

[AAAI2024]AnomalyGPT Detecting Industrial Anomalies Using Large Vision-Language Models
本篇论文将大语言模型应用在工业异常检测(Industrial Anomaly Detection,IAD)任务。
引言
IAD任务旨在检测和定位工业产品图像中的异常。由于现实世界样本的稀有性和不可预测性,要求模型仅在正常样本上进行训练,并实现对测试时异常样本的检测。
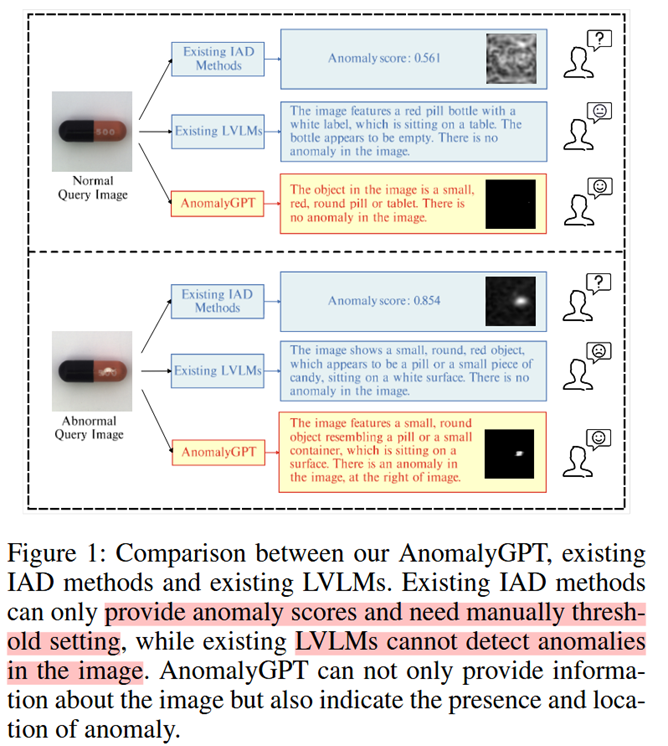
如图1,现有的IAD方法给出异常样本的概率,但需要手动设置阈值。大视觉语言模型(Large Vision-Language Models,LVLMs)能够过给出(有时不能给出)图片的描述,但不能实现异常检测。因此本篇文章将大语言模型应用在IAD任务中,提出AnomalyGPT模型(但实际上本文于GPT模型无关)。
相关工作
先用的IAD任务方法可分为两类
基于重建的方法 reconstruction-based
基于重建的目的是将异常样本重建为相应的正常样本,并通过计算重建误差来检测异常,使用的网络架构包括但不限于:自动编码器和,GAN,Transformer和扩散模型。
基于特征嵌入的方法 feature embedding-based
- 例如PatchSVDD(Yi and Yoon 2020)的方法通过建立包裹正常样本的超球面(hypersphere)。
- PyramidFlow(Lei et al. 2023)使用正则化流将正常样本投影到高斯分布上。
- CFA(Lee, Lee, and Song 2022)建立正常样本patch的embedding,比较测试样本的embedding与正常样本的距离,实现异常检测。
然而,上述方法学习到的类是固定的,不能识别新的类,这在实际的生产环境中并不适用。
对于大模型的使用,作者考虑了两个问题
数据稀缺性
LLaVA(Liu et al. 2023)和PandaGPT(Su et al. 2023)等方法在 16 万张图像上进行了预训练,并配有相应的多轮对话。IAD 数据集仅包含几千个样本,因此直接微调很容易导致过度拟合和灾难性遗忘。
针对这点,作者在框架中加入了额外的可学习prompt embedding层,而不是直接微调参数模型。
细粒度语义
大语言模型对于具有判别性的细粒度语义学习不充分。
针对这点,作者引入了轻量级视觉-文本对齐解码器,去生成像素级别的异常定位。
方法
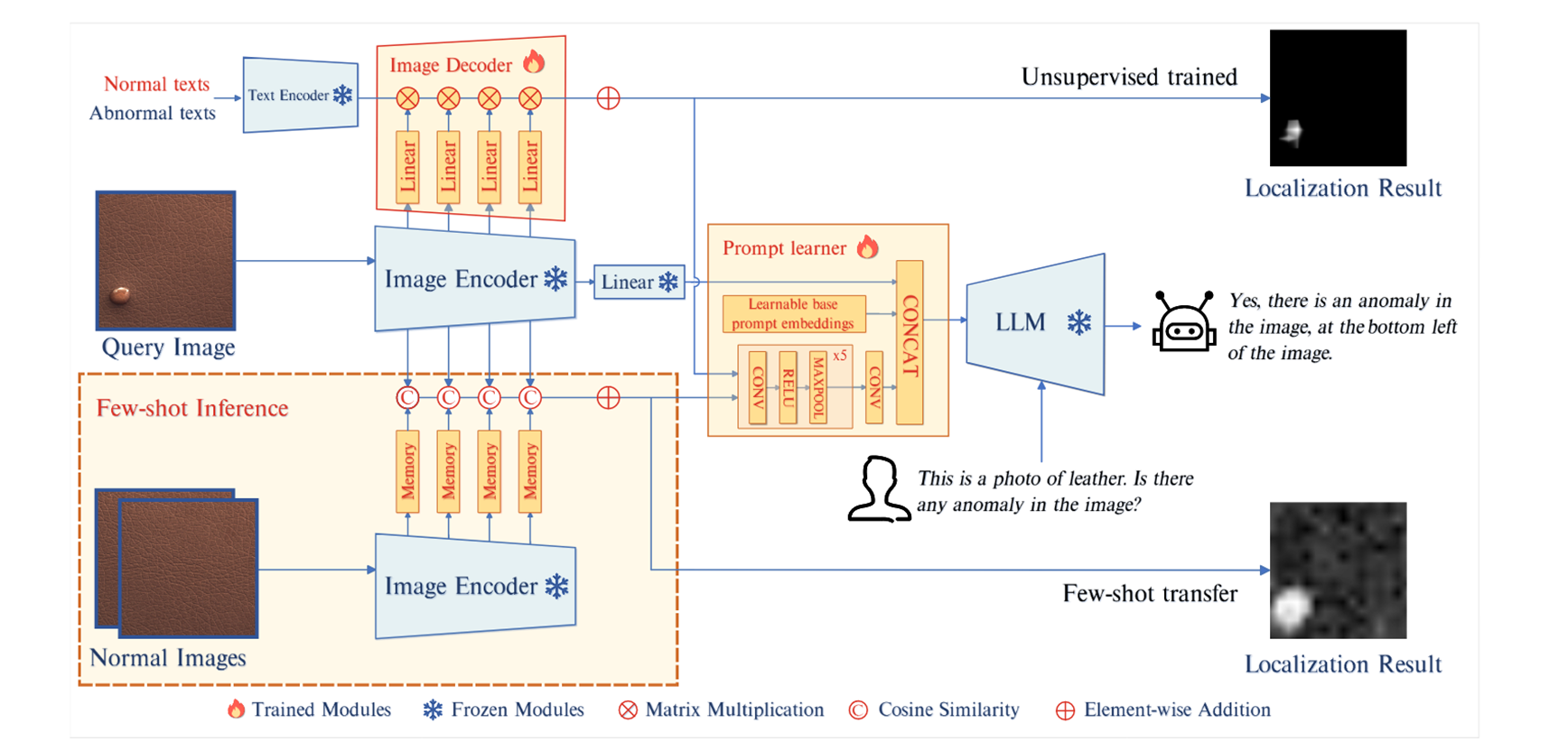
图像特征处理
作者考虑两种IAD任务设置:无监督和few-shot。中间公共的部分:输入样本
无监督设置下,输入图片没有标签,但会提供两条文本,例如:“A photo of a normal bottle. A photo of an abnormal capsule.” 两条文本经过预训练的Text Encoder后得到特征
输入文本变化起的格式包含 state-level,对于normal/anomaly的文本分别为文本的格式如下:
| normal | anomaly |
|---|---|
| c:="[o]" | c:="damaged [o]" |
| c:="flawless [o]" | c:="broken [o]" |
| ... | ... |
Token [o]可被替换为物体名,若物体名不可用,则使用“object”代替。完整 state-level的prompt template后填入 Template-level的文本,template-level的文本格式包括:
- "a cropped photo of the [c]."
- "a cropped photo of a [c]."
- "a close-up photo of a [c]."
- ...
经过文本编码器后的文本特征为
然后将文本特征与图像特征做矩阵乘法并上采样得到Mask:
Few-shot设置下,每个类存在几个带标注的样本,图像Encoder中间4层,分别对应一个容量为
两种设置下,掩码大小与输入图像一致
可学习的prompt embedding层
为了利用图像中的细粒度语义并保持 LLM 和解码器输出之间的语义一致性,引入了一个提示学习器,将定位结果
掩码经过卷积、投影变为长度为
用户输入图片的文本描述
为了帮助大模型更好的理解图片内容,可以输入图片描述完善以下内容:
## Human: <img>
每个类含若干个描述,例如:
Bottle:This is a photo of a bottle for anomaly detection, which should be round and without any damage, flaw, defect, scratch, hole or broken part.
然而,在实际生产中,文本描述也可以不提供。作者表示,仅提供
最后,对于大模型的输出大概是“Yes, there is an anomaly in the image, at the bottom left of the image. or No, there are no anomalies in the image.”
为了让模型更好的理解位置,图片被分为9格

损失函数
用交叉熵计算模型生成的文本序列与目标文本序列之间的损失(其中
在IAD任务中,异常图像中的大多数区域仍然是正常的,采用Focal损失可以缓解类别不平衡的问题(其中n=H×W表示像素总数):
并额外使用了Dice损失:
实验
数据集
- MVTec-AD 包含 15 个不同类别的 3629 张训练图像和 1725 张测试图像。
- VisA 包含 12 个类别的 9621 张正常图像和 1200 张异常图像。
与之前的IAD方法一致,仅使用这些数据集中的正常数据进行训练。为了模拟异常样本,作者使用poisson图像编辑,相较于裁剪-粘贴,对于边缘处理更平滑。

参考文献
- Gu, Zhaopeng, et al. "Anomalygpt: Detecting industrial anomalies using large vision-language models." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 3. 2024.


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PPT革命!DeepSeek+Kimi=N小时工作5分钟完成?
· What?废柴, 还在本地部署DeepSeek吗?Are you kidding?
· DeepSeek企业级部署实战指南:从服务器选型到Dify私有化落地
· 程序员转型AI:行业分析
· 重磅发布!DeepSeek 微调秘籍揭秘,一键解锁升级版全家桶,AI 玩家必备神器!