
[NeurIPS2021]Open-set Label Noise Can Improve Robustness Against Inherent Label Noise
这篇文章与ICML2022的Open-sampling是同一个作者,方法一模一样,只是问题的场景变为噪声标签学习,Open-sampling是长尾问题的场景,可参见写的这篇blog。
这两篇文章大致做法完全相同:对biased数据集引入开集数据,在每个epoch分配均匀的闭集标签。如果是long tailed data,还涉及不平衡问题,因此分配就不是均匀分布了(详见之前的blog)。而这篇文章比Open-sampling早,且是在噪声标签学习问题上进行的,因此对于开集样本标签分配只是简单的均匀分配。但这篇文章提供了解释:为什么引入开集样本能帮助biased数据学习?
Method

对于无标签的数据集\(\mathcal{D}_{out}\),每个epoch会生成新的服从均匀分布的闭集噪声标签\(\mathcal{U}_k\),这部分数据使用单独的损失函数计算损失:
\(f\)表示分类器。而原来的数据集\(\mathcal{D}_{train}\)使用另外的损失函数,整体的训练目标为:
其中\(\eta\)是一个超参数,用于平衡两个损失函数的重要性。\(\mathcal{L}_1\)也可以使用其他的损失函数代替(文中使用的是CE)。
开集样本如何帮助噪声标签学习
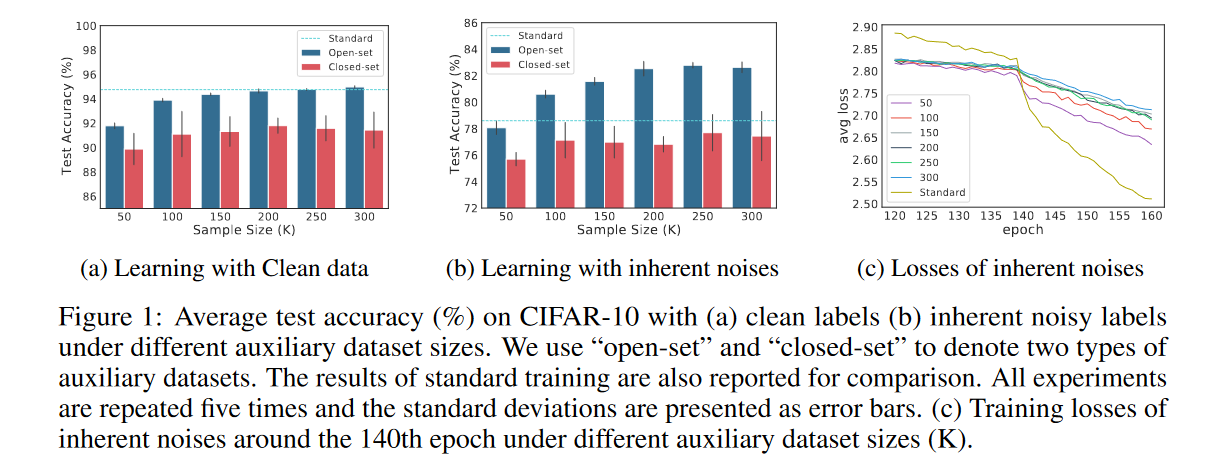
简单来说:利用open set,神经网络的额外容量可以在很大程度上消耗掉,而不会干扰对干净数据中学习。增加开集辅助样本的数量会减慢固有噪声的拟合(见Fig. 1c)。
站在SGD的角度,作者的方法引入的open set带来的噪声是随机方向的、无冲突的和偏置的,这可能有助于模型收敛到具有优异稳定性的平坦最小值,并强制模型对 open set产生保守的预测(作者还在OOD检测任务上进行了测试)。
- 随机方向:open set的噪声标签是均匀的,因此产生的SGD噪声方向随机,这使得训练难以收敛并有助于摆脱局部最小值。否则模型将很快收敛到局部最小值,因为在训练过程中参数的优化始终遵循梯度下降的方向。
- 无冲突:open set使用独立的损失函数。如果和闭集使用统一损失函数,闭集样本生成的噪声可能与原始梯度相冲突,导致训练不稳定。
- 偏置:open set的噪声期望不为0,因此噪声带来偏置,这会促使模型(分类器)\(f\)产生更保守的预测,因此该方法也能用于OOD检测。
作者在文中列举了关于噪声的SGD梯度相关证明,但个人觉得只是简单的化简。
Related Work
噪声标签学习大概可以分为以下几点,但彼此间不独立,也可以相互结合,因此才有不少A+B的paper。
- 使用挑选出来的样本训练:选择小损失样本;使用GMM分布筛出干净样本(e.g. Dividemix);使用多模型协议(通常是两个模型,两个模型同时认为是干净样本才算干净样本)。
- 对不同样本施加不同权重,干净样本权重更大。
- 基于估计的噪声转移矩阵或模型预测对损失进行校准。
- 设计更robust且有理论依据的损失函数。
- 设置正则化,提高噪声学习的泛化能力,如梯度裁剪、标签平滑。
- 与半监督结合。
Discussion
作者在文中仅考虑了与实例无关的开集噪声样本,大部分考虑训练集含开集噪声的论文也是如此。但实际场景下,开集噪声样本应当与干净样本有一定的相似性但仍不属于同一类(这在文中被称为instance-dependent open-set noisy labels),因此如果采用这种设置,结果可能又将不同。
参考文献
- Wei, Hongxin, et al. "Open-set label noise can improve robustness against inherent label noise." Advances in Neural Information Processing Systems 34 (2021): 7978-7992.
- Wei, Hongxin, et al. "Open-sampling: Exploring out-of-distribution data for re-balancing long-tailed datasets." International Conference on Machine Learning. PMLR, 2022.

