

Semi-Supervised Domain Adaptation with Source Label Adaptation
Semi-Supervised Domain Adaptation with Source Label Adaptation
具有源标签适应的半监督域适应
Abstract
文章指出当前的半监督域适应(Semi-Supervised Domain Adaptation, SSDA)方法通常是通过特征空间映射和伪标签分配将目标数据与标记的源数据对齐,然而,这种面向源数据的模型有时会将目标数据与错误类别的源数据对齐,导致分类性能降低。
本文提出了一种用于SSDA的新型源自适应范式,该范式通过调整源数据以匹配目标数据,从而提高分类性能。
文中所提出的模型可以有效清除源标签内的噪声,并在基准数据集上表现优于其他方法。
1. Introduction
前人从理论和算法的角度广泛地研究了非监督域适应(Unsupervised DA, UDA),其中目标域的标签是无法访问。近期,半监督域适应(SSDA)受到了关注,半监督域适应是一种允许访问部分目标标签的DA,这种改变简单、现实符合应用需求。
最经典的SSDA策略便是S+T:使用源数据和未标记的目标数据并采用标准交叉熵损失函数训练模型。但由于不同数据分布差异,该策略总是遇到域转移问题。为解决这个问题,许多SOTA(state-of-the-art algorithm)试图探索充分利用未标记的目标数据,以便目标分布可以与源分布保持一致。
最近,几种半监督学习(Semi-Supervised Learning, SSL)算法已经应用至SSDA来对未标记的数据进行正则化,例如熵最小化(entropy minimization)、伪标记(pseudo-labeling)、和一致性正则化(consistency regularization)。虽然这些算法发展了较长时间,但它们通常要求目标数据与源数据有一定的语义相似性。因此,如果S+T空间未对准将很难表现好。如图1上方所示:
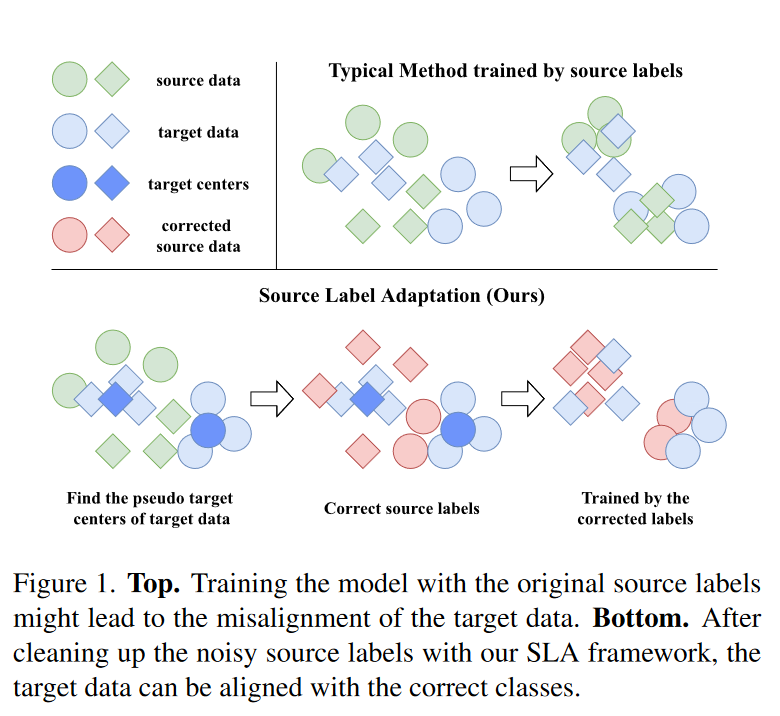
作者在文中举例认为依赖源标签的算法例如S+T会误导模型学习错误的类。因此源标签可以被视为目标分类中带噪声的标签,SSDA更像是一个噪声标签学习(Noisy Label Learning, NLL):有大量的噪声标签(源标签)和少量的干净标签(目标标签)。
作者借鉴标签校正的思想(借助另一个模型来清理噪声标签),提出了源标签适应框架(Source Label Adaptation, SLA),如图1下部分所示。作者构造了一个标签适应组件提供了目标数据的视图并在每一次迭代中动态清理带噪声的源标签。之前的研究是利用未标记的目标数据,而作者是研究如何使用适应的标签来训练源数据以更好地适应理想的目标空间。这种源自适应范式与现有的SSDA算法背后的核心思想完全正交,因此可以将两者结合达到更好的效果。
作者总结了三点贡献:
- 经典的面向源的方法如S+T及其派生的算法任然会受到有偏差的特征空间的影响,为了摆脱困境,作者提议修改原始源标签来使源数据适应目标空间。
- 作者将DA当作是NLL的特定情况并提出了一种新颖的源适应范式,作者的框架能够简单地与现用的算法结合并提高性能。
- 作者展示SLA框架与SSDA的SOTA算法结合。该框架在两个主要测试数据集上显著改进了现有的算法,指引了解决DA问题的新方向。
2. Related Work
问题设置
DA专注于m维度的K类分类任务,
- 输入空间:\(X\subseteq\mathbb{R}^m\)
- 标签集合:\(\{1,2,\dots,K\}\)
- 在概率单纯形上\(\triangle^K\)上定义标签空间\(Y\),标签\(y=k\in\{1,2,\cdots,K\}\)相当于独热编码向量,\(y\in Y\)
- 设立\(X\times Y\)的两个域:源域\(D_s\),目标域\(D_t\)
- 在SSDA,对带标签的源数据进行一定数量的采样:\(S=\{(x^s_i,u^s_i)\}_{i=1}^{|S|}\),数据来自\(D_s\);对带标签的目标数据进行采样:\(L=\{(x^{\ell}_i,u^{\ell}_i)\}_{i=1}^{|L|}\),数据来自\(D_t\);以及未标签的目标数据:\(U=\{x^u_i\}^{|U|}_{i=1}\),数据来自\(D_t\)在\(X\)的边缘分布。
- 通常,\(|L|\)是远小于\(|S|\)和\(|U|\)。
- 目标是训练带有\(U\)、\(S\)、\(L\)的SSDA模型\(g\),使其在目标域上表现良好。
半监督学习
SSDA可以被视为UDA的简单现实形式。SSDA算法通常包含三个损失函数:
\(\mathcal{L}_s\)是由源数据得到的损失;\(\mathcal{L}_{\ell},\mathcal{L}_u\)分别表示来自标记的和未标记目标数据的损失。
由于问题的相似性,近期的研究为了解决SSDA问题借鉴了SSL的技术,提出了一种熵最小化的变体,以明确地将目标数据与源集群对齐。
Deep co-training with task decomposition for semisupervised domain adaptation一文中,将SSDA拆解为SSL和UDA任务。两个不同的子任务分别产生伪标签,并通过协同训练相互学习。
Cross-Domain Adaptive Clustering for Semi-Supervised Domain Adaptation一文中通过测量成对特征相似性将目标特征分组。
Multi-level Consistency Learning for Semi-supervised Domain Adaptation一文中利用三个不同级别的一致性正则化执行域对齐。
此外,这两篇文章都应用了带有数据增强的伪标签来增强其性能。从目标数据的角度来看,源标签可能显得嘈杂,作者提出了一个源自适应框架以逐渐使源数据适应目标空间,这种框架可应用于上述几种算法提高性能。
噪声标签学习
机器学习算法的结果高度依赖于数据集的质量。为解决噪声标签,TRAINING DEEP NEURAL NETWORKS ON NOISY LABELS WITH BOOTSTRAPPING一文中提出一种平滑机制,降噪生变标签与与自我预测相结合。
Joint Optimization Framework for Learning with Noisy Labels将干净标签建模为可训练参数,并设计联合优化算法来交替更新参数。
作者在,TRAINING DEEP NEURAL NETWORKS ON NOISY LABELS WITH BOOTSTRAPPING和Meta Label Correction for Noisy Label Learning的启发下,构造了一个简单框架,可以有效地构建标签适应模型来纠正噪声标签。
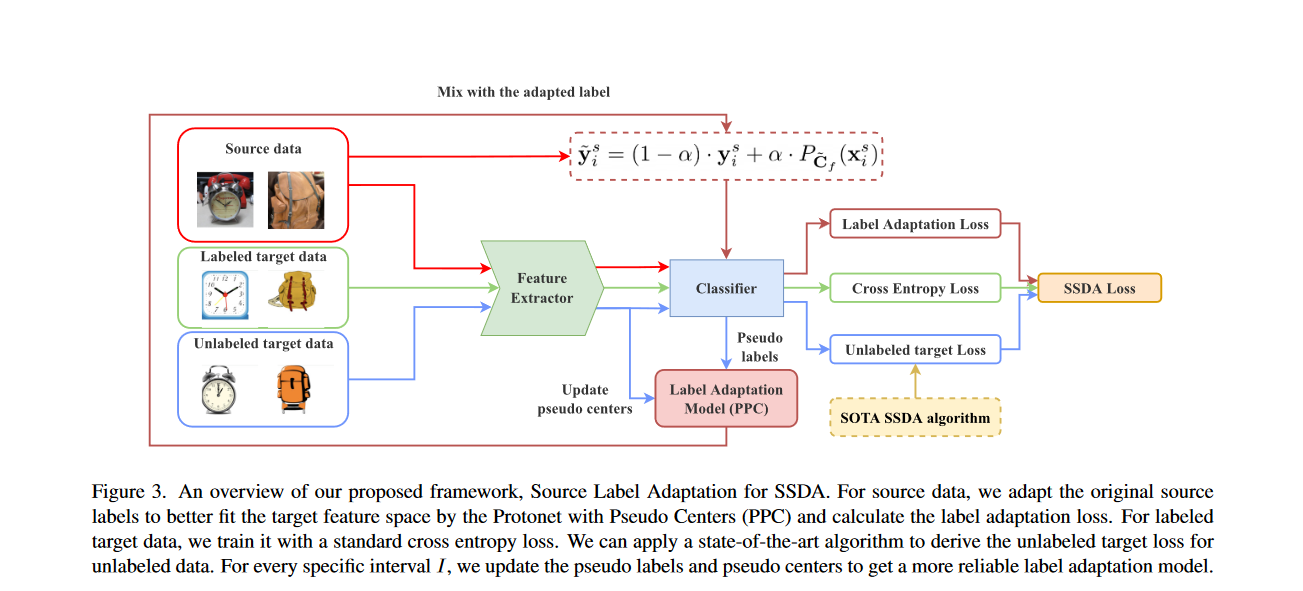
3. Proposed Framework
3.1 将域适应作为噪声标签学习
在域适应中,寻找一个理想的模型\(g^*\),它可以最小化未标记的目标风险。理想情况下,目标空间中源实例\(x^s_i\)最合适的标签是\(g^*(x^s_i)\),理想的源损失\(\mathcal{L}^s_i\)为:
其中\(H\)为测量两个分布之间的交叉熵
结合带标签的目标损失\(\mathcal{L}_\ell\),作者将\(\mathcal{L^*_s}\)和\(\mathcal{L}_\ell\)训练的模型称为理想适应的S+T
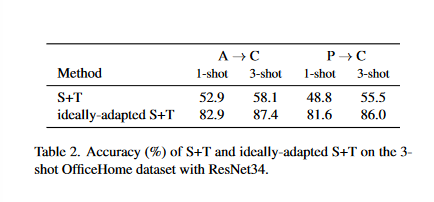
表中的测试结果展示了适应源标签的潜力——理想适应的S+T与标准的S+T有着显著的差异,这是仅修改源标签带来的影响。但是实践中只能得到近似理想模型,为解决该问题,作者将原始源标签视为理想标签的噪声版本,将DA视为NLL模型。
首先是通过TRAINING DEEP NEURAL NETWORKS ON NOISY LABELS WITH BOOTSTRAPPING提出的方法帮助纠正源标签。具体来说,对于每一个源实例\(x^s_i\),构建修正源标签\(\hat{y}^s_i\),修正标签由带比率\(\alpha\)的两部分组成:原始标签\(y^s_i\)和当前模型\(g\)的预测。
于是,修正的源损失\(\hat{\mathcal{L}}_s\)为
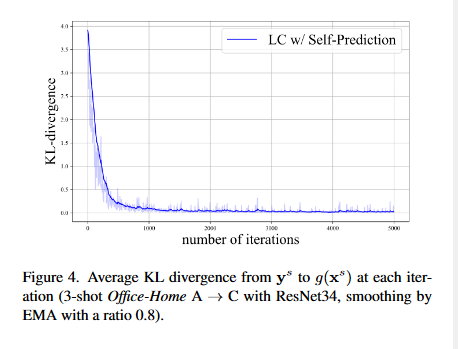
但是在DA中,这种方式可能不适用,因为模型通常会过度拟合源数据使得\(g(x^s_i)\approx y^s_i\),也就是修改后的源标签\(\hat{y}^s_i\)会与原始源标签\(y^s_i\)几乎相同。
图4中展示了当使用自预测进行标签校正时,经过2000次迭代\(y^s\)和\(g(x^s)\)的KL散度几乎一致。这种情况下,进行校正相当于不进行校正。
为了充分利用修正后的标签,需要消除对原数据的监督。由于理想的干净标签是理想模型\(g^*\)的输出,因此需要一个近似理想模型的标签适应模型\(g_c\)使源标签适应目标数据。将适应标签\(\tilde{y}^s_i\)定义为原始标签\(y^s_i\)和\(g_c\)输出之间的凸组合:
3.2 具有伪中心的Protonet
在半监督学习中,虽然可以访问部分目标标签,但由于数量有限可能会遇到严重的过拟合问题,因此选择使用原型网络(protonet)克服样本数量少的问题。
给定数据集\(\{x_i,y_i\}^N_{i=1}\),特征提取器\(f\)。\(N_k\)表示用\(k\)标记的数据的数量,\(k\)的原型被定义为具有相同类的特征中心:
令\(C_f=\{c_1,\dots,c_K\}\)使用特征提取器\(f\)收集所有中心。将\(P_{C_f}:X\mapsto Y\)定义为带中心\(C_f\)的protonet模型:
此处,\(d:F\times F\mapsto[0,\infty)\)表示特征空间\(F\)的距离度量,通常是欧氏距离(L2距离);\(T\)是控制输出平滑度的超参数,当\(T\to0\)时,protonet的输出将接近均匀分布。
当\(d\)测量欧氏距离时,protonet相当于在\(F\)上具有特定参数化的线性分类器。由于带标记中心的protonet是由目标数据的角度构建的,因此能减少3.1中提到的问题。
然而,在protonet中,理想中心\(C^*_f\)应通过未标记的目标数据集\(\{x^u_i\}^{|U|}_{i=1}\)。
对于当前模型,未标记目标实例\(x^u_i\)的伪中心\(\tilde{y}_i^u\)为
使用伪标签\(\{x^u_i,\tilde{y}_i^u\}^{|U|}_{i=1}\) 导出未标记的目标数据后,通过式(6)得到伪中心\(\tilde{C_f}\),并通过式(7)进一步定义具有伪中心的protonet(Protonet with Pseudo Centers, PPC)\(P_{\tilde{C}_f}\)。

表3中对比了S+T训练的特征空间分别从理想中心\(C^*_f\)到标记目标中心\(C^{\ell}_f\)和伪中心\(\tilde{C_f}\)的L2距离,这意味着伪中心确实更接近理想中心。
将PPC作为标签适应模型,修改后的标签\(\tilde{y}_i^S\)变为:
3.3 用于SSDA的源标签适应
作者用标准交叉熵损失代替典型的源损失。对于每一个源实例带有标签\(y^s_i\)的\(x^s_i\)首先通过式(9)计算修正源标签\(y_i^s\)。因此标签的适应损失\(\tilde{L}_S\):
作者的框架源标签适应(Source Label Adaptation, SLA)可通过一下损失函数进行训练:
\(\mathcal{L}_\ell\)是目标数据的损失函数,也可以选用标准的交叉熵损失函数。对于未标记的目标数据\(\mathcal{L}_u\)的损失函数,可以采用任何SOTA,作者的框架可以轻松地与其他方法耦合但不产生矛盾。
实现细节
- 预处理(热身)阶段:框架依赖于预测的伪标签的质量。然而,初始模型的预测可能存在噪声。因此,需要引入一个超参数\(W\)进行预热,以获得更稳定的伪标签。在预热阶段,使用原始源标签正常训练我们的模型。具体来说,在第\(e\)次迭代时,我们计算修改后的源标签\(\tilde{y}^s_i\)如下:
- 动态更新:特征空间和预测的伪标签在训练阶段不断演变,通过更新伪标签和中心,目标是确保投影的伪中心在整个训练阶段保持其准确性或正确性。实际中通过式(8)更新伪标签;对于每个特定区间\(I\),通过式(6)使用当前的特征提取器\(f\)更新新中心。
4. Experiments
作者选用了两个测试数据集评估了提出的SLA框架:Office-Home和DomainNet。Office-Home主要用于测试无监督域适应和半监督域适应,包含了四个领域:艺术(A),剪切画(C),产品(P)和真实(R),共65个领域;DomainNet最初设计用于对多元域适应方法进行测试,选取了四个域:真实(R)、剪切画(C)、油画(P)和素描(S)以及126个类,为SSDA构建更清晰的数据集。
作者将自己的框架与\(MME\)和\(CDAC\)算法结合,分别命名为\(MME+SLA\)和\(CDAC+SLA\),为了对照比较,骨干网络选择\(ResNet34\)并预训练于ImageNet-1K数据集。并设计超参数:式(12)中混合比率\(\alpha=0.3\),式(7)中温度参数\(T=0.6\),3.3小节提到的区间\(I=500\),预热阶段的式(12)中,对于在Office-Home数据集,MME的\(W=500\),CDAC的\(W=3000\);对于在DomainNet数据集,MME的\(W=3000\),CDAC的\(W=50000\)。
在预热阶段之后,刷新学习率,以便使用更高的学习率更新标签适应损失;所有的超参数都可通过论证实验进行适当调整。对于每个子任务,进行了三次实验。
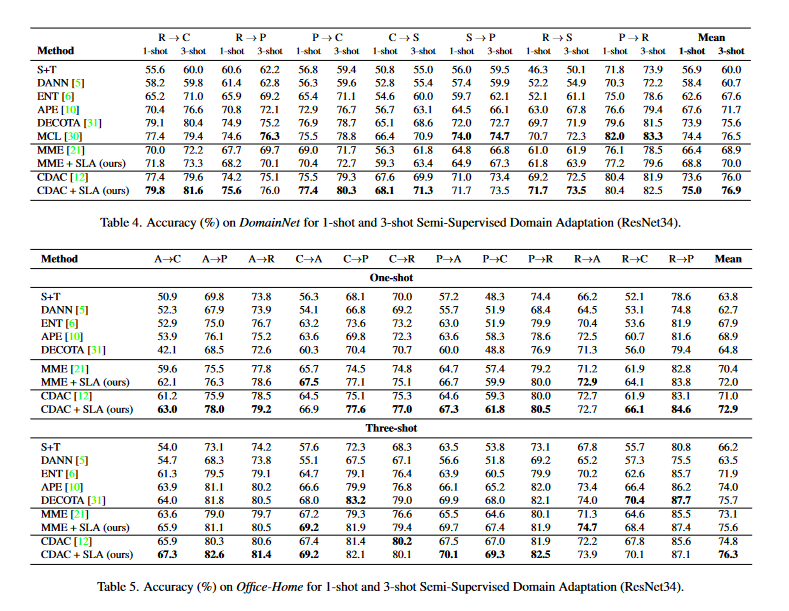
表4中作者的方法在DomainNet上对于应用了SLA的MME和CDAC几乎所有的例子都得到了提升。同样的,表5中作者的方法在Office-Home上对于应用了SLA的MME和CDAC几乎所有的例子都得到了提升。
作者之后还对部分超参数进行对照试验,确定合适的超参数选择,这里不再赘述。
5. Conclusion
- 本文展现了一种通用框架——具有源标签适应的半监督域适应。
- 要仔细重新审视源数据的使用。
- 从目标数据的角度来看,源数据标签可能含有噪声。作者将域适应视为噪声标签学习,并使用带有伪标签的Protonet预测结果纠正源数据标签(原文强调,作者解决的是一个正交(orthogonal)问题,现有的方法主要使目标数据与源数据保持一致,而论文的方法侧重于校正源数据的噪声标签)。
- 实验结果证明:将该框架应用于几种SSDA的SOTA,能够进一步提高性能。当由于每个类标记的数据较少,标记的目标数据中心\(C^{\ell}_f\)距离理想中心\(C^*_f\)较远,因此建议使用伪中心代替。
噪声标签学习(Noisy Label Learning):是指在监督机器学习任务中,训练数据的标签(即真实输出)存在一定程度的错误、不确定性或噪声的情况下,如何有效地训练模型以获得良好的性能。这种情况可能是因为数据收集过程中人为错误、数据注释不准确、标注者主观性等原因导致的。
ProtoNet(Prototype Network):ProtoNet 是一种用于Few-shot学习的模型,最早由Snell等人在论文 "Prototypical Networks for Few-shot Learning" 中提出。它的核心思想是通过计算每个类别的"原型"来进行分类。原型是指在特征空间中,对每个类别的样本特征求平均所得到的向量。在测试时,新样本将与各个类别的原型进行比较,从而选择最接近的类别作为预测结果。这种方法能够在少样本情况下进行有效分类。
Pseudo Centers(伪中心):Pseudo Centers 是一个类似原型的概念,它是在Few-shot学习中使用的一种补充方法。在某些情况下,数据分布可能不是完全均匀的,甚至可能有一些离群点。Pseudo Centers 的目的是为每个类别生成一组中心点,不同于原型,它们不仅考虑样本的平均特征,还考虑到其他特征,如中心、方差等,从而更好地捕捉数据分布的情况。

