RPA剖析浏览器API(获取指定页面数据)
本次内容主要是讲解如果剥离微软Power Automate Desktop控制浏览器得部分API,
通过剥离其API, 用于集成在自身的软件业务当中, 实现控制浏览器及获取相关数据得实现。
分析
PAD本身也是一个基于WPF开发的客户端应用程序, 本质上来讲它也无非是使用C#的类库来实现其功能, 那么只要找到对应API的位置以及实现方法,
我们即可将其实现集成在自己的软件当中。为了能够找到对应的API, 需要分析几个部分, 一个是调用DLL的文件位置,另外一个是PAD当中的参数传递部分。
查找DLL
在PAD当中,控制浏览器的部分归属在Web自动化下,如下所示:

那么找到对应的DLL其实也很简单, 与Web相关的有两个值得注意的文件,如下所示:

但是现在还不够, 你不太确定他具体调用了哪个方法,这个时候,我们就可以在PAD当中查看文档, 找到具体调用的方法。
首先,我们尝试查找获取浏览器数据的功能,查看对应的文档,可以注意到浏览器结尾给我们留下来了一点讯息:
https://docs.microsoft.com/zh-cn/power-automate/desktop-flows/actions-reference/webautomation#getdetailsofwebpage
通过 getdetailsofwebpage去搜索到对应的方法,不出意外,找到了,如下所示:

到了这一步, 我们就得动用反编译软件了, 因为要把具体的实现剥离出来,就得分析对应的代码结构。
反编译查找
通过反编译软件, 找到了对应的方法实现, 可以看到继承了一个ActionBase。
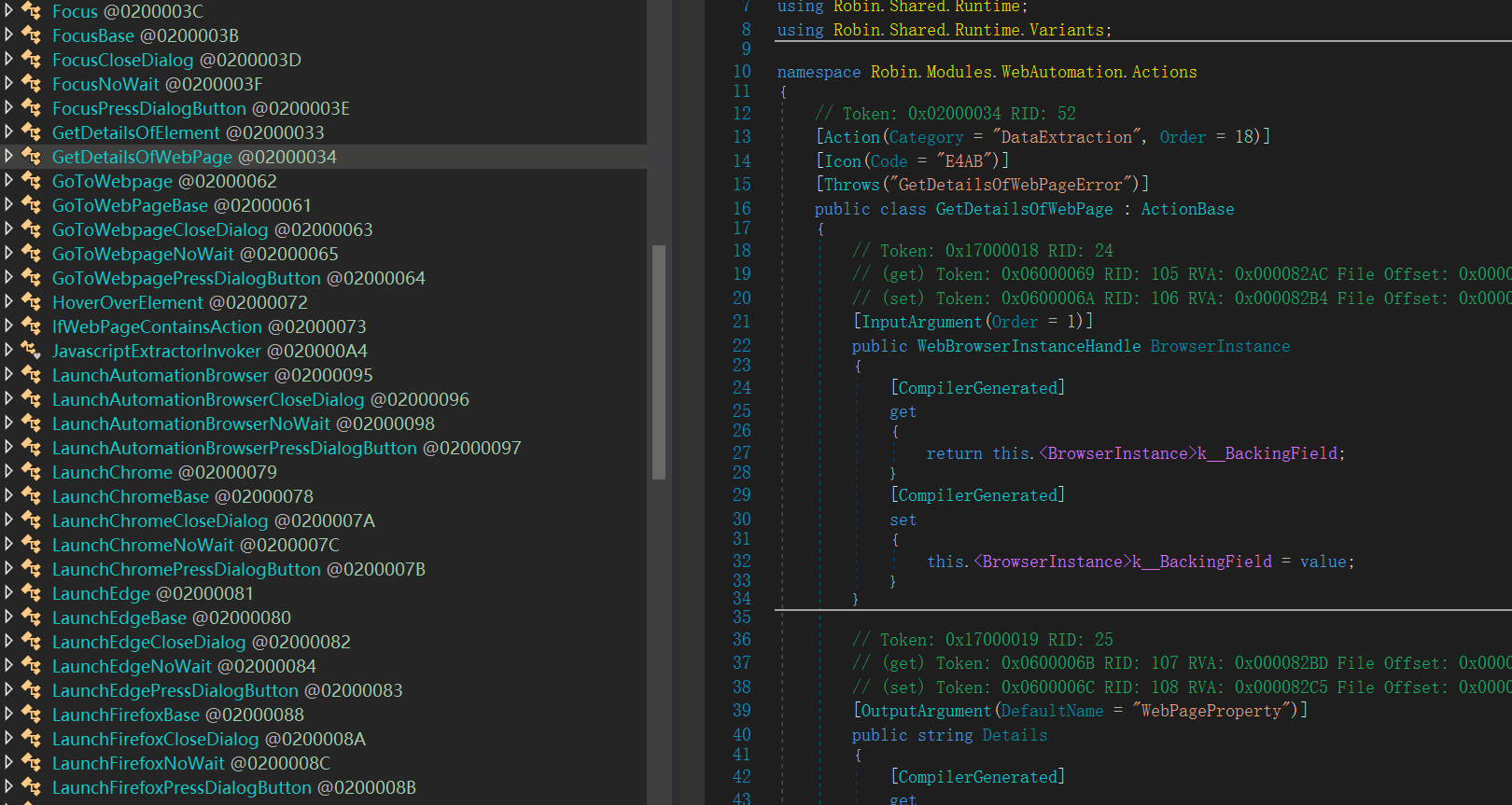
那既然是ActionBase, 说明可能具体的操作还不是在这里, 而是在其他的地方, 可以注意到该功能是在Web数据提取下面。
那么是不是对应的会有一个数据提取的类, 他间接继承于ActionBse?
不出意外,看到了一个用于数据提取的类,如下所示:
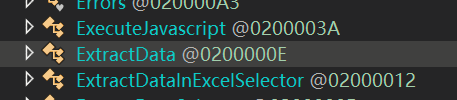
如何判断就是它呢?这个时候就需要用PAD来进行校验, 看看PAD当中的输入参数是否能与该类一致,只要能对上, 说明就是它。
代码实现
通过PAD的可视化界面, 可以发现对应的参数都有,那么我们尝试自己写一个类来模拟该功能。
ExtractData 类中包含一下重要参数:
- BrowserInstance: 浏览器实例
- StoreDataMode : 数据存储模式
- ExtractionMode: 提取数据类型
- ExtractionParameters: 传入的提取参数
- Control: 设置CSS选择器
示例代码,即如下所示:
ExtractData extractData = new ExtractData();
extractData.BrowserInstance = edgeBase.BrowserInstance;
extractData.StoreDataMode = Robin.Modules.WebAutomation.Actions
.Enums.StoreDataMode.Variable;
extractData.ExtractionMode = Robin.Modules.WebAutomation
.Actions.Enums.ExtractionMode.Table;
extractData.ExtractionParameters = table;
extractData.Control = new Robin.Core.Types.WebControl()
{ };
有了这些代码之后, 我们就差一个示范了, 我们模拟获取网页的列表数据,看看是否可行。
开始动手
有了基本的思路之后,我们开始分步骤:
1.创建一个浏览器实例,打开测试的网页
2.设置ExtractData
3.执行Execute
4.获取ExtractedData
具体代码如下所示:
LaunchEdgeBase edgeBase = new LaunchEdgeBase();
edgeBase.LaunchMode = Robin.Modules.WebAutomation.Actions.Enums.LaunchMode.LaunchNew;
edgeBase.Url = "https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.21814703.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E6%89%8B%E6%9C%BA%E5%A3%B3&suggest=0_1&_input_charset=utf-8&wq=shouji&suggest_query=shouji&source=suggest";
edgeBase.WaitForPageToLoad = true;
edgeBase.WindowState = Robin.Modules.WebAutomation.Actions.Enums.BrowserWindowState.Maximized;
edgeBase.Execute(null);
DataTable table = new DataTable();
table.Columns.Add("cssSelector");
table.Columns.Add("attribute");
table.Columns.Add("regex");
table.Columns.Add("columnName");
table.Rows.Add("div:eq(1) > div:eq(1) > a", "Own Text", null, "value1");
table.Rows.Add("div:eq(1) > div:eq(2) > div:eq(0) > a > span:eq(1)", "Own Text", null, "value2");
ExtractData extractData = new ExtractData();
extractData.BrowserInstance = edgeBase.BrowserInstance;
extractData.StoreDataMode = Robin.Modules.WebAutomation.Actions
.Enums.StoreDataMode.Variable;
extractData.MaxWebPagesToProcess = 1;
extractData.ExtractionMode = Robin.Modules.WebAutomation
.Actions.Enums.ExtractionMode.Table;
extractData.ExtractionParameters = table;
extractData.Control = new Robin.Core.Types.WebControl()
{
Selector = "html > body > div:eq(0) > div:eq(1) > div:eq(2) > div:eq(0) > div:eq(20) > div > div > div:eq(0) > div"
};
extractData.Execute(null);
table = extractData.ExtractedData;

