布隆过滤器
简介
它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,
缺点是有一定的误识别率和删除困难。
主要作用就是判断是否存在,常用的方法有:
Map判断:效率慢,占用内存大
list判断:效率高,占用内存大
布隆过滤器:效率高,占用内存小,有误判。数据量巨大时,优先选用,因为占用内存小
原理
实际上布隆过滤器就是一个bit数组bit[m],现在我们新建一个长度为16的布隆过滤器,默认值都是0,就像下面这样:

元素比如字符串baidu通过k个hash函数计算出k个数字,然后将k个数字所在的下标都标注为1。
现在需要添加一个数据:
我们通过某种计算方式,比如Hash1,计算出了Hash1(数据)=5,我们就把下标为5的格子改成1,就像下面这样:

我们又通过某种计算方式,比如Hash2,计算出了Hash2(数据)=9,我们就把下标为9的格子改成1,就像下面这样:

还是通过某种计算方式,比如Hash3,计算出了Hash3(数据)=2,我们就把下标为2的格子改成1,就像下面这样:

这样,刚才添加的数据就占据了布隆过滤器“5”,“9”,“2”三个格子。
我们只需要将元素通过同样的hash函数计算出k个数字,然后在bit数组钟判断下标是否都为1就可以在误报率p内判断出该元素是否在布隆过滤器中存在了。
通过原理可以推导出布隆过滤器的优缺点:
- 优点:由于存放的不是完整的数据,所以占用的内存很少,而且新增,查询速度够快;
- 缺点: 随着数据的增加,误判率随之增加;无法做到删除数据;只能判断数据是否一定不存在,而无法判断数据是否一定存在。
当存入的数据量越来越大时,因为布隆过滤器中大部分位置都被标注为1,这个时候误判率就会增加,根据原理可以很容易的判断出可以增加hash函数k来增大成功几率。
布隆过滤器中的参数:k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
计算公式:
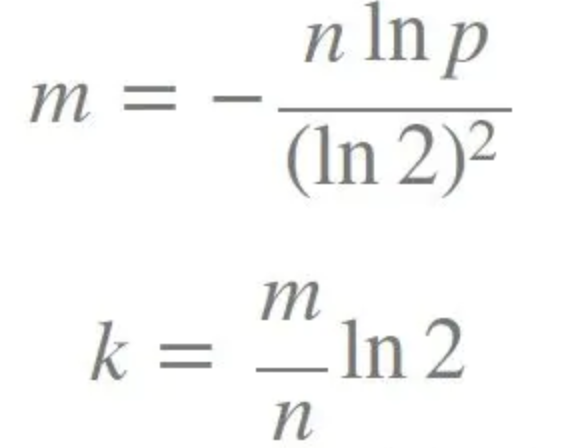
应用场景
-
redis缓存击穿,通过布隆过滤器判断key是否存在,不存在则直接返回,避免查库
-
url判断
-
秒杀判断是否重复购买
实现
guava实现布隆过滤器
引包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
然后就可以测试啦:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test {
//预计要插入多少数据
private static int size = 1000000;
//期望的误判率
private static double fpp = 0.01;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
//插入数据
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
int count = 0;
// 简单测算误判率 是否在设定范围内
for (int i = 1000000; i < 2000000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
System.out.println("误判率:" + count/1000000D);
}
}
上面这种方法存在缺点:
- 每次项目重启都需要重新将数据加入布隆过滤器中
- 分布式时需要每个集群节点都存储一份相同数据到布隆过滤器中
- 随着数据量加大,占用jvm内存
为解决这些问题,可以考虑使用redis作为布隆过滤器
redis实现布隆过滤器
上面使用guava实现布隆过滤器是把数据放在本地内存中,无法实现布隆过滤器的共享,我们还可以把数据放在redis中,用 redis来实现布隆过滤器,我们要使用的数据结构是bitmap,你可能会有疑问,redis支持五种数据结构:String,List,Hash,Set,ZSet,没有bitmap呀。没错,实际上bitmap的本质还是String。
可能有小伙伴会说,纳尼,布隆过滤器还没介绍完,怎么又出来一个bitmap,没事,你可以把bitmap就理解为一个二进制向量。
要用redis来实现布隆过滤器,我们需要自己设计映射函数,自己度量二进制向量的长度,这对我来说,无疑是一个不可能完成的任务,只能借助搜索引擎,下面直接放出代码把。
public class RedisMain {
static final int expectedInsertions = 1000;//要插入多少数据
static final double fpp = 0.01;//期望的误判率
//bit数组长度
private static long numBits;
//hash函数数量
private static int numHashFunctions;
static {
numBits = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
}
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
for (int i = 0; i < 1000; i++) {
long[] indexArray = getIndexArray(String.valueOf(i));
for (long index : indexArray) {
jedis.setbit("codebear:bloom", index, true);
}
}
int num = 0;
for (int i = 1000; i < 2000; i++) {
long[] indexArray = getIndexArray(String.valueOf(i));
for (long index : indexArray) {
if (!jedis.getbit("codebear:bloom", index)) {
System.out.println(i + "一定不存在");
num++;
break;
}
}
}
System.out.println("一定不存在的有" + num + "个");
}
/**
* 根据key获取bitmap下标
*/
private static long[] getIndexArray(String key) {
long hash1 = hash(key);
long hash2 = hash1 >>> 16;
long[] result = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
long combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
result[i] = combinedHash % numBits;
}
return result;
}
private static long hash(String key) {
return Hashing.MURMUR_HASH.hash(key);
}
//计算hash函数个数
private static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
//计算bit数组长度
private static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}
扩展 BitMap
bitmap也是利用bit数组来存储数据,因为bit只能为0,1,所以在只有true|false的存储场景可以使用bitmap实现。或者利用bit数组下标来存储特定的数据
使用bitMap最大的优势就是可以节约大量内存
比如典型场景:打卡签到
将打卡处设为1,未打卡处设为0,1年的打卡记录只需要365个bit位就可以存储
示例实现:
public class BitMap {
//保存数据的
private byte[] bits;
//能够存储多少数据
private int capacity;
public BitMap(int capacity){
this.capacity = capacity;
//1bit能存储8个数据,那么capacity数据需要多少个bit呢,capacity/8+1,右移3位相当于除以8
bits = new byte[(capacity >>3 )+1];
}
public void add(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。
bits[arrayIndex] |= 1 << position;
}
public boolean contain(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做&,判断是否为0即可
return (bits[arrayIndex] & (1 << position)) !=0;
}
public void clear(int num){
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后对取反,再与当前值做&,即可清除当前的位置了.
bits[arrayIndex] &= ~(1 << position);
}
public static void main(String[] args) {
BitMap bitmap = new BitMap(100);
bitmap.add(7);
System.out.println("插入7成功");
boolean isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
bitmap.clear(7);
isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
}
}
面试题
不安全网页的黑名单包含100亿个黑名单网页,每个网页的URL最多占用64字节。现在想要实现一种网页过滤系统,可以根据网页的URL判断该网站是否在黑名单上,请设计该系统。要求该系统允许有万分之一以下的判断失误率,并且使用的额外空间不要超过30G。
通过公式计算出 m k 然后利用布隆过滤器解决
参考博文
https://www.cnblogs.com/qdhxhz/p/11237246.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号