
[CVPR2024]DeiT-LT Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets
在长尾数据集上,本文引入强增强(文中也称为OOD)实现对DeiT的知识蒸馏的改进,实现尾部类分类性能的提升。
动机
- ViT相较于CNN缺少归纳偏置,如局部性(一个像素与周围的区域关系更紧密)、平移不变性(图像的主体在图像的任意位置都应该一样重要)。因此需要大型数据集进行预训练。
- 长尾数据学习的工作有很多,例如Re-weighting、Re-sampling,这些方法可以帮助尾部类学习,但会损害头部类的表现。一些工作提出了“多专家”去专攻不同的类别,最后汇总预测结果得到最终输出以改善性能。但是这些方法都是基于CNN的,而本文将“多专家”的思想代入transformer架构(ViT)。
对于第1点,之前的工作——DeiT通过对预训练的CNN架构模型知识蒸馏,改进了ViT的效率。而在本文中,作者希望将这一知识蒸馏的思想应用到长尾数据集上,并提高尾部类的分类性能。
还有一些工作虽然使得 ViT 在长尾识别任务上的性能有所提高,但它们通常需要在大规模数据集预训练。在这项工作中,目标是从头开始研究和改进视觉变换器的训练,而不需要对不同的长尾数据集(图像大小和分辨率各不相同)进行大规模预训练。
方法
回顾下DeiT[1],相较于ViT,多了DIS(distillation) token,它是教师模型对x的预测结果,作为\(\mathcal{L}_\text{teacher}\)的标签输入。
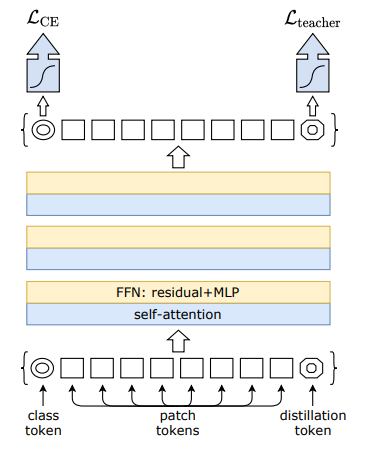
本文中的DeiT-LT,是在DeiT架构基础上:
- 对于输入的样本使用强增强(文中管强增强后的样本为OOD样本)。
- 增加了一个分类器用来表示尾部类专家,使用DRW(Deferred Re-weighting)loss优化。
- 通过蒸馏,从扁平的教师模型学习低秩特征。
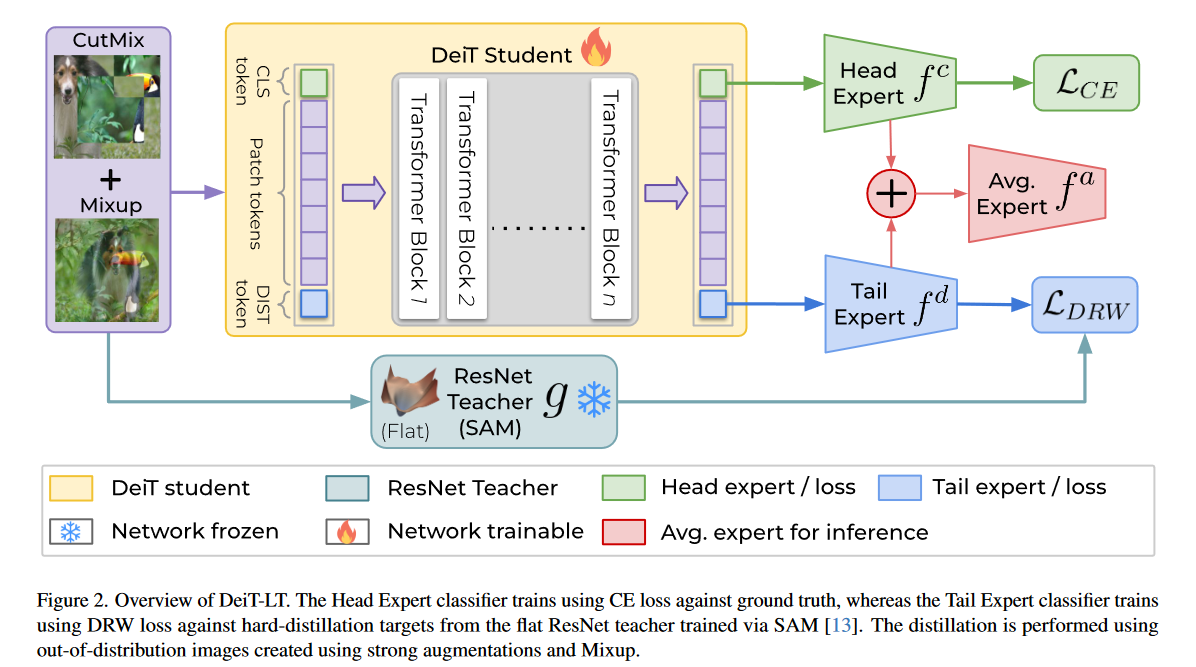
引入OOD样本的蒸馏
表中比较了教师、学生模型,是否使用强图像增强,和是否使用mixup(用X、√表示)的精度表现。
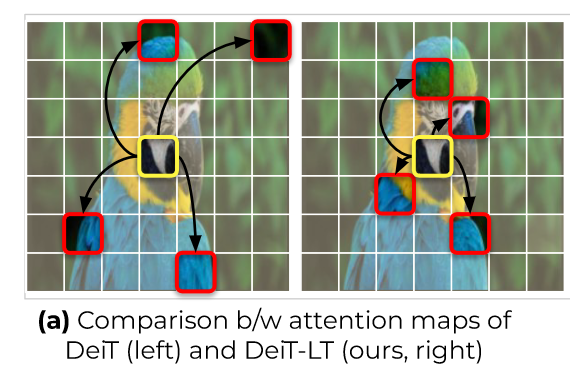
可看到,使用强增强训练的教师模型虽然精度下降了,但是学生模型的表现提升了。作者认为,这是学生模仿了老师对OOD的错误预测,从而学习到了老师的归纳偏置(例如下图的局部性),即\(f^d(X)\approx g(X),X\sim A(x)\)。
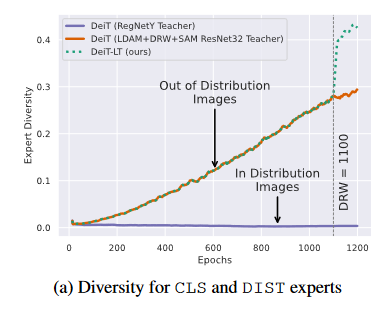
由于OOD样本对教师的影响,使得教师模型的预测\(y_t\)与ground-truth \(y\)不同。下图展示了,随着epoch增加,头部类专家和尾部类专家的余弦距离(cosine distance = 1 - cosine similarity)的变化。两条主要的线分别表示在强增强/非强增强(OOD/ID)训练得到的教师模型。
作者引入了DRW:
其中,\(w_y=1/\{1+(e_y-1)\mathbb{1}_{\mathrm{epoch\geq K}}\}\),\(e_y=\frac{1-\beta^{N_y}}{1-\beta}\),在上图也可以看到,DRW进一步增加了CLS token与DIS token间的多样性。
证明引入强增强(OOD)对知识蒸馏的有效性,可通过尾部类特征来判断。下图表示,尾部类特征的平均attention distance与transformer头的关系。可以看到没有OOD蒸馏的ViT和DeiT,过拟合了虚特征,使得尾部类泛化较差。


通过SAM 教师模型得到低秩特征
Sharpness Aware Minimization (SAM) 相当于在计算损失时,对模型参数增加扰动提高模型的泛化性。
对于低秩矩阵的计算,令\(\mathcal{X}_{all},\mathcal{X}_{min}\subset\mathcal{X}\),其中\(\mathcal{X}_{all}\)表示所有样本,\(\mathcal{X}_{min}\)表示尾部类样本。对应的特征矩阵为\(F_{n_h,d}^{all},\ F_{n_t,d}^{min}\),n表示样本数,d表示特征维度。对前者进行奇异值分解\(U,S,V^T=\mathsf{SVD}(F_{n_h,d}^{all})\),并使用右奇异值矩阵对\(F_{n_t,d}^{min}\)进行投影降维。对角阵k的取值满足
其中\(F_{recon}^{min}(k)=F_{proj}^{min}(k)*{V_k}^T.\)
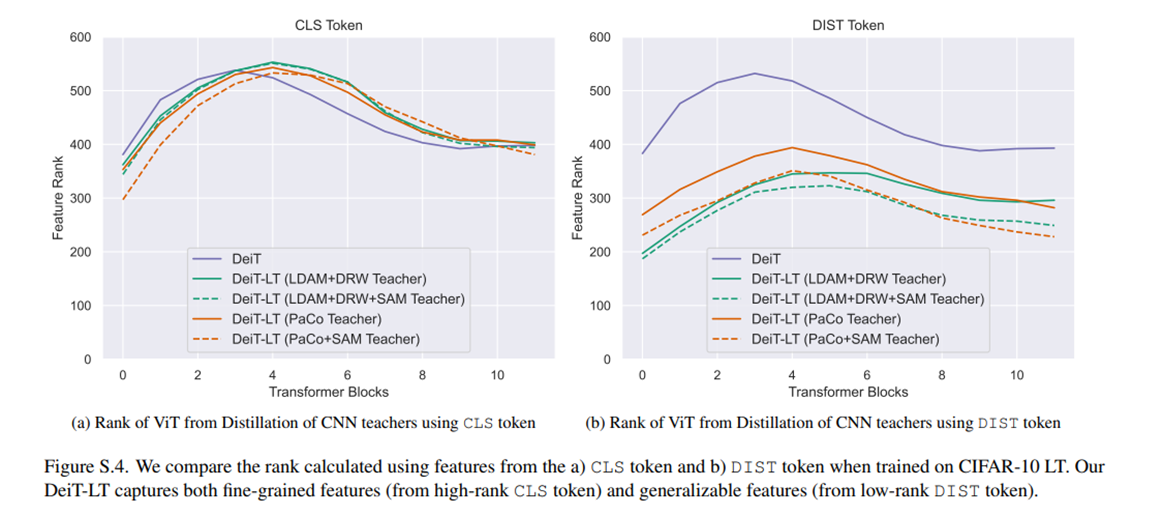
对比上图,CLS token和DIS token在不同block中输出特征的秩。可以看到DIST token从多数类中学到判别性特征(也就是下图中,作者的方法具有较低的平均注意力距离),充分保证了尾部类的学习。
参考文献
- Touvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention." International conference on machine learning. PMLR, 2021.
- Rangwani, Harsh, et al. "DeiT-LT: Distillation Strikes Back for Vision Transformer Training on Long-Tailed Datasets." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.

