基础数据类型
一、基础数据类型操作
1、数字 int
数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以:
int.bit_length() -> int Number of bits necessary to represent self in binary. >>> bin(37) '0b100101' >>> (37).bit_length() 6
2、布尔值
布尔值就两种:True,False。就是反应条件的正确与否。
真 1 True。
假 0 False。
#各种类型相互转换操作 int --> str :str(int) #int转换str str --> int :int(str) #str转化int str必须全是整数 int --> bool #int转换为bool 0 false 非零True bool--> int #bool转换为int, True为1, false为0 str --> bool("") #s空字符转字符串 str --> bool(" ") #空格转字符串, 非空字符串返回True
3、字符串str
3.1、字符串的索引及切片
索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。
s = 'python自动化运维21期' s1 = s[0] print(s1) s3 = s[-1] #取倒一
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(原则就是顾头不顾腚)。
s2 = s[:] #取全部 s4 = s[-1:-5:-1] #反向取 s5 = s[-5:0:-2]
3.2、字符串常用方法
#center # S.center(width[, fillchar]) -> str #fill character (default is a space) s = 'oldboY老男孩' s1 = s.center(30,'*') print(s1) #onput:**********oldboY老男孩*********** #capitalize 首字母大写,其他字母小写 #S.capitalize() -> str s = 'oldBoy' s1 = s.capitalize() #首字母大写,其他字母小写 print(s1) #onput:Oldboy #upper lowser #S.upper() -> str #S converted to uppercase. #S.lower() -> str #string S converted to lowercase. s2 = s.upper() #全部大写 print(s2) s3 = s.lower() #全部小写 print(s3) #output: OLDBOY oldboy #swapcase #S.swapcase() -> str s4 = s.swapcase() #大小写翻转 print(s4) #output:OLDbOY #title # S.title() -> str s = 'aelx*join&jinxing)fuck' s5 = s.title() print(s5) #output:Aelx*Join&Jinxing)Fuck #startswith,endswith 判断是否以该字符串开头和结尾 #S.startswith(prefix[, start[, end]]) -> bool #S.endswith(suffix[, start[, end]]) -> bool s7 = s.startswith('o') print(s7) s71 = s.startswith('ol') print(s71) s72 = s.startswith('l', 1) print(s72) s73 = s.startswith('o', 0) print(s73) s74 = s.startswith('l', 1, 2) #符合切片的顾头不顾尾 print(s74) s8 = s.endswith('y') #同startswith一样 print(s8) #strip,rstrip,lstrip #S.strip([chars]) -> str #默认去除左右的空格、换行符、制表符,可以自定义移除的字符 s = ' \toldbboy\n' print(s) s9 = s.strip() print(s9) s91 = s.strip(' \n \t olby') #默认是去除空格,可以自定义要去除的元素 print(s91) s92 = s.lstrip() s93 = s.rstrip() #split #S.split(sep=None, maxsplit=-1) -> list of strings #默认以空格分割字符串返回list,可以自定义分隔符和分割次数 s = 'oldboy,wusire.alex' s10 = s.split() print(s10) s101 = s.split('.') print(s101) #output: ['oldboy,wusire.alex'] ['oldboy,wusire', 'alex'] #join #join可以操作list 字典,元组,可迭代的对象都可以
#列表可以转换为字符串 #S.join(iterable) -> str s = 'oldboy' l = ['alex', 'taibai', 'nan'] s11 = '+'.join(s) print(s11) s111 = ','.join(l) #列表中是非字符串元素的话会报错, print(s111) #output: o+l+d+b+o+y alex,taibai,nan #replace #S.replace(old, new[, count]) -> str s12 = s.replace('oldbou', 'oldboy', 1) print(s12) #output:alex,oldboy,taibai,oldbou #find index #通过元素找到索引 S.find(sub[, start[, end]]) -> int S.index(sub[, start[, end]]) -> int print(s.find('o')) print(s.index('o'))
#output: 5 5 #公共方法:len count print(len(s)) print(s.count('o'))
#output: 25 4 #is系列 S.isalnum() -> bool S.isalpha() -> bool S.isdigit() -> bool print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isdigit()) #字符串只由数字组成
3.3、format格式化输出
#格式化输出format res = '我叫{} 今年{}岁,爱好{}'.format('alex', 30, 'nan') print(res) res = '我叫{0} 今年{1}岁,爱好{0}'.format('alex', 30, 'nan') print(res) res = '我叫{name} 今年{age}岁,爱好{hobby}'.format(name= 'alex', age = 30, hobby = 'nan') print(res) #output: 我叫alex 今年30岁,爱好nan 我叫alex 今年30岁,爱好alex 我叫alex 今年30岁,爱好nan
4、列表list
list:存储大量数据,列表是有序的,有索引值,可切片,方便取值。
4.1、增


#append #L.append(object) -> None -- append object to end l = ['oldboy', 'alex', 'taibai'] l.append('nvshne') l.append([1,2,3]) print(l) #insert #L.insert(index, object) -- insert object before index l.insert(1, 'dc') print(l) #迭代增加 #L.extend(iterable) -> None -- extend list by appending elements from the iterable l.extend('alex') print(l) #output: ['oldboy', 'alex', 'taibai', 'nvshne', [1, 2, 3]] ['oldboy', 'dc', 'alex', 'taibai', 'nvshne', [1, 2, 3]] ['oldboy', 'dc', 'alex', 'taibai', 'nvshne', [1, 2, 3], 'a', 'l', 'e', 'x']
4.2、删
#pop 增删改查唯一有返回值的方法 #L.pop([index]) -> item -- remove and return item at index (default last).Raises IndexError if list is empty or index is out of range. l.pop(0) print(l) print(l.pop()) #remove 按照元素去删除 #L.remove(value) -> None -- remove first occurrence of value. #Raises ValueError if the value is not present. print(l.remove('alex')) print(l) #clear 清空列表 #L.clear() -> None -- remove all items from L l.clear() print(l) #del 内存中删除列表 del l print(l) #按照索引/切片删除 del l[-1] print(l) del l[:] print(l) del l[0:2] print(l)
4.3、改
#改 只有两种方法 #按照索引改 print(l) l[0] = 'oldgirl' print(l) #按照切片改 l[:1] = 'abc' #迭代操作 print(l)
4.4、查
#按照索引,切片,for循环来查
4.5、公共方法
#公共方法 #len count #根据元素找到索引 # print(l.index('oldboy')) #排序sort # l.sort() #倒序 # print(l.sort(reverse=True)) # print(l)
5、字典dic
存储大量数据,关联型数据,查询速度快,符合二分查找
字典的key是唯一的,必须是不可变的数据类型(可哈希):str bool int tuple
value: 任意数据类型。
数据类型分类:
不可变的数据类型(可哈希)
可变的数据类型:list dict set
容器数据类型:list tuple dict set
5.1、增
dic = {'name': 'alex', "age": 20, 'hobby': 'girl' }
#增
dic['high'] = 180
print(dic)
#有则覆盖,无则添加
dic['name'] = 'ritian'
print(dic)
#有则不变,无则添加
""" D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """
dic.setdefault('high', 170)
print(dic)
5.2、删
#字典的所有操作都是通过key来操作value的 dic.pop('name') print(dic.pop('name1', "none")) #没有找到要删除的key,返回none,可以自定义 print(dic) dic.cler() #清空 del dic #内存中删除字典 print(dic) del dic['name'] #del也可以按照key来删除 print(dic) print(dic.popitem()) #随机删除
5.3、改
dic['name'] = 'oldboy' print(dic) dic1 = {'name': 'alex', "age": 20, 'hobby': 'girl' } dic2= {'name': 'jin', 'high': 150} dic1.update(dic2) #把dic2的内容更新到dic1中,有则覆盖,无则添加 #D.update([E, ]**F) -> None. Update D from dict/iterable E and F. print(dic1)
5.4、查
print(dic['name']) #通过key查询,没有对应key的话会返回报错 dic.get('name') #这个查询较好,没有对应key不会报错
5.5字典的循环
# #keys() values() items() 可以通过list转换为列表,或者直接for循环取值 # print(dic.keys()) # print(dic.values()) # print(dic.items())
5.6 fromkeys创建字典
#value如果是list的话,list会指向一个地址 dic = dict.fromkeys(['alex', 'taibai', 'jinxing'], ['1', '2', '3']) print(dic) dic['alex'].append('4') print(dic)
6、元组 tuple
只限于子级别只读
([True,1, 'alex', {字典}, [], (), {集合}])
7、集合 set
关系型数据的交集,并集,差集,子集..列表去重
无序,不重复的数据类型,里面的元素是不可变(可哈希的)
集合本身是可变的,
1、关系测试,
2、去重(列表)
7.1、增
# set1 = {1, 'alex', '2'} # print(set1) # #增 # set1.add(2) # print(set1) # #update 迭代的增 # set1.update('456') # print(set1)
7.2、删
# #remove 按照元素删除 # set1.remove('2') # print(set1) # # #清空列表 # set1.clear() # # #内存删除 # del set1
7.3关系测试
# set1 = {1, 2, 3, 4, 5} # set2 = {4, 5, 6, 7, 8} # #交集 # print(set1 & set2) # print(set1.intersection(set2)) # # #并集 # print(set1 | set2) # print(set1.union(set2)) # # #差集 # print(set1 - set2) # print(set1.difference(set2)) # # #反交集 # print(set1 ^ set2) # # #子集和超集 # print(set1 > set2) # print(set1 < set2)
# #frozenset 构建一个不可变的集合 # s = frozenset('barry') # print(s)
8、数据类型的补充
8.1、删除奇数位对应的元素
l = ['taibai', 'barry', 'allan', 'oldboy', 'alex'] # del l[1:4:2] #最简单的方法,切片删除 # print(l) # for index in range(len(l)): 可以倒着删除操作,循环一个列表时候不要对列表进行删除及添加,会改变列表元素的索引 # print(l) # if index % 2 == 1: # print(l.pop(index)) # # print(l)
# for index in range(len(l)-1, -1, -1): #倒着往前删除
# # print(index)
# if index % 2 == 1:
# l.pop(index)
# print(l)
# for index in range( -len(l) , -1+1): #正着删除的话可以使用反向步长的方法
# # print(index)
# if index % 2 == 0:
# l.pop(index)
# print(l)
8.2、循环一个字典的时候不要改变字典的大小
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'alex': 666}
for i in dic:
if 'k' in i:
dic.pop(i)
print(dic)
#output:
RuntimeError: dictionary changed size during iteration
#可以把含k的key添加到list中,循环list删除字典
# l = [] # for i in dic: # if 'k' in i: # l.append(i) # for i in l: # dic.pop(i) # print(dic)
#如果元组里面只有一个元素,并且没有逗号隔开,他的元素类型与该元素一直
tu1 = (1) print(tu1, type(tu1)) tu2 = (1,) print(tu2, type(tu2)) #output: 1 <class 'int'> (1,) <class 'tuple'>
9、小数据池
# a = 'alex' # b = 'alex' # print(a==b) #比较数值 # print(a is b) #比较内存地址 # id打印内存地址,涉及到id的测试一定要在终端操作 # 小数据池只针对str 和int # int 范围 -5 ~ 256 在这个范围内相同的数全都指向一个内存地址(为了节省空间) # str 单个字符*int 不能超过21
10、编码
#编码
#python 字符串内存编码为(unicode) 计算机存储和传输需要以非unicode的编码,需要先转换为bytes存储或者传输
#bytes 类型
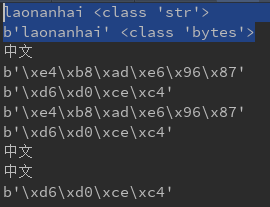
#对于英文 # s = 'laonanhai' #表现形式,内部编码方式unicode # print(s, type(s)) # # s = b'laonanhai' #内部编码形式为非unicode # print(s, type(s)) #对于中文 # s = '中文' # print(s) # print(s.encode('utf-8')) # print(s.encode('gbk')) # # #转换为bytes类型 # print(s.encode('utf-8')) #str-->bytes类型 encode编码 # print(s.encode('gbk')) # # #转换str类型 # s2 = b'\xd6\xd0\xce\xc4' #bytes-->str类型, decode解码 # print(s2.decode('gbk')) # print(b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')) # # # utf-8的bytes类型转换为gbk的bytes类型 # print(b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8').encode('gbk'))
输出: