
Semantic Prompt for Few-Shot Image Recognition
原论文于2023.11.6撤稿,原因:缺乏合法的授权,详见此处
Abstract
在小样本学习中(Few-shot Learning, FSL)中,有通过利用额外的语义信息,如类名的文本Embedding,通过将语义原型与视觉原型相结合来解决样本稀少的问题。但这种方法可能会遇到稀有样本中学到噪声特征导致收益有限。在这篇论文,作者提出了一种用于少样本学习的语义提示(Semantic Prompt, SP)方法,不同于简单地利用语义信息纠正分类器,而是选择用语义信息作为提示(prompt)去自适应调整视觉特征提取网络。
具体来说,作者设计了两种互补机制,将语义提示插入特征提取器:1、在空间维度上,通过自注意力机制使语义提示和局部图块(patch)embedding相互作用;2、在通道维度上,用变换后的语义提示补充视觉特征。通过结合这两种机制,特征提取器能更好地关注特定类的特征,并仅用了较少的支持样本就能得到通用的图像表示。
1. 引言
在解决小样本问题时,最有效的FSL方法是利用从大量标记基础数据集学习而来的先验知识,并将先验知识编码为一组初始网络参数,或者在所有的类中共享固定的嵌入函数。
由于缺少新的类的带标签图像,一种直接替代方式是使用其他模式的辅助信息,例如语言模型,来帮助学习新的类,这在zero-shot中已经被广泛使用了。这些方法通常直接使用文本embeddings用于新的类的图像分类器。基于此,一些FSL研究提出了从类名推断文本原型,并将其与从罕见的支持图像中提取的视觉原型结合。另一些方法通过引入更复杂的文本预测器,或者利用大规模预训练模型产出更准确的文本原型。
这些方法大多直接从文本特征中得到类的原型,忽视了文本特征与视觉特征的信息差。确切来说,文本特征可能包含了新的类与已知的类之间的语义联系,但由于缺少与底层视觉表示的交互,这些方法不能提供能确切区分新类的视觉特征。此外,由于有限的支持图像,学习到的视觉特征仍然遭受噪声特征的影响,例如背景的干扰。
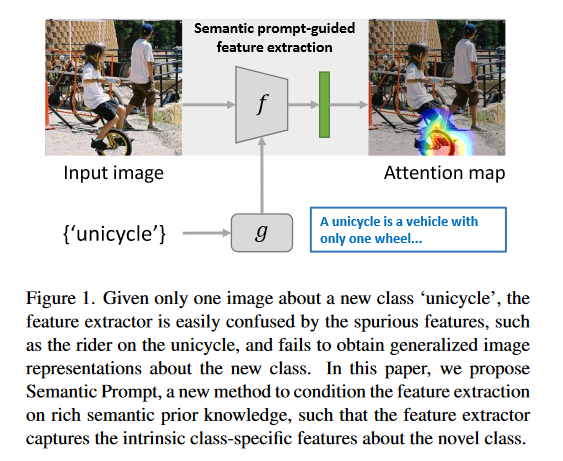
在图一中,对于一个新类“unicycle”,特征提取器可能会将unicycle图像和其他干扰因素作为图像特征,干扰因素可能包含骑手和房屋,并在其他场景下不能识别unicycle。本文中,作者选择使用文本特征作为语义提示去自适应调整特征提取网络,如图一所示,在语义提示的指导下,特征提取器注重捕获新类的固有特征而不是杂乱的背景。
此外,在大规模训练的自然语言模型(Natural Language Process, NLP)如BERT和GPT能从类名挖掘丰富的文本信息。通过语义提示和视觉特征相互作用,可以帮助特征提取器判断视觉特征时提供附加信息,并产生更通用的类原型。
语义提示与视觉特征的相互作用发生在空间维度与通道维度。
- 空间维度上,用语义提示扩展图像块序列,并输入到Transformer的Encoder中,通过自注意力层,语义提示可以使特征提取器关注类的特定特征并一直其他干扰因素;
- 通道维度上,首先将语义提示与从所有图像块中提取的视觉上下文连接,然后投喂进多层感知机(Multilayer Perceptron, MLP)模块。提取的特征向量会被添加到每个图像块中,在逐个通道中调整与增强视觉特征。
2. 问题设置
FSL问题中通常被定义为N-way、K-shot分类任务,对于查询集
在之前的工作中,图像的标签
3. 方法
3.1 预训练
在FSL中,学习通用特征提取器是将知识转移到下游学习任务的关键。在给定的标签数据集
其中,
对于骨干网络的选择,为了促进视觉特征与语义提示相互作用,采用Vision Transformer作为图像特征提取器
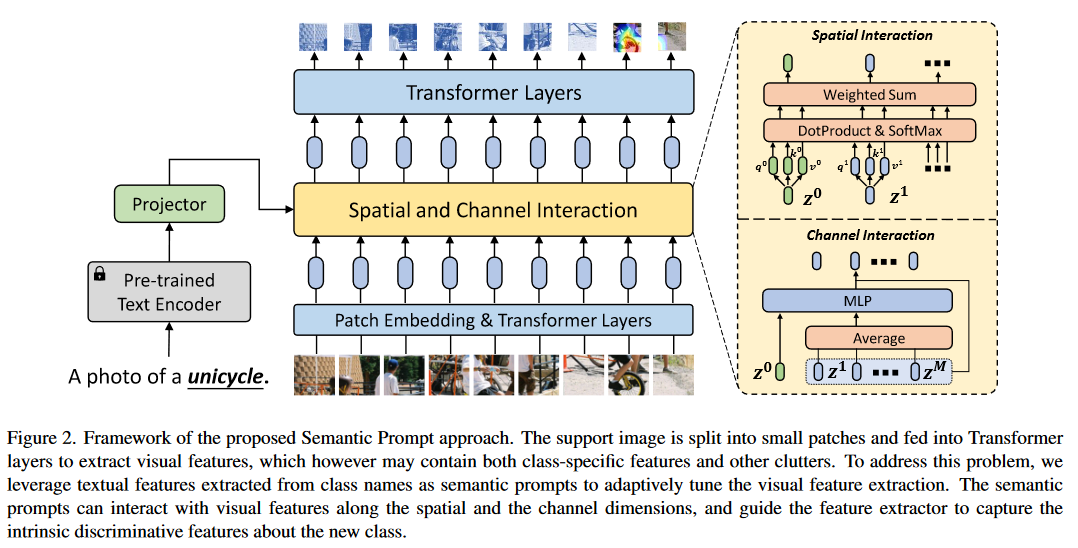
每一个图像块token都会被投入Transformer层L,提取视觉特征。每一个特征由多头自注意力(Multihead Self-Attention, MSA)、MLP块、归一化层和残差连接组成(各个层的结构顺序如下图所示)。在L的顶层,将所有token序列中的embedding向量求平均作为提取的图像特征:
其中

图片来源:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale。文中改进了Transformer并应用于计算机视觉,作者将其命名为Vision Transformer(ViT)。
自注意力的计算量为序列长度的平方,为了降低计算成本,采用ViT的变体Visformer作为Transformer层的实现。
3.2 语义提示
在基础训练进行预训练后的特征提取器
在一次训练的episode,对于支持集的图像
其中
episode: episode指一次训练的子任务。举例来说,假设正在使用元学习来训练一个模型来识别不同的动物。每个episode可能代表一个特定的识别任务,比如在一个episode中,模型需要学会识别猫和狗,而在另一个episode中,模型需要学会识别鸟类和鱼类。每个episode都会提供一组训练样本,以及模型需要尽快学会正确分类这些样本的机会。
在元训练中,会冻结文本编码器
其中
3.2.1 空间维度的相互作用
对于给定的语义特征
其中,
其中,
注意力权重可以聚合不同位置的信息,最终输出通过连接所有头的输出并由参数
公式(6)-(8)可参考Transformer原论文
3.2.2 通道维度的相互作用
除了通过MSA进行空间上的相互作用外,还提出了另一种交互机制:可以根据输入的语义提示逐个通道得调节和增强视觉特征。对于
将视觉特征
其中,
最后,将图像块token与上面得到的调节向量相加以调整每个通道上的视觉特征,调整的序列为
4. 实验
4.1 数据集测试
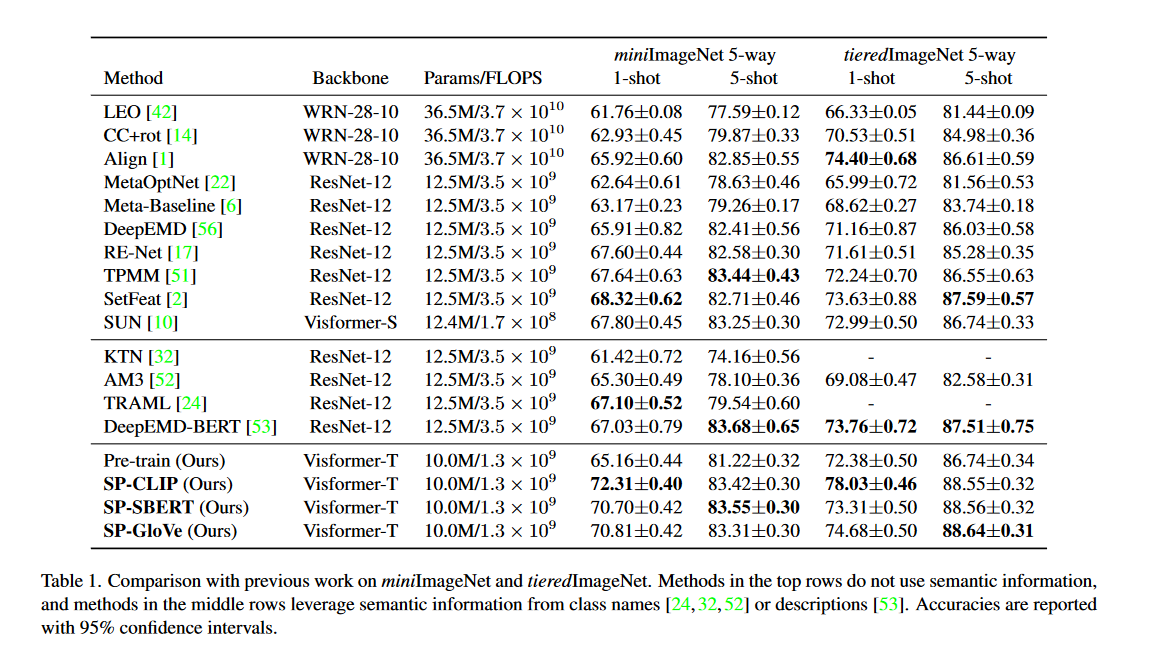
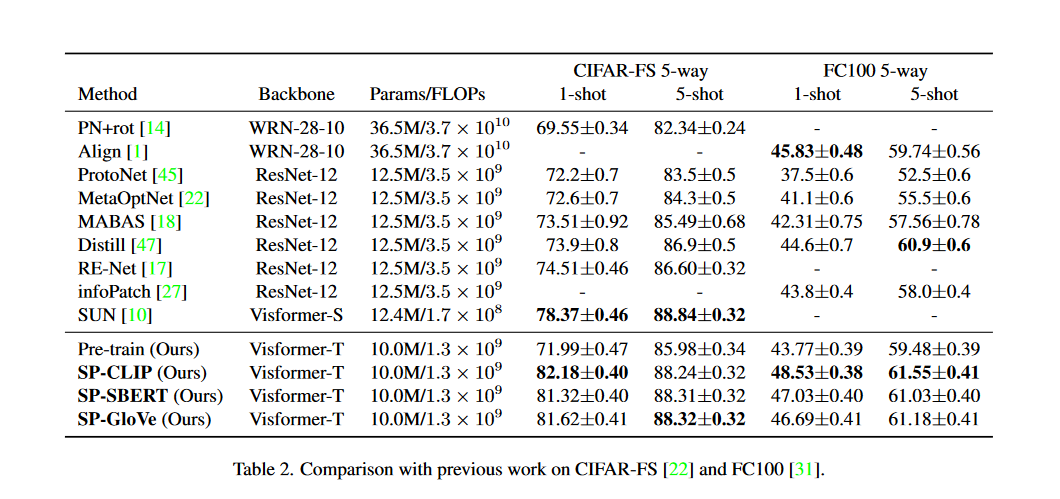
作者在四个数据集上与其他SOTA方法进行对比试验如表1、表2所示。对于预训练的文本编码器,一共试验了三种:CLIP、SBERT、GloVe。对于CLIP的使用输入采用模板:A photo of a {class name}。而其他两种文本编码器的输入为类名。如果名称中有多个单词,则对输出单词向量求平均。文中默认使用的文本编码器为ClIP。
可以看到之前的方法通常采用CNN作为骨干网络,对比同样以Visformer-S的SUN,准确率提升了2.46%
4.2 模型分析
4.2.1 消融研究
文中进行了消融研究,结果如表3所示,证明图像增强与两种交互机制的有效性。
4.2.2 层的选择
特征提取器有三个阶段,每个阶段含有多个Transformer层。理论上语义提示可以在任意层插入,实验研究了二、三阶段不同层插入语义提示的实验结果。可以发现,插入高层时模型的表现较好,插入低层时模型的表现下降。文中认为语义提示向量特定于类,而更高层的网络层提取的特征特定于类,而在低层提取的特征会在类间共享。在图3中,可以看到语义提示插入三阶段的整体表现较好,语义提示默认插入位置为layer3-2(三阶段的第二层)。
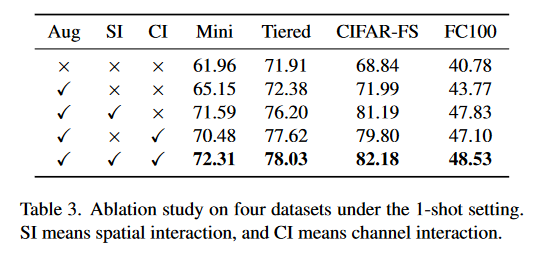
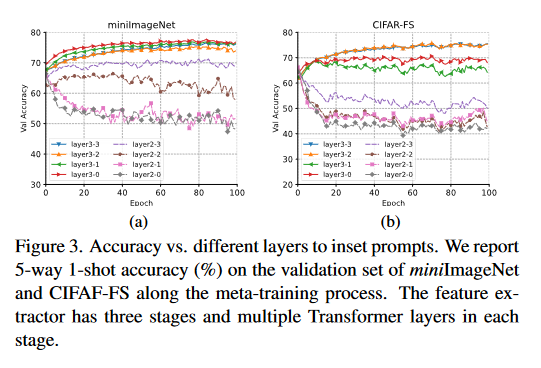
4.2.3 骨干网络和分类器架构
表4中用两种骨干网络测试了3种baseline方法,可见骨干网络的替换并不能明显提高精度,而使用了语义提示后精度得到了明显提高。表5中比较两种分类器余弦距离分类器和线性逻辑回归分类器,两者的精度差距不大。

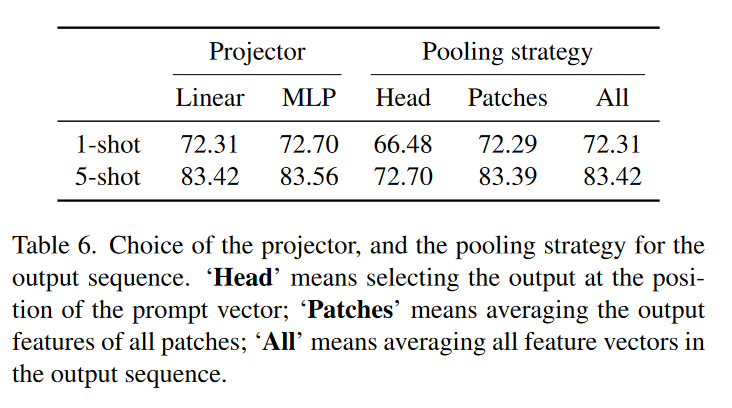
4.2.4 投影器和池化策略
表6可以看到,投影器的选择对精度影响不大,不管是线性还是多层感知机都表现良好。但池化的策略选择对精度影响较大,当选择Head策略时,模型精度较差,这表明仅通过语义特征无法获得较好的泛化能力。
- Head: 选择语义提示向量位置处的输出(公式(5)的
- Patch: 对所有图像块的特征取平均(公式(5)的
- All: 对所有特征向量取平均。
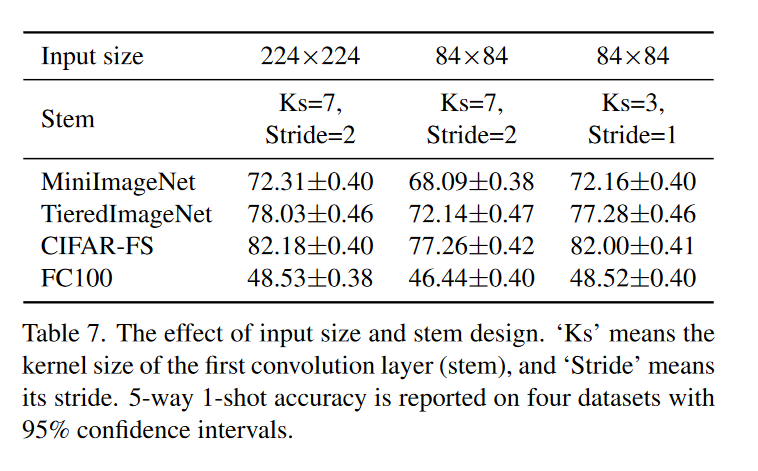
4.2.5 图像大小和主干设计
表7可以看到,保持卷积主干不变的情况下缩小图像会导致精度下降,因为此时卷积核和卷积步幅太大不能捕获详细的视觉特征,如果相应地减少卷积核和步幅,精度会提高。
4.2.6 可视化
在图4中,对注意力图进行可视化。在预训练的baseline中夹杂着背景信息,如果给出特定的文本提示,模型就能专注于某一部分(蜘蛛或是蛛网)。

5. 总结
本文提出了一种新颖的 FSL 语义提示(SP)方法,该方法利用从类名派生的语义特征自适应地调整特征提取。所提出的方法在四个基准数据集上进行了评估,并相对于以前的方法取得了显着的改进。更深入的分析表明,SP 鼓励模型提取更多类别特定的特征,并且对不同的文本编码器和模型设计具有健壮性。
参考文献
- Chen, Wentao, et al. "Semantic Prompt for Few-Shot Image Recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律