
[NeurIPS2019]Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
文章提供的代码结构简洁,简单易懂,十分适合作为Baseline。省去冗长的数学证明,直接看文章的贡献:
- 受SVM的hinge loss启发,提出了新的Loss函数鼓励每个类在表征空间有更大的margin。
- 延迟re-weighting的trick。
- 在多个数据集,包括情感分类、图像分类进行实验。
Motivation & Methods
LDAM(Label-Distribution-Aware Margie) Loss
tail classes的信息基本上较少,而且部署的模型通常很大,因此对tail classes的过度拟合似乎是改进这些方法的挑战之一。作者建议对tail classes进行比head classes更强的正则化,这样我们就可以在不牺牲模型拟合head classes的能力的情况下改进tail classes的泛化误差。
实现这个一般概念需要一个依赖于数据或依赖于标签的正则化器,由于依靠标签来区分head classes 或 tail classes,作者选择了最简单和最容易理解的数据相关属性之一:训练样本的边距——鼓励较大的边距可以看作是正则化,因为标准泛化误差范围(例如,[4, 59])取决于所有示例中最小边距的倒数。
受tail classes的泛化问题的启发,我们转而研究每个类的最小边距,并获得每个类和统一标签的测试误差边界,最小化获得的边界,可以在类的margin间得到最佳权衡。
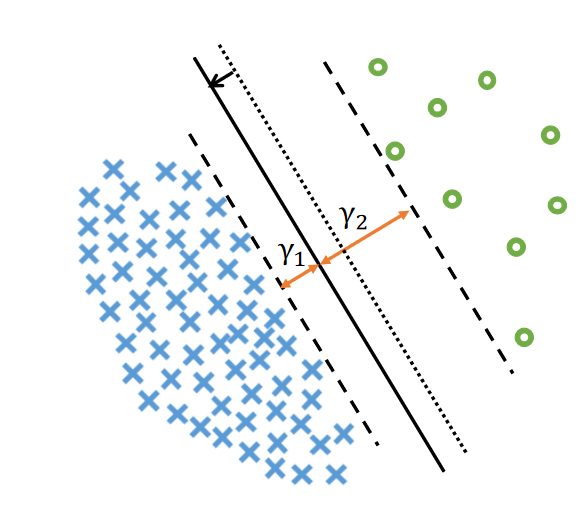
对于具有线性可分离分类器的二元分类,边距\(\gamma_i\)表示第i类中的数据到决策边界的最小距离。作者证明,均匀标签分布的测试误差受 \(\frac1{\gamma_1\sqrt{n_1}}+\frac1{\gamma_2\sqrt{n_2}}\) 范围内的量限制。如图所示,固定的决策边界会导致固定的\(\gamma_1+\gamma_2\),但\(\gamma_1, \gamma_2\)之间的权衡可以通过移动决策边界来优化。最优权衡是\(\gamma_i\propto n_i^{-1/4}\) \(n_i\)表示i类的样本数。
基于最小化基于边界正则化的启发,提出的新的损失函数:label distribution aware margin( LDAM) loss 取代交叉熵损失函数,这鼓励tail classes 去实现更大的margin。该方法与re-weighting, re-sampling正交。
令样本表示为\((x,y)\),\(f\)是模型,\(z=f(x)\)是模型的输出,\(z_j\)是模型输出的第j个类,\(n_j\)是第j类的样本数,\(C\)是一个超参数,损失函数很自然地设置为hinge loss的多分类形式:
但hinge loss的不平滑性给优化带来了困难,因此作者将hinge loss与CE结合:
为了更容易调整边距,作者对logits(backbone最后一层的输出)使用L2进行normalize至1,对于模型最后一层全连接层参数也使用L2进行normalize至1。实际测试如果没有这一步,loss会非常大甚至导致nan。
这一步作者是follow: Wang, Feng, et al. "Additive margin softmax for face verification." IEEE Signal Processing Letters 25.7 (2018): 926-930.
DRW(Defers Re-Weighting)
re-weighting 和 re-sampling是两种处理不平衡数据的常见策略。当模型是深度神经网络时,对tail classes中的示例进行重新采样通常会导致对tail classes的严重过度拟合;加权tail classes的损失可能会导致优化困难和不稳定,特别是当类别极度不平衡时。
作者凭经验观察到(只是做了实验并没有分析原因),在按以下方式对学习率进行退火(可以理解为学习率衰减)之前,re-weighting和re-sampling均不如普通的经验风险最小化(ERM)算法(其中所有训练示例具有相同的权重)。通过re-weighting和re-sampling对学习率进行退火之前产生的特征比 ERM 产生的特征更差。
一种简单有效的训练策略:延迟采样(defers re-weighting)使得re-weighting策略与提出的损失函数更好结合。
首先是第一次训练:使用普通 ERM 和 LDAM 损失进行训练,然后对学习率进行退火,然后是第二次训练:部署具有较小学习率的重新加权 LDAM 损失。根据经验,第一阶段的训练可以为第二阶段的训练带来良好的初始化,并重新加权损失。由于损失是非凸的,并且第二阶段的学习率相对较小,因此第二阶段不会将权重移动很远。

作者发现,自己二阶段训练和LDAM Loss的效果 与原始re-weighting策略(通过每个类中示例数量的倒数重新加权)结合,取得了与[2]提出的CB损失函数的re-weighting策略相当的效果。并且,作者的方法,在比较early stopping,比[2]更加不敏感。
从代码来看,简单得说,这里作者还是沿用了[2]的“有效样本数”的倒数作为re-weighting的权重,只是在\(T_0\)后的epoch,将这个权重变得很小。
[2] Cui, Yin, et al. "Class-balanced loss based on effective number of samples." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
Experiments
作者实验设置两种不平衡:
- 长尾不平衡(Long-tailed imbalance):随着不同类别的样本量呈指数衰减。
- 步长不平衡(Step imbalance):所有少数类都具有相同的样本量,所有频繁类也是如此。
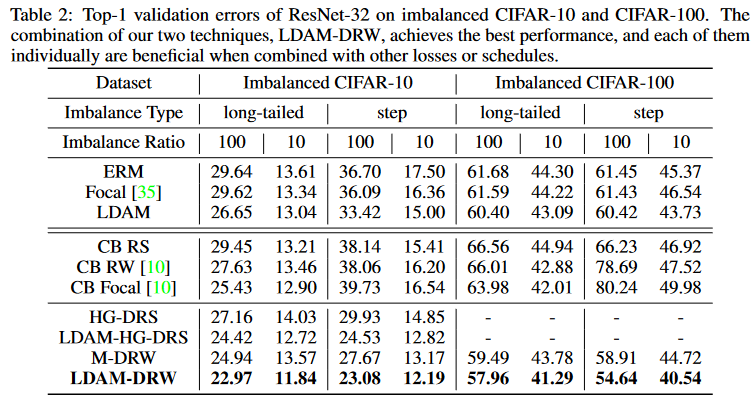
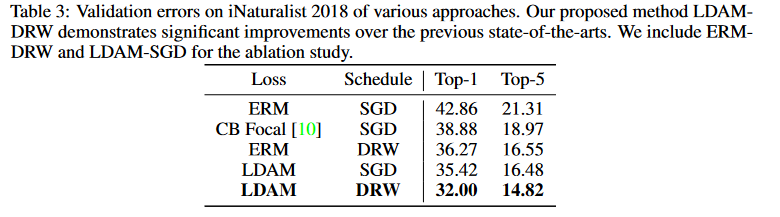
参考文献
- Cao, Kaidi, et al. "Learning imbalanced datasets with label-distribution-aware margin loss." Advances in neural information processing systems 32 (2019).
- Cui, Yin, et al. "Class-balanced loss based on effective number of samples." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
