
有监督学习——高斯过程
1. 高斯过程
高斯过程(Gaussian Process)是一种假设训练数据来自无限空间且各特征都符合高斯分布(高斯分布又称“正态分布”)的有监督学习。
高斯过程是一种概率模型,在回归或分类预测都以高斯分布标准差的方式给出预测置信区间估计。
随机过程
高斯过程应用于机器学习已有数十年历史,,它来源于数学中的随机过程(Stochastic Process)理论。随机过程是研究一组无限个随机变量内在规律的学科。
如果把每次采样的目标值\(y\)都看成一个随机变量,那么单条采样就是一个随机分布事件的结果,\(N\)条数据就是多个随机分布采样的结果,而整个被学习空间就是无数个随机变量构成的随机过程了。
Q: 为何将采样看成随机变量?
A: 一、所有数据的产生就是随机的;二、数据的采集有噪声存在。因此不可能给出精确值的预测,更合理的是给出一个置信区间。
无限维高斯分布
高斯分布或者说正态分布的特点:
- 可标准化:一个高斯分布可由均值\(\mu\)和标准差\(\sigma\)唯一确定,用符号\(\sim N(\mu,\sigma)\)表示。并且任意高斯分布可以转化用\(\mu=0\)和\(\sigma=1\)标准正态分布表达。
- 方便统计:高斯分布约67.27%的样本落在\((\mu-\sigma,\mu+\sigma)\),约95%的样本落在\((\mu-2\sigma,\mu+2\sigma)\),约99%的样本落在\((\mu-3\sigma,\mu+3\sigma)\)。
- 多元高斯分布(Multivariate Gaussian):\(n\)元高斯分布描述\(n\)个随机变量的联合概率分布,由均值向量\(<\mu_1,\mu_2,\cdots\mu_n>\)和协方差矩阵\(\sum\)唯一确定。其中\(\sum\)是一个\(n\times n\)的矩阵,每个矩阵元素描述\(n\)个随机变量两两间的协方差。
协方差(Covariance)用于衡量两个变量的总体误差。度量各个维度偏离其均值的程度。协方差的值如果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),结果为负值就说明负相关的,如果为0,也是就是统计上说的“相互独立”。方差就是协方差的一种特殊形式,当两个变量相同时,协方差就是方差了。协方差公式如下:
\(E\)为期望;\(X\)、\(Y\) 为两个变量;\(\mu_x\)、\(\mu_y\)分别代表\(X\)、\(Y\)均值。
期望值不等于平均值。期望值是衡量一个随机变量的中心趋势的加权平均数,是计算该变量的所有可能值,其中权重是每个值发生的概率。均值是一种特定类型的期望值,计算方法为变量的所有值除以值的总数之和。因此,虽然平均值是计算期望值的一种方法,但它不是唯一的方法,而且这两个术语是不可互换的。
- 和与差:设有任意两个独立的高斯分布\(U\)和\(V\),那么它们的和\(U+V\)一定是高斯分布,它们的差\(U-V\)也一定是高斯分布。
- 部分与整体:多分高斯分布的条件分布任然是多元高斯分布,也可理解为多元高斯分布的子集也是多元高斯分布。
上文说过:高斯过程可被看成无限维的多元高斯分布,那么机器学习的训练过程目标就是学习该无限维高斯分布的子集,也就是多元高斯分布的参数:均值向量\(<\mu_1,\mu_2,\cdots\mu_n>\)和协方差矩阵\(\sum\)。
协方差矩阵的元素表征两两元素之间的协方差,如果用核函数计算两者,便使得多元高斯分布也具有表征高维空间样本之间关系的能力。此时协方差矩阵可表示为:
其中\(K_{XX}\)表示样本数据特征集\(X\)的核函数矩阵;\(k()\)表示所选核函数;\(x_1,x_2,\cdots x_n\)等是单个样本特征向量。同\(SVM\)一样,此处核函数需要指定形式,常用的包括:径向基核、多项式核、线性核等。在训练过程中可以定义算法自动寻找核的最佳超参数。
设样本目标值\(Y\),被预测的变量\(Y_*\),由高斯分布的特型可知,由训练数据与被预测数据组成的随机变量集合仍然符合多元高斯分布,即:
其中\(u_*\)是代求变量\(Y_*\)的均值,\(K_{X_*X}\)是样本数据与预测数据特征的协方差矩阵,\(K_{X_*X_*}\)是预测数据特征的协方差矩阵。
由完美多元高斯特型可知\(Y_*\)满足高斯分布\(N(u_*,\sum)\),可直接用公式求得该分布的超参数,即预测值的期望值和方差:
与其他机器学习模型不同的是:高斯过程在预测中仍然需要原始训练数据,这导致该方法在高维特征和超多训练样本的场景下显得运算效率低,但因此高斯过程才能提供其他模型不具备的基于概率分布的预测。
对于白噪声的处理,就是在计算训练数据协方差矩阵\(K_{XX}\)的对角元素上增加噪声分量。因此协方差矩阵变为如下形似:
其中,\(\alpha\)是模型训练者需要定义的噪声估计参数。该值越大,模型抗噪声能力越强,但容易产生拟合不足。
在机器学习中,噪声是指真实标记与数据集中的实际标记间的偏差1,也就是数据本身的不确定性或随机性。白噪声是一种特殊的噪声,它具有以下特点:
- 白噪声是独立同分布的,也就是说每个样本的噪声都是相互独立且服从同一分布的。
- 白噪声的均值为零,也就是说每个样本的噪声都不会对真实标记产生系统性的偏移。
- 白噪声的方差为常数,也就是说每个样本的噪声都具有相同的波动程度。
- 白噪声和其他类型的噪声相比,更容易处理和分析,因为它不会引入额外的复杂性或相关性。
Python中使用高斯模型
在sklearn.gaussian_process.kernels中以类的方式提供了若干核函数,常用的如下表:
| 核函数 | 描述 |
|---|---|
| ConstantKernels | 常数核,对所有特征向量返回相同的值,即模型忽略了特征数据信息。 |
| DotProduct | 点积核,返回特征向量点积,也就是线性核。 |
| RBF | 径向基核,把特征向量提升到无限维以解决非线性问题。 |
此外,使用如下类,还允许不同核之间进行组合
| 组合核 | 描述 |
|---|---|
| Sum(k1,k2) | 用两个核分别计算后将模型相加 |
| Product(k1,k2) | 两个核分别运算后,结果相乘 |
| Exponentiation(k,exponent) | 返回核函数结果的指数运算结果,即\(k^{exponent}\) |
GaussianProcessRegressor与GaussianProcessClassifier分别表示python中的高斯过程回归模型和高斯过程分类模型。
与其他模型不同的是:它们的预测函数predict()有两个返回值,第一个为预测期望值,第二个为预测标准差。此外,以下为几个高斯过程特有的初始化参数:
| 参数 | 描述 |
|---|---|
| kernel | 核函数对象,即sklearn.gaussian_process.kernels中类的实例。 |
| alpha | 为了考虑样本噪声在协方差矩阵对角量增加值,可为数值(应用在所有对角线元素),也可以是一个向量(分别应用在每个对角元素上)。 |
| optimizer | 可以是一个函数,用于训练过程中优化核函数超参数 |
| n_restarts_optimizer | optimizer被调用的次数,默认为1 |
以下是对一个非线性函数\(y=x\times sin(x)-x\)的训练预测。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
from sklearn.gaussian_process.kernels import Product
from sklearn.gaussian_process.kernels import ConstantKernel as C
def f(X): # 原函数
return X * np.sin(X) - X
X = np.linspace(0, 10, 20).reshape(-1, 1) # 训练20个训练样本
y = np.squeeze(f(X) + np.random.normal(0, 0.5, X.shape[1])) # 样本目标值,并加入噪声
x = np.linspace(0, 10, 200) # 测试样本特征值
# 定义两个核函数,并取它们的积
kernel = Product(C(0.1), RBF(10, (1e-2, 1e2)))
# 初始化模型:传入核函数对象、优化次数、噪声超参数
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=3, alpha=0.3)
gp.fit(X, y) # 训练
y_pred, sigma = gp.predict(x.reshape(-1, 1), return_std=True) # 预测
fig = plt.figure() # matplotlib进行绘图
plt.plot(x, f(x), 'r:', label=u'$f(x) = x\,\sin(x)-x$')
plt.plot(X, y, 'r.', markersize=10, label=u'Observations')
plt.plot(x, y_pred, 'b-', label=u'Prediction')
# 填充(u-2σ,u+2σ)的置信区间
plt.fill_between(
np.concatenate([x, x[::-1]]),
np.concatenate([y_pred-2*sigma, (y_pred+2*sigma)[::-1]]),
alpha=0.3,
fc='b',
label=r"95% confidence interval"
)
plt.legend(loc='lower left')
plt.show()
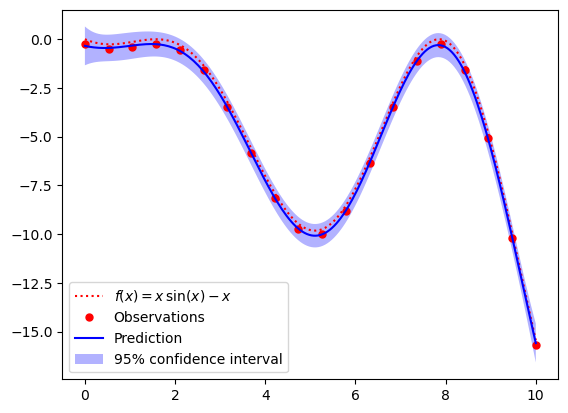
可以看到整体测试样本的真实虚线与测试的实线基本一致,即使有偏差但都在95%的置信区间内。
参考文献
[1]刘长龙. 从机器学习到深度学习[M]. 1. 电子工业出版社, 2019.3.

