Redis深入解析系列:分布式锁详解
单机版实现
SET resource_name my_random_value NX PX 30000
失效时间保障锁最终会被释放,my_random_value 保证锁能被正确释放
释放锁操作用你lua脚本实现:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
在分布式环境中,单机模式就不再适用了,比如A从master获取锁后还没有同步到slave就宕机了,这个时候slave升级为master,B请求从新的master中获取到了锁,这个时候A和B同时持有锁。
Redlock算法:
为了解决分布式环境中的分布式锁问题,redis官方提出了redlock算法实现分布式锁
获取锁执行步骤:
1、获取当前时间
2、依次N个节点获取锁,并设置响应超时时间,防止单节点获取锁时间过长
3、锁有效时间=锁过期时间-获取锁耗费时间,如果第2步骤中获取成功的节点数大于
N/2+1,且锁有效时间大于0,则获得锁成功
4、若获得锁失败,则向所有节点释放锁
简单点说就是在锁过期时间内从半双以上的节点成功获取到了锁则说明获取锁成功。这个有点像注册中心的选举机制。
释放锁:
向所有节点发送释放命令即可
redlock的前提是所有节点时钟同步
redlock存在的问题
1、脑裂问题:就是多个客户端同时竞争同一把锁,最后全部失败。
比如有节点1、2、3、4、5,A、B、C同时竞争锁,A获得1、2,B获得3、4,C获得5,最后ABC都没有成功获得锁,没有获得半数以上的锁。官方的建议是尽量同时并发的向所有节点发送获取锁命令。客户端取得大部分Redis实例锁所花费的时间越短,脑裂出现的概率就会越低。
需要强调,当客户端从大多数Redis实例获取锁失败时,应该尽快地释放(部分)已经成功取到的锁,方便别的客户端去获取锁,假如释放锁失败了,就只能等待锁超时释放了
2、假设一共有5个Redis节点:A, B, C, D, E:
1) client1锁住A、B、C,没有锁D、E
2) C数据没有持久化就崩溃重启
3) client2锁住了C、D、E,获取锁成功
解决方案:C崩溃后延时重启,延时时间大于锁的过期时间
3、假设一共有5个Redis节点:A, B, C, D, E:
1. 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
2. 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
3. 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
4. 客户端1和客户端2现在都认为自己持有了锁。
这种情况redis作者认为需要通过加强运维来避免
Martin提出的问题:

1、client1持有锁时,发生了阻塞并且阻塞时间超过了锁的过期时间,这时锁被释放了。2、这时client2成功获取到了锁(这时相当于两个客户端同时持有了锁),提交了数据。
3、此时client1苏醒,又一次提交了数据。
解决方案,增加一个token-fencing:
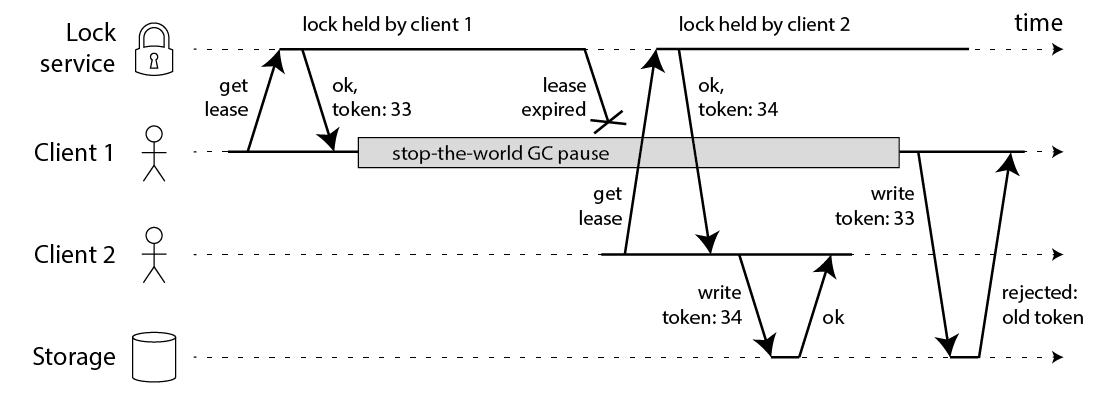
1、增加一个递增的token,client1获取锁时同时得到一个token=33
2、当阻塞问题发生时,client2获取锁得到了token=34
3、提交数据时需要判断token大小,token小于上次提交的token就拒绝
相当于加了一把乐观锁
(redis作者认为有了token其实就已经不再需要分布式锁了)
总结:
选用分布式锁时需要明确用途:
1、提升效率:避免一个任务被执行两次。但是就算执行了两次也不会出现致命问题
2、保证正确:一定要保证数据正确,不允许出现重复执行的情况
· 假如是为了提升效率而使用锁,则使用单机模式就足够了
· 假如是需要保证绝对的正确,redlock并不能达到目的。应该考虑类似Zookeeper的方案,或者支持事务的数据库。
参考:
http://www.redis.cn/topics/distlock.html
http://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号