1-rocketmq简介-部署
简介
基于java开发,高可用
应用场景
1、应用解耦
2、流量销峰
3、异步处理
4、消息分发(邮件、短信、日志、数据处理)
延时队列场景:需要延时单次延迟执行的场景,比如订单取消
常见问题
1、如何保证高可用
集群部署
2、如何保证消息不丢失(消息的可靠性传输)
-
生产者丢失数据
开启生产者确认模式,确认发送成功了才对消费者可见
-
消息队列丢失数据
开启消息持久化,设置好刷盘策略
-
消费者丢失数据
假如是自动提交offset,消息投递后还没有消费完就会被更新offset
开启手动提交,确保消息消费完了才被确认 -
集群同步丢失
总结:发送者确认模式开启,消息持久化默认开启,消费者消费开启手动ack
3、消费者幂等(如何确保消息不被重复消费)
发送时消息重复
投递时消息重复
负载均衡时消息重复
解决:
- 业务层做幂等,重复消费不影响
- 记录消息messageId重复消息丢弃
4、如何保证消息顺序性
先保证入队有序性,然后消费者通过业务逻辑保证消息的顺序消费
对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | kafka |
|---|---|---|---|---|
| 开发语言 | java | erlang | java | scala |
| 单机吞吐量 | 万级 | 万级 | 10万级 | 10万级 |
| 时效性 | ms级 | us级 | ms级 | ms级以内 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广。 |
架构
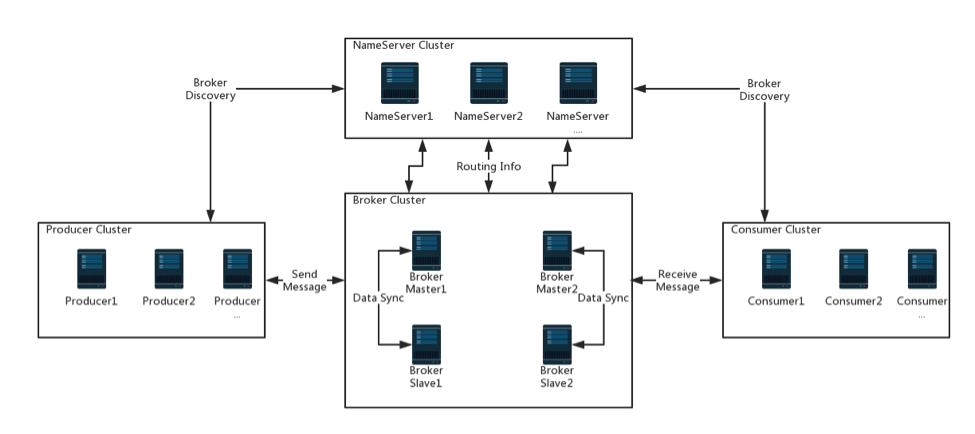
组要的四个组成部分
1、NameServer :可集群部署,节点之间无任何信息同步。提供轻量级的服务发现和路由
2、Broker :分为Master 与Slave,一个Master 可以对应多个Slave,但是一个Slave 只能对应一个Master。Master 与Slave 的对应关系通过指定相同的BrokerName,不同的BrokerId来定 义,BrokerId为0 表示Master,非0 表示Slave。Master 也可以部署多个。只有brokerId=1的从服务器才会参与消息的读负载,也就是当master挂掉后消费者依然能够正常消费,消费者挂掉后生产者依然能够正常发送消息
Broker主从没有自动选举,依靠配置文件brokerId来指定
3、Producer:拥有相同 Producer Group 的 Producer 组成一个集群, 与Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从Name Server 取Topic 路由信息,并向提供Topic服务的Master 建立长连接,且定时向Master 发送心跳。Producer 完全无状态,可集群部署。
4、Consumer :拥有相同 Consumer Group 的 Consumer 组成一个集群,与Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从Name Server 取Topic 路由信息,并向提供Topic 服务的Master、Slave 建立长连接,且定时向Master、Slave 发送心跳。Consumer既可以从Master 订阅消息,也可以从Slave 订阅消息,订阅规则由Broker 配置决定
部署
启动nameserver
nohup sh mqnamesrv &
启动broker
nohup sh bin/mqbroker -n ${namesrvIp}:9876 -c /conf/broker.conf &
-c可以指定broker.conf配置文件。默认情况下会加载conf/broker.conf
内存配置修改
修改runbroker.sh和runbroker.sh
JAVA_OPT="${JAVA_OPT} -server -Xms1g -Xmx1g -Xmn512g"
Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时间变慢。
Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常。
xmn 年轻代的heap大小,一般设置为Xmx的3、4分之一
Broker配置文件详解(broker.conf)
#nameserver地址
namesrvAddr= ip:port;ip:port
#Cluster名称,如果集群机器数比较多,可以分成多个cluster,每个cluster提供给不同的业务场景使用
brokerClusterName = DefaultCluster
#如果配置主从模式,master和slave需要配置相同的名称来表名关系
brokerName = broker-a
# 0master 1-slave
brokerId = 0
#在磁盘上保存消息的时长,单位是小时,自动删除超时的消息
fileReservedTime = 48
#与 fileReservedTim巳 参数呼应,表明在几点做消息删除动作,默认值 04 表示凌晨 4 点 。
deleteWhen = 04
#brokerRole 主从复制策略 有3种:
#SYNC MASTER
#ASYNC MASTER
#关键词 SY1叫C 和 ASYNC 表示 Master 和 Slave 之间同步消息的机制, SYNC 的意思是当 Slave 和 Master 消息同步完成后,再返回发送成功的状态 。
brokerRole = ASYNC_MASTER
#flushDiskType 表示刷 盘策略,分为 SYNC_FLUSH 和 ASYNC_FLUSH 两种,分别代表同步刷盘和异步刷盘 。 同步刷盘情况下,消息真正写人磁盘后再返回成功状态;异步刷盘情况下,消息写入 page_cache 后就返回成功状态 。
flushDiskType = ASYNC_FLUSH
#broker端口号
listenPort=10911
#topic不存在的情况下自动创建
autoCreateTopicEnable = true
#存储消息以及一些配置信息的根目录 每个broker需要配置不同的地址否则抛异常
#java.lang.RuntimeException: Lock failed,MQ already started
# at org.apache.rocketmq.store.DefaultMessageStore.start(DefaultMessageStore.java:227)
# at org.apache.rocketmq.broker.BrokerController.start(BrokerController.java:853)
# at org.apache.rocketmq.broker.BrokerStartup.start(BrokerStartup.java:64)
# at org.apache.rocketmq.broker.BrokerStartup.main(BrokerStartup.java:58)
storePathRootDir=/home/rocketmq/store-a
#所属集群名字 brokerClusterName=rocketmq-cluster
#broker名字,注意此处不同的配置文件填写的不一样 brokerName=broker-a或者broker-b
#0 表示 Master, >0 表示 Slave brokerId=0
#nameServer地址,分号分割 namesrvAddr=rocketmq-nameserver1:9876;rocketmq-nameserver2:9876
#在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaultTopicQueueNums=4
#是否允许 Broker 自动创建Topic,建议线下开启,线上关闭 autoCreateTopicEnable=true
#是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭 autoCreateSubscriptionGroup=true
#Broker 对外服务的监听端口 listenPort=10911
#删除文件时间点,默认凌晨 4点 deleteWhen=04
#文件保留时间,默认 48 小时 fileReservedTime=120
#commitLog每个文件的大小默认1G mapedFileSizeCommitLog=1073741824
#ConsumeQueue每个文件默认存30W条,根据业务情况调整 mapedFileSizeConsumeQueue=300000
#destroyMapedFileIntervalForcibly=120000
#redeleteHangedFileInterval=120000
#检测物理文件磁盘空间 diskMaxUsedSpaceRatio=88
#存储路径 storePathRootDir=/usr/local/rocketmq/store
#commitLog 存储路径 storePathCommitLog=/usr/local/rocketmq/store/commitlog
#消费队列存储路径存储路径 storePathConsumeQueue=/usr/local/rocketmq/store/consumequeue
#消息索引存储路径 storePathIndex=/usr/local/rocketmq/store/index
#checkpoint 文件存储路径 storeCheckpoint=/usr/local/rocketmq/store/checkpoint
#abort 文件存储路径 abortFile=/usr/local/rocketmq/store/abort
#限制的消息大小 maxMessageSize=65536
#flushCommitLogLeastPages=4
#flushConsumeQueueLeastPages=2
#flushCommitLogThoroughInterval=10000
#flushConsumeQueueThoroughInterval=60000
#Broker 的角色
#- ASYNC_MASTER 异步复制Master
#- SYNC_MASTER 同步双写Master
#- SLAVE brokerRole=ASYNC_MASTER
#刷盘方式
#- ASYNC_FLUSH 异步刷盘
#- SYNC_FLUSH 同步刷盘 flushDiskType=ASYNC_FLUSH
#checkTransactionMessageEnable=false
#发消息线程池数量
#sendMessageThreadPoolNums=128
#拉消息线程池数量
#pullMessageThreadPoolNums=128
配置文件设置好后通过命令指定配置文件路径启动Broker
nohup sh bin/mqbroker -c [配置文件路径] &
停止服务
sh mqshutdown broker
sh mqshutdown namesrv
集群
集群支持
RocketMQ天生对集群的支持非常友好
单Master
优点:除了配置简单没什么优点
缺点:不可靠,该机器重启或宕机,将导致整个服务不可用
多Master
优点:配置简单,性能最高
缺点:可能会有少量消息丢失(配置相关),单台机器重启或宕机期间,该机器下未被消费的消息在机器恢复前不可订阅,影响消息实时性
多Master多Slave
每个Master配一个Slave,有多对Master-Slave,集群采用异步复制方式,主备有短暂消息延迟,毫秒级
优点:性能同多Master几乎一样,实时性高,主备间切换对应用透明,不需人工干预
缺点:Master宕机或磁盘损坏时会有少量消息丢失
多Master多Slave
每个Master配一个Slave,有多对Master-Slave,集群采用同步双写方式,主备都写成功,向应用返回成功优点:服务可用性与数据可用性非常高
缺点:性能比异步集群略低,当前版本主宕备不能自动切换为主,需要注意的是,在RocketMQ里面,1台机器只能要么是Master,要么是Slave。这个在初始的机器配置里面,就定死了。不会像kafka那样存在master动态选举的功能。其中Master的broker id = 0,Slave
的broker id > 0。
有点类似于mysql的主从概念,master挂了以后,slave仍然可以提供读服务,但是由于有多主的存在,当一个master挂了以后,可以写到其他的master上
控制面板
代码:https://github.com/apache/rocketmq-externals/tree/master/rocketmq-console
文档:https://github.com/apache/rocketmq-externals/blob/master/rocketmq-console/doc/1_0_0/UserGuide_CN.md
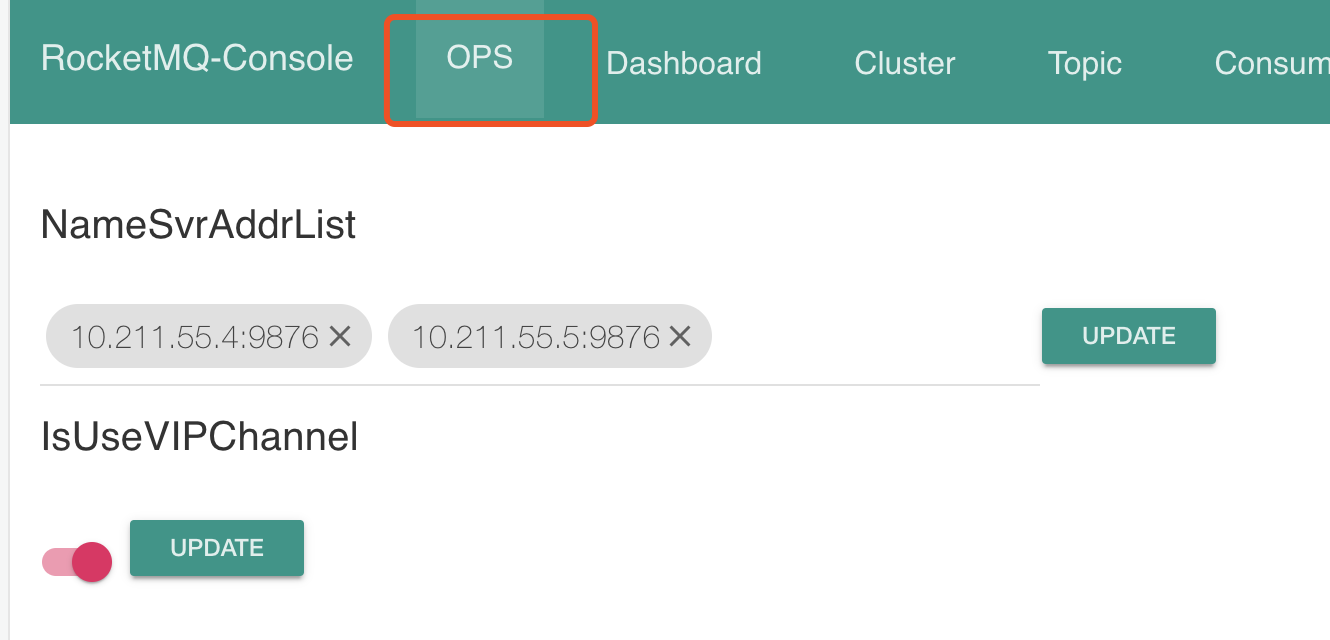
配置文件中指定其中一个namesrv地址
rocketmq.config.namesrvAddr=10.211.55.4:9876
或者后台手动更新
可以通过面板创建topic
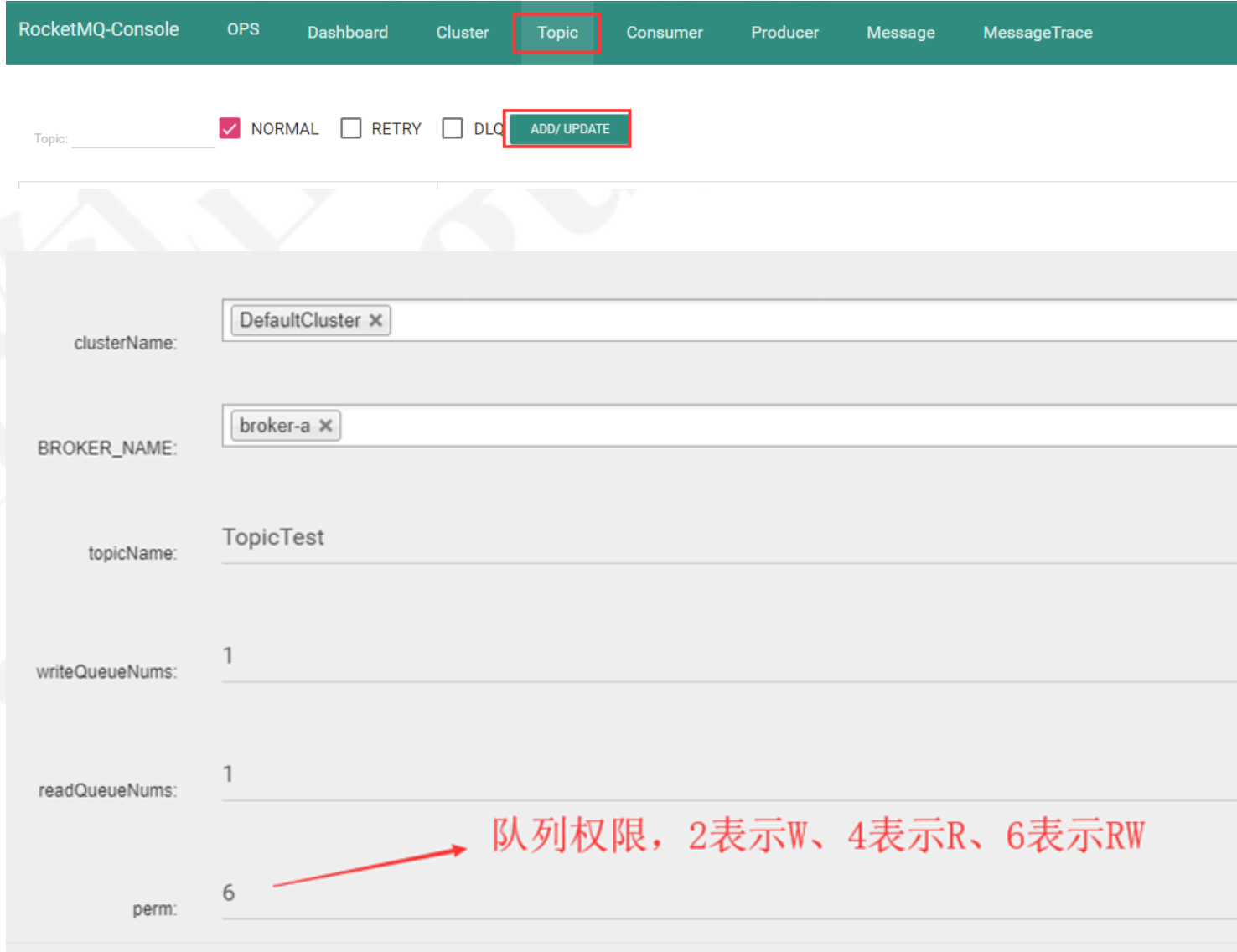
writeQueueNums表示producer发送到的MessageQueue的队列个数
readQueueNumbs表示Consumer读取消息的MessageQueue队列个数,其实类似于kafka的分区的概念
这两个值需要相等,在集群模式下如果不相等,假如说writeQueueNums=6,readQueueNums=3, 那么每个broker上会有3个queue的消息是无法消费的。
https://help.aliyun.com/document_detail/29532.html?spm=a2c4g.11186623.6.541.15be3af90vnILO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号