
《java核心技术36讲》学习笔记-------杨晓峰(极客时间)
非常荣幸作为晓峰哥的同事,之前就看过这篇文章,重写读一遍,再学习学习。同时也推荐给大家

一、开篇词
初级、中级:java和计算机科学基础、开源框架的使用;高级、专家:java io/nio、并发、虚拟机、底层源码、分布式、安全、性能
java基础、java进阶、java应用开发扩展、java安全基础、java性能基础
第1讲:java平台的理解
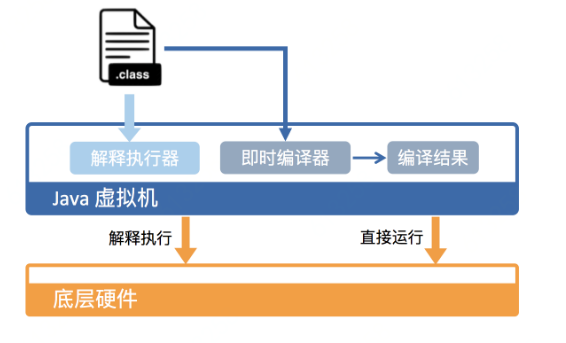
java编译器和运行时;
javac的编译:编译将java源码生成.class文件,实际是字节码,而不是可以直接执行的机器码。
运行时:JVM通过类加载器(Class-Loader)加载字节码,解释或者编译执行;解释器、编译器(JIT);
解释器:逐条读入,逐条解释运行的。
java虚拟机,指定不同的参数对运行模式可以进行选择。-Xint,告诉jvm只进行解释执行,不对代码进行编译,抛弃JIT可能带来的性能优势。-Xcomp,jvm关闭解释器,导致jvm启动变慢很多。
第2讲:Exception和Error的区别
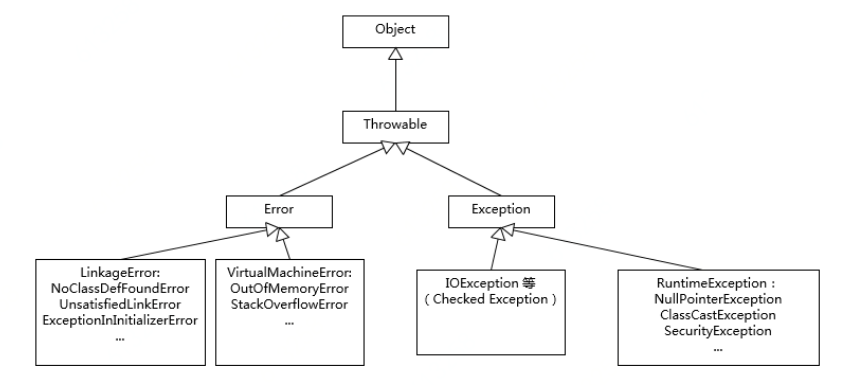
NoClassDefFoundError是一个错误(Error),而ClassNOtFoundException是一个异常,在Java中对于错误和异常的处理是不同的,我们可以从异常中恢复程序但却不应该尝试从错误中恢复程序。
(1)Error:系统错误,虚拟机出错,我们处理不了,也不需要我们来处理。
(2)Exception,可以捕获的异常,且作出处理。也就是要么捕获异常并作出处理,要么继续抛出异常。
第3讲:谈谈final、finally、finalize
final 可以用来修饰类、方法、变量,分别有不同的意义,final 修饰的 class 代表不可以继承扩展,final 的变量是不可以修改的,而 final 的方法也是不可以重写的(override)。
try-catch-finally
第4讲:引用
(1)强引用
特点:我们平常典型编码Object obj = new Object()中的obj就是强引用。通过关键字new创建的对象所关联的引用就是强引用。 当JVM内存空间不足,JVM宁愿抛出OutOfMemoryError运行时错误(OOM),使程序异常终止,也不会靠随意回收具有强引用的“存活”对象来解决内存不足的问题。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,具体回收时机还是要看垃圾收集策略。
(2)软引用
特点:软引用通过SoftReference类实现。 软引用的生命周期比强引用短一些。只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象:即JVM 会确保在抛出 OutOfMemoryError 之前,清理软引用指向的对象。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。后续,我们可以调用ReferenceQueue的poll()方法来检查是否有它所关心的对象被回收。如果队列为空,将返回一个null,否则该方法返回队列中前面的一个Reference对象。
应用场景:软引用通常用来实现内存敏感的缓存。如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
(3)弱引用
弱引用通过WeakReference类实现。 弱引用的生命周期比软引用短。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。由于垃圾回收器是一个优先级很低的线程,因此不一定会很快回收弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
应用场景:弱应用同样可用于内存敏感的缓存。
(4)虚引用
特点:虚引用也叫幻象引用,通过PhantomReference类来实现。无法通过虚引用访问对象的任何属性或函数。幻象引用仅仅是提供了一种确保对象被 finalize 以后,做某些事情的机制。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
ReferenceQueue queue = new ReferenceQueue ();
PhantomReference pr = new PhantomReference (object, queue);
程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取一些程序行动。
应用场景:可用来跟踪对象被垃圾回收器回收的活动,当一个虚引用关联的对象被垃圾收集器回收之前会收到一条系统通知。
第5讲:String、StringBuffer、StringBuilder区别
String:final class,所有属性也都是final。

StringBuffer:append 线程安全

StringBuilder:非线程安全

intern方法
https://www.cnblogs.com/Qian123/p/5702574.html
应用场景
[A]在字符串内容不经常发生变化的业务场景优先使用String类。例如:常量声明、少量的字符串拼接操作等。如果有大量的字符串内容拼接,避免使用String与String之间的“+”操作,因为这样会产生大量无用的中间对象,耗费空间且执行效率低下(新建对象、回收对象花费大量时间)。
[B]在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在多线程环境下,建议使用StringBuffer,例如XML解析、HTTP参数解析与封装。
[C]在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在单线程环境下,建议使用StringBuilder,例如SQL语句拼装、JSON封装等。
第6讲:动态代理
(1)反射机制
反射最大的作用之一就在于我们可以不在编译时知道某个对象的类型,而在运行时通过提供完整的”包名+类名.class”得到。注意:不是在编译时,而是在运行时。
利用Java反射机制我们可以加载一个运行时才得知名称的class,获悉其构造方法,并生成其对象实体,能对其fields设值并唤起其methods:运行时动态加载需要加载的对象
(2) 动态代理
public class MyDynamicProxy {
public static void main (String[] args) {
HelloImpl hello = new HelloImpl();
MyInvocationHandler handler = new MyInvocationHandler(hello);
// 构造代码实例
Hello proxyHello = (Hello) Proxy.newProxyInstance(HelloImpl.class.getClassLoader(), HelloImpl.class.getInterfaces(), handler);
// 调用代理方法
proxyHello.sayHello();
}
}
interface Hello {
void sayHello();
}
class HelloImpl implements Hello {
@Override
public void sayHello() {
System.out.println("Hello World");
}
}
class MyInvocationHandler implements InvocationHandler {
private Object target;
public MyInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("Invoking sayHello");
Object result = method.invoke(target, args);
return result;
}
}
https://blog.51cto.com/13586365/2065317
(3)cglib
第7讲 int和Interger 区别
8个原始数据类型:boolean、int、byte、short、char、int、float、double、long
包装类
原始类型线程安全:AtomicInteger、AtomicLong
原始数据类型和 Java 泛型并不能配合使用 Object

第8讲 Vector、ArrayList、LinkedList 区别
Vector:https://www.jianshu.com/p/f50307de72b1
ArrayList :http://www.importnew.com/19867.html
LinkedList :https://www.jianshu.com/p/d5ec2ff72b33
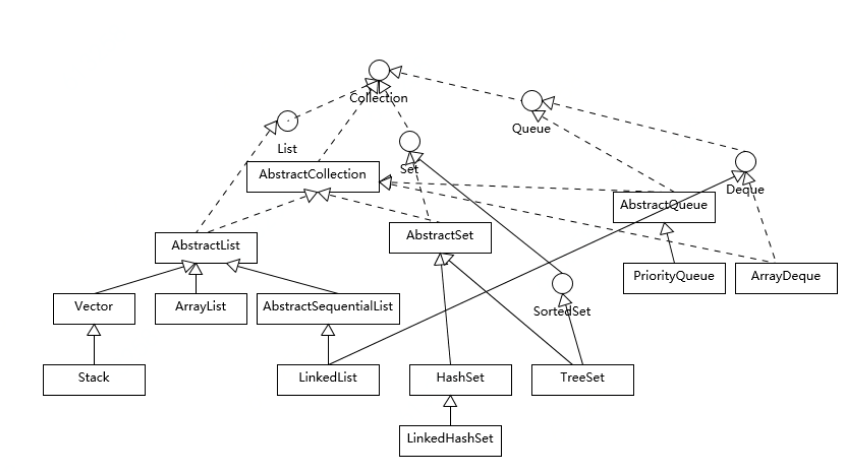
Vector、ArrayList、LinkedList均为线型的数据结构,但是从实现方式与应用场景中又存在差别。
1 底层实现方式
ArrayList内部用数组来实现;LinkedList内部采用双向链表实现;Vector内部用数组实现。
2 读写机制
ArrayList在执行插入元素是超过当前数组预定义的最大值时,数组需要扩容,扩容过程需要调用底层System.arraycopy()方法进行大量的数组复制操作;在删除元素时并不会减少数组的容量(如果需要缩小数组容量,可以调用trimToSize()方法);在查找元素时要遍历数组,对于非null的元素采取equals的方式寻找。
LinkedList在插入元素时,须创建一个新的Entry对象,并更新相应元素的前后元素的引用;在查找元素时,需遍历链表;在删除元素时,要遍历链表,找到要删除的元素,然后从链表上将此元素删除即可。
Vector与ArrayList仅在插入元素时容量扩充机制不一致。对于Vector,默认创建一个大小为10的Object数组,并将capacityIncrement设置为0;当插入元素数组大小不够时,如果capacityIncrement大于0,则将Object数组的大小扩大为现有size+capacityIncrement;如果capacityIncrement<=0,则将Object数组的大小扩大为现有大小的2倍。
3 读写效率
ArrayList对元素的增加和删除都会引起数组的内存分配空间动态发生变化。因此,对其进行插入和删除速度较慢,但检索速度很快。
LinkedList由于基于链表方式存放数据,增加和删除元素的速度较快,但是检索速度较慢。
4 线程安全性
ArrayList、LinkedList为非线程安全;Vector是基于synchronized实现的线程安全的ArrayList。
需要注意的是:单线程应尽量使用ArrayList,Vector因为同步会有性能损耗;即使在多线程环境下,我们可以利用Collections这个类中为我们提供的synchronizedList(List list)方法返回一个线程安全的同步列表对象。
问题回答
利用PriorityBlockingQueue或Disruptor可实现基于任务优先级为调度策略的执行调度系统。
第9讲 hashtable、HashMap、TreeMap 区别
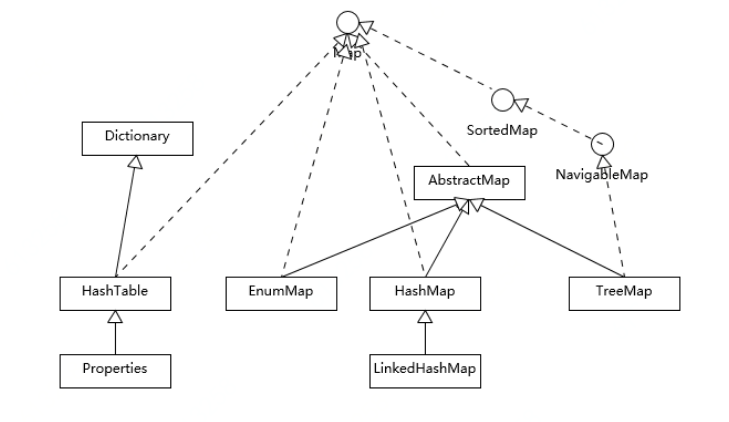
Hashtable: https://www.jianshu.com/p/526970086e4e
HashMap: http://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
TreeMap: https://www.jianshu.com/p/94acb78a8a4f
Hashtable、HashMap、TreeMap心得
三者均实现了Map接口,存储的内容是基于key-value的键值对映射,一个映射不能有重复的键,一个键最多只能映射一个值。
(1)元素特性
HashTable中的key、value都不能为null;HashMap中的key、value可以为null,很显然只能有一个key为null的键值对,但是允许有多个值为null的键值对;TreeMap中当未实现 Comparator 接口时,key 不可以为null;当实现 Comparator 接口时,若未对null情况进行判断,则key不可以为null,反之亦然。
(2)顺序特性
HashTable、HashMap具有无序特性。TreeMap是利用红黑树来实现的(树中的每个节点的值,都会大于或等于它的左子树种的所有节点的值,并且小于或等于它的右子树中的所有节点的值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需要排序的情况下是选择TreeMap来进行,默认为升序排序方式(深度优先搜索),可自定义实现Comparator接口实现排序方式。
(3)初始化与增长方式
初始化时:HashTable在不指定容量的情况下的默认容量为11,且不要求底层数组的容量一定要为2的整数次幂;HashMap默认容量为16,且要求容量一定为2的整数次幂。
扩容时:Hashtable将容量变为原来的2倍加1;HashMap扩容将容量变为原来的2倍。
(4)线程安全性
HashTable其方法函数都是同步的(采用synchronized修饰),不会出现两个线程同时对数据进行操作的情况,因此保证了线程安全性。也正因为如此,在多线程运行环境下效率表现非常低下。因为当一个线程访问HashTable的同步方法时,其他线程也访问同步方法就会进入阻塞状态。比如当一个线程在添加数据时候,另外一个线程即使执行获取其他数据的操作也必须被阻塞,大大降低了程序的运行效率,在新版本中已被废弃,不推荐使用。
HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步(1)可以用 Collections的synchronizedMap方法;(2)使用ConcurrentHashMap类,相较于HashTable锁住的是对象整体, ConcurrentHashMap基于lock实现锁分段技术。首先将Map存放的数据分成一段一段的存储方式,然后给每一段数据分配一把锁,当一个线程占用锁访问其中一个段的数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap不仅保证了多线程运行环境下的数据访问安全性,而且性能上有长足的提升。
(5)一段话HashMap
HashMap基于哈希思想,实现对数据的读写。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时,它们会储存在同一个bucket位置的链表中,可通过键对象的equals()方法用来找到键值对。如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),链表就会被改造为树形结构。
第10讲 集合的线程安全,ConcurrentHashMap
java.util.concurrent
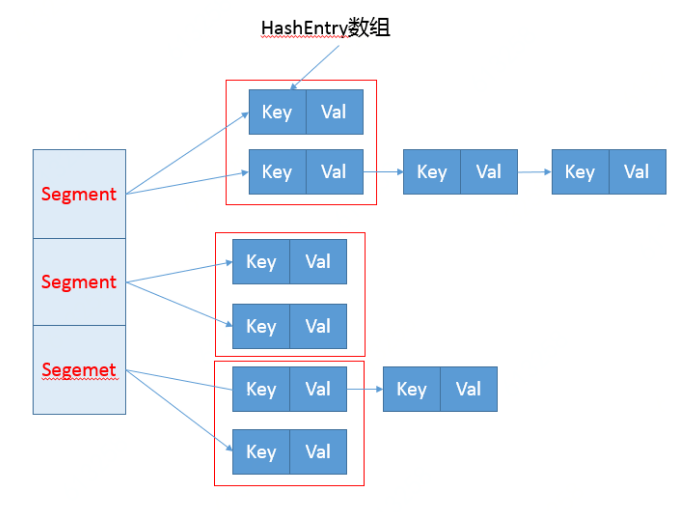
https://www.cnblogs.com/chengxiao/p/6842045.html
第11讲 java IO、NIO
同步与异步:同步操作,后续任务需要等待当前调用放回才能进行下一步;异步不需要
阻塞与非阻塞:


