root@dev arnold_test_many-1]# strings 00000000000000000000.log
message1
message4
[root@dev arnold_test_many-2]# pwd
/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp/arnold_test_many-2
[root@dev arnold_test_many-2]# strings 00000000000000000000.log
message3
message6
如上所示,数据采用轮训的方式均匀的插入到了各个分区中,整理后结果如下所示。
arnold_test_many1 arnold_test_many0 arnold_test_many2
message1 message2 message3
message4 message5 message6
此时可能你会有如此疑问,为什么数据的轮训不是从 arnold_test_many0开始轮训插入的,而是从arnold_test_many1开始的?这个我还没做严格测试,所以不排除轮训的起始分区的确是随机的,至少并不是按照分区的下标来确定顺序的。不过该topic的分区的顺序只要第一次插入数据确定后,后续就都将按照这个顺序执行,所以,起始分区的确也不是最重要的问题了。
此时我们使用消费者来消费该topic下的所有分区内的数据,可以看到消费者消费kafka中的数据时,并没有按照生产者的插入顺序来读取出来;这也验证了我们上一章的说法,kafka并不保证当前topic的全局消息顺序,而只是保证当前该topic下各分区的消息顺序,也就是我们看到的 分区arnold_test_many2中的message3消息一定在message6前面,分区 arnold_test_many1中的 message1肯定在message4前面;
[root@dev bin]# ./kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092 --from-beginning --topic arnold_test_many
message3
message6
message1
message4
message2
message5
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
分布式模式验证
直接将我们kafka的部署包,分别cp到不同的机器上,然后修改对应的配置,启动即可,主要配置内容如下
10.0.3.17
broker.id=1
listeners=PLAINTEXT://10.0.3.17:9092
log.dirs=/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kakfa_tmp
zookeeper.connect=10.0.3.17:2181
10.0.6.39
broker.id=2
listeners=PLAINTEXT://10.0.3.17:9092
log.dirs=/home/gangtise/kafka/kafka_2.11-2.1.0/logs/kafka_tmp
zookeeper.connect=10.0.3.17:2181
10.0.3.18
broker.id=3
listeners=PLAINTEXT://10.0.3.18:9092
log.dirs=/opt/gangtise/kafka/kafka_2.11-2.1.0/logs/kafka_tmp
zookeeper.connect=10.0.3.17:2181
启动对应的kafka节点后,通过zk的图形化工具查看当前的kafka注册信息,可以看到对应的kafka节点信息都已经注册到zk上,此时表明部署完成;(由于此处主要是验证下kafka集群的特性,所以zk的节点则只部署了一个,测试用即可)
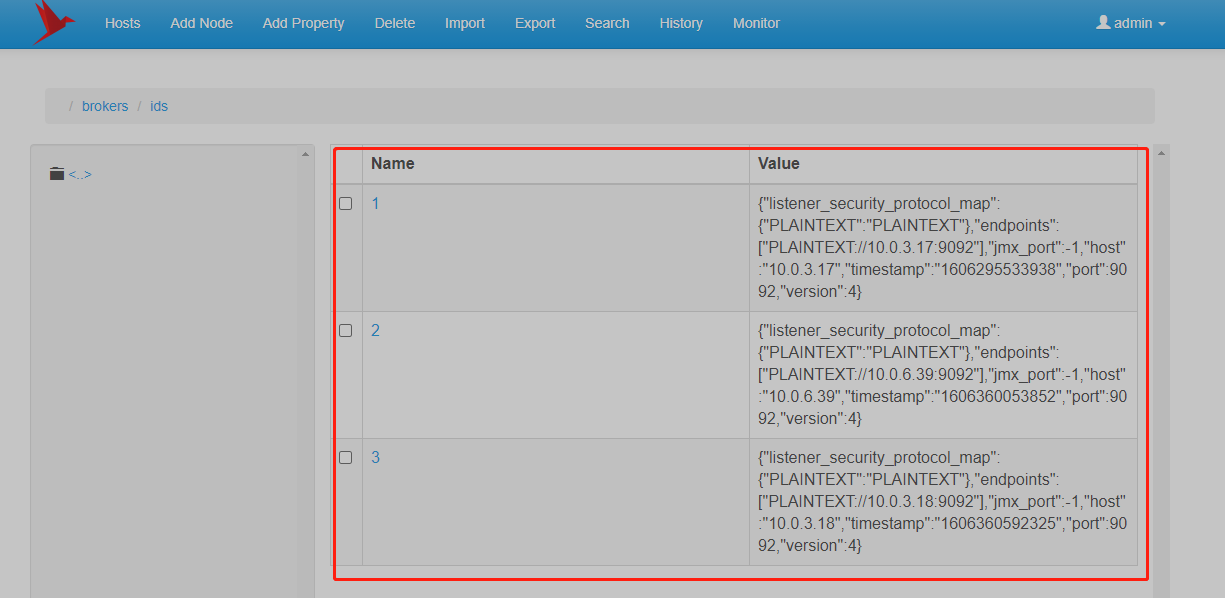
新建Topic
由于我们此时已经有了3个服务器节点,对应的服务器broker.id分别为:1,2,3;
此时我们创建一个新的Topic,指定该Topic为三个副本,三个分区,如下:--replication-factor 3 表示创建对应的副本数为3, --partitions 3 表示创建对应的分区数为3
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic arnold_test_many_three
使用--describe命令查看该topic的详细信息
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_test_many_three
Topic:arnold_test_many_three PartitionCount:3 ReplicationFactor:3 Configs:
Topic: arnold_test_many_three Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: arnold_test_many_three Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: arnold_test_many_three Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
上述查询结果详细解释一下,如下:
第一行含义是:
Topic arnold_test_many_three 一共有三个分区(PartitionCount:3),三个副本(ReplicationFactor:3),对应的配置的具体信息,则是看下方的详情(Config)
第二行含义是:
Topic arnold_test_many_three 的第0个分区(Partition: 0),对应的主副本Leader节点是3(Leader: 3),该0分区对应的副本分别是在3,1,2节点上存储(Replicas: 3,1,2),其中当前的ISR信息分别是3,1,2(Isr: 3,1,2);
那么对应的第三行的含义则也是与第二行相似,表示当前的 Partition 1分区的三个副本,分别是在broker.id 为1,2,3的三个服务节点上存储,其中主副本Leader副本则是broker.id为1的服务器上的副本,则是主副本;当前该分区的同步信息 isr 是1,2,3,表示所有节点均同步正常;
ISR表示正在同步的节点集合,详细解释,可以看上述容错处理中的内容解释;
手动停止节点
此时我们将broker.id为2的节点服务停止掉,再观察下当前的副本情况;
直接使用kill -9 强制进程退出的方式;
[gangtise@yinhua-ca000003 arnold_test_many_three-0]$ kill -9 94130
此时再观察对应的topic的详细信息
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_test_many_three
Topic:arnold_test_many_three PartitionCount:3 ReplicationFactor:3 Configs:
Topic: arnold_test_many_three Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1
Topic: arnold_test_many_three Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,3
Topic: arnold_test_many_three Partition: 2 Leader: 3 Replicas: 2,3,1 Isr: 3,1
可以看到,分区的主副本已经进行了转移,原先的Partition 2 分区的,Leader节点由原来的2,变更为了现在的3;
也就是说当前的Partition2分区的Leader节点主副本任务由原来的2服务器节点,变更成了由服务器节点3来接管Partition2分区的主副本任务;
另外则是,所有的Replicas 副节点的信息,是没有变化的,还是和以前的一摸一样,毕竟2节点只是down机,修复好以后还是要重新承担副本的任务的;
虽然每个分区的Replicas没有变化,但是每个分区的ISR中不再包含 2节点;(也就是说,后续的消息的同步集合中,只需要1,3节点同步完成,则同步完成,便会直接给生产者返回一个消息,OK同步完成;而2节点,等到后续节点修复后,主动copy其他分区的副本内容到自身的节点上,等到进度完全和其它节点保持一致后,则重新加入到ISR同步集合中。)
那么此时,我们再重新启动下 2节点;
[gangtise@yinhua-ca000003 kafka_2.11-2.1.0]$ ./bin/kafka-server-start.sh -daemon /home/gangtise/kafka/kafka_2.11-2.1.0/config/server.properties
然后再重新查看当前Topic的详细信息,啪一下啊,很快啊,可以看到ISR中的同步集合中,2节点也已经正常回归;
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_test_many_three
Topic:arnold_test_many_three PartitionCount:3 ReplicationFactor:3 Configs:
Topic: arnold_test_many_three Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: arnold_test_many_three Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
Topic: arnold_test_many_three Partition: 2 Leader: 3 Replicas: 2,3,1 Isr: 3,1,2
如上,可以看到,此时的ISR中已经包含了2节点;但是,观察上面结果可以看到,Partition0分区和Partition2分区的主节点都还是在 3服务器节点上,也就是当前该两个分区都过于依赖3服务器的主副本节点,而主副本节点又要负责消息的读写的任务,所以3服务节点,压力较大,此时通过执行平衡操作,来解决分区主节点的问题
执行自平衡
[root@dev bin]# ./kafka-preferred-replica-election.sh --zookeeper 10.0.3.17:2181
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic arnold_test_many_three
Topic:arnold_test_many_three PartitionCount:3 ReplicationFactor:3 Configs:
Topic: arnold_test_many_three Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: arnold_test_many_three Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,3,2
Topic: arnold_test_many_three Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 3,1,2
Partition2的副本集[2,3,1],原有的Leader编号是3,通过执行上述平衡操作后,分区2的主副本节点由原有3,迁移到了节点2。
不过,如果在服务down机后,不手动执行平衡操作的情况下,那么过一段时间,kafka会自动进行一下平衡,只要新上来的服务是稳定的情况下,kafka会自动将主副本平衡到新的节点上;
命令汇总
上述所使用到的几个命令汇总
启动zk
./zookeeper-server-start.sh -daemon /opt/gangtise/kafka/kafka_2.11-2.1.0/config/zookeeper.properties
启动kafka
./kafka-server-start.sh -daemon /opt/gangtise/kafka/kafka_2.11-2.1.0/config/server.properties
创建Topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic arnold_test_many
生产者
./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_test_many
消费者
./kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092 --from-beginning --topic arnold_test_many
查看Topic详细信息(包含节点的分布情况)
./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_test_many_three
分区自平衡
./kafka-preferred-replica-election.sh --zookeeper 10.0.3.17:2181

 浙公网安备 33010602011771号
浙公网安备 33010602011771号