
[NeurIPS2024]Breaking Long-Tailed Learning Bottlenecks A Controllable Paradigm with Hypernetwork-Generated Diverse Experts
这篇论文提出使用超网络生成专家模型的参数,实现可控的、能根据用户偏好预测的专家模型。
Related works
长尾学习(long-tailed learning)的方法包括重采样、设计损失函数,旨在提高尾部类的表现。然而,这类方法往往假设测试集是类别平衡的,在训练时的操作也是希望学到一个均衡预测分类的模型。这在实际场景中,并不能很好的处理训练和测试的域转移(domain shift)问题。
近几年,多专家的长尾学习被提出。在多专家网络中,共用一个特征提取器,用多个(一般是3个)线性层表示专家模型。专家网络有着较强的分布适应能力,因为不同的专家可以通过不同的损失函数学习不同分布的类别。大部分长尾多专家工作使用3个专家,分别是:
- 前向专家(the forward expert),模拟原始的长尾分布
- 均匀专家(the uniform expert),通过logit adjustment,用先验对数减少头部类的logits
- 后向专家(the backward expert ),使用逆softmax 损失(inverse softmax loss),通过逆先验的对数增加尾部类的logits
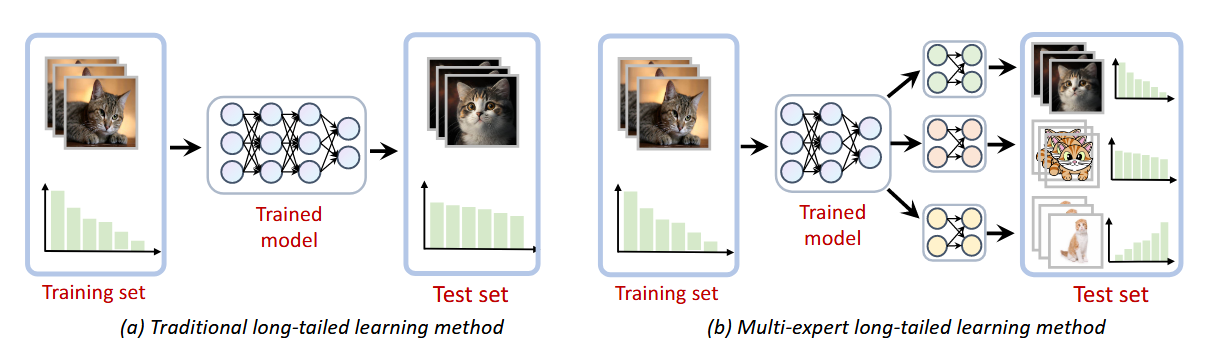
几个多专家长尾学习的代表工作
Long-tailed Recognition by Routing Diverse Distribution-Aware Experts. ICLR 2021
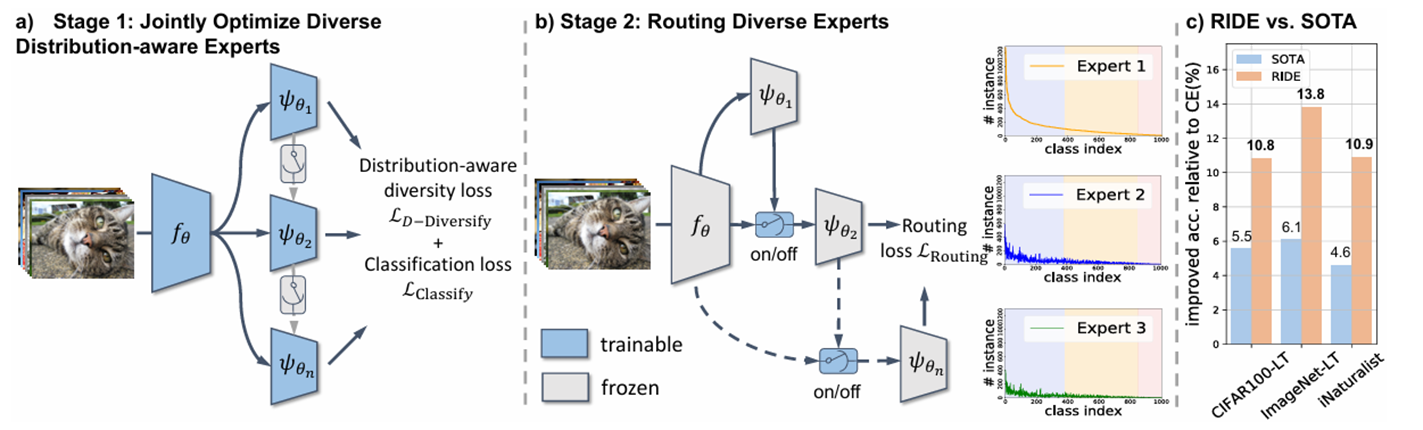
这篇文章提出了RIDE(Routing Diverse Distribution-Aware Experts),除了训练特征提取器和多专家,还在引入了2阶段训练,在2阶段训练上,训练了路由模块。模型会对难分类的样本动态地分配专家,头部类参与的专家少,尾部类参与的专家多。
Self-supervised aggregation of diverse experts for test-agnostic long-tailed recognition. NeuraIPS 2022
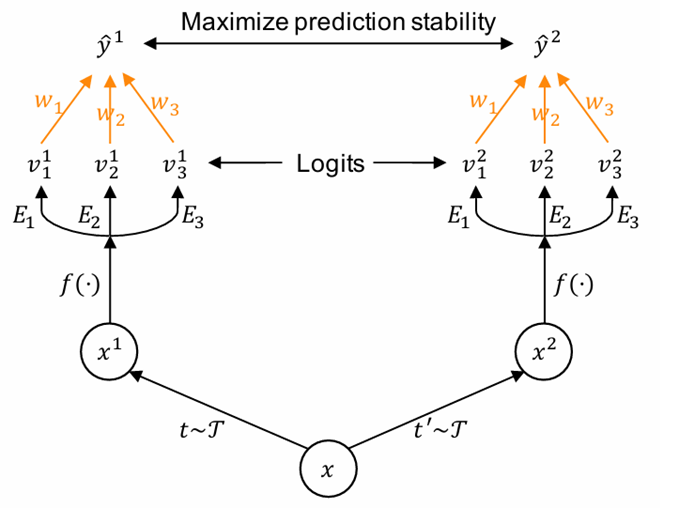
这篇文章提出了SADE(Self-supervised Aggregation of Diverse Experts)。作者基于假设和观察:专家对于在它们擅长的类别上,对于不同视角的样本应该有着稳定的预测结果,例如,尾部类专家对于使用不用图像增强的尾部类样本应该有着一致的预测结果。因此,就可以把测试集当成无标签数据,作自监督训练,更新参数
Introduction
本文中,作者指出,这些长尾的方法关注的是整体的分类性能表现。然而,在某些情况下,用户需要对头部类或尾部类有一定偏好。例如:
- 对于肺癌,大多数图片是正常图片,用户会愿意提高假阳率去实现对尾部类的召回,保证不会遗漏病患。
- 对于自然保护区,用户更关注主要物种,实现种群数量的准确统计。
在本文中,作者就提出一种可控的多专家长尾学习方法,它在单一的数据集上训练,并能根据用户偏好,在不同分布的测试集上进行分类。
一些简单的证明
对比单网络的长学习经验风险:
多专家长尾学习的经验风险可表示为:
其中
多专家长尾学习的经验风险有3项组成:
- 所有专家的平均经验风险
- 训练环境与测试环境之间的平均总变异距离。
- 训练环境之间的 ETVD 加权平均值。
多专家方法可以捕捉不同环境的分布特征,从而减少训练环境与测试环境之间的分布差异
Method
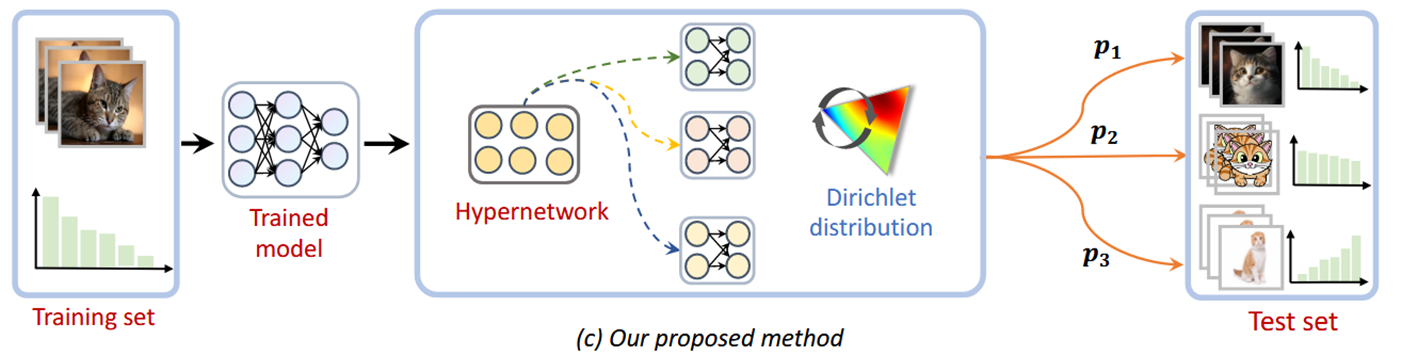
狄利克雷分布可以很好地对这种多类别比例的不确定性进行建模。它能够生成一组符合概率分布的主题比例向量,这些向量可以表示文本中各个主题的相对重要性。并且通过狄利克雷分布的性质,可以对文本的主题结构进行有效的学习和推断,发现文本集合中的潜在主题模式。
模型组成:
超网络的输入为
通过调整迪利克雷分布参数,可以生成不同的专家模型:
最后的损失函数表示为:
其中第二项是一个平滑切比雪夫标量化正则项,作者是直接使用了 “Smooth Tchebycheff scalarization for multi-objective optimization ICLR. 2024.
”的结论。
在测试阶段,噪声
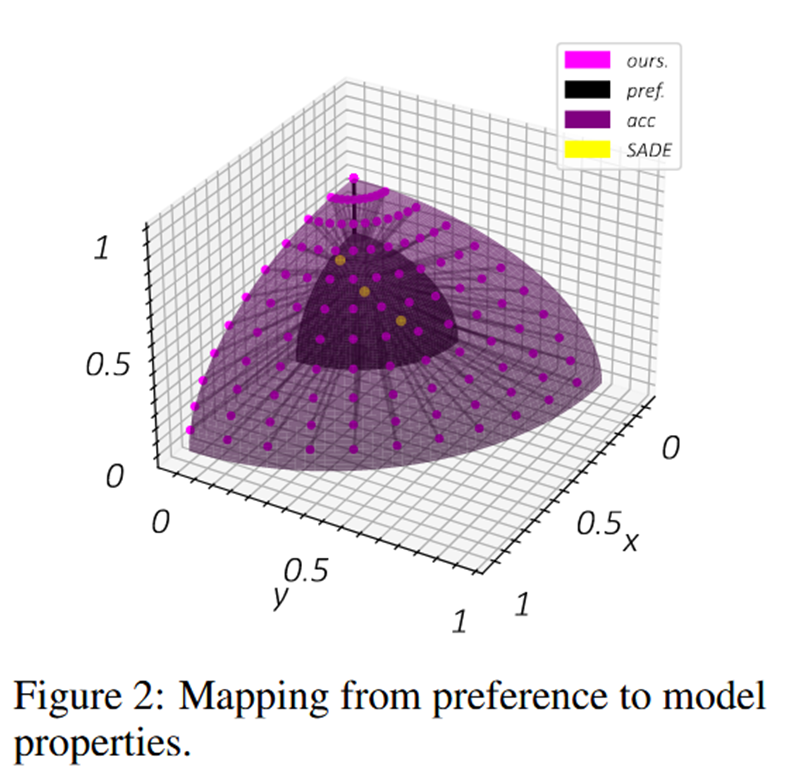
这张图中,坐标轴有两层意思,深色表示偏好向量的值空间;浅色表示不同分布下的分类准确率。作者可以通过偏好向量在不同分布下取得不同的偏好结果,所以可以到达平面任意点,而黄色的baseline只能局限于部分。
实验结果
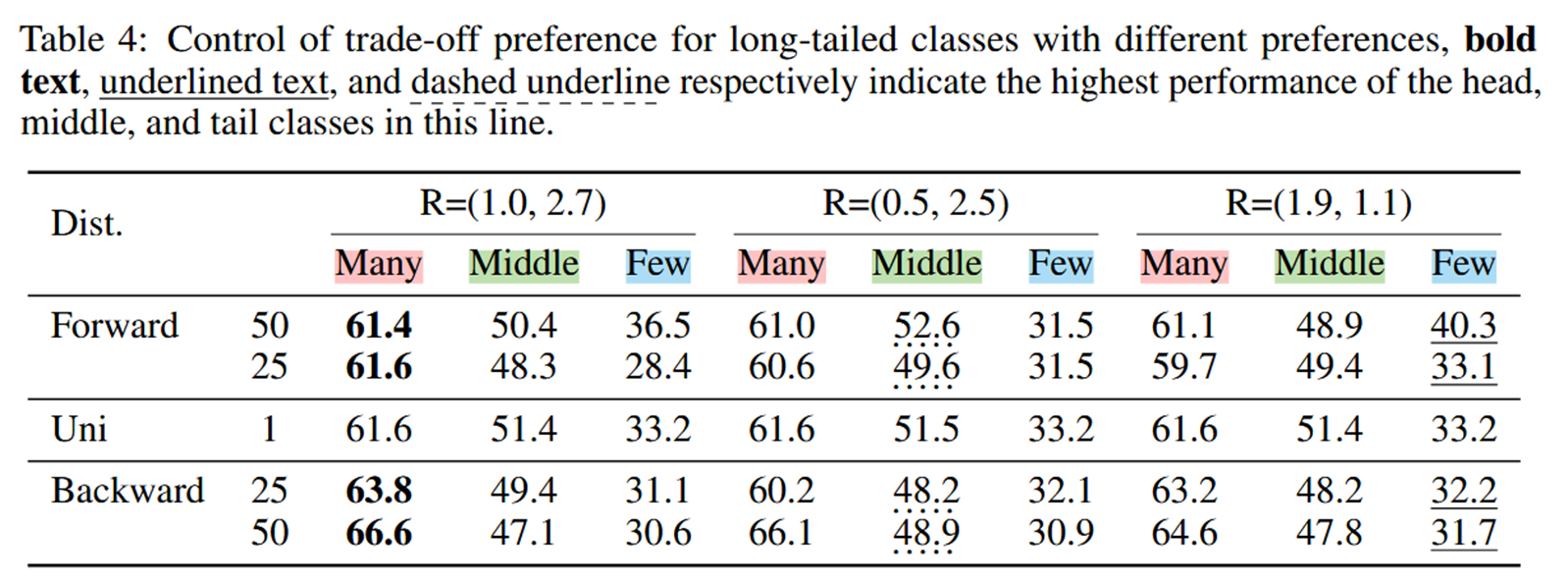
作者用极坐标R表示用户的偏好向量(不知道咋换算的),从结果上来看提升还是非常有限的
参考文献
- Xudong Wang, Long Lian, Zhongqi Miao, Ziwei Liu, Stella X. Yu: Long-tailed Recognition by Routing Diverse Distribution-Aware Experts. ICLR 2021
- Zhang, Yifan, et al. "Self-supervised aggregation of diverse experts for test-agnostic long-tailed recognition." Advances in neural information processing systems 35 (2022): 34077-34090.
- Lin, Xi, et al. "Smooth Tchebycheff scalarization for multi-objective optimization." Proceedings of the 41st International Conference on Machine Learning. 2024.
- Zhao, Zhe, et al. "Breaking Long-Tailed Learning Bottlenecks: A Controllable Paradigm with Hypernetwork-Generated Diverse Experts." The Thirty-eighth Annual Conference on Neural Information Processing Systems.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人