

别名会帮助你设计更易于维护的数据索引,预先知道PB级大数据索引实战中的坑,提升工作效率。别名在Elasticsearch中有两种分类:索引别名和字段别名。
一、索引别名
官方释义:
索引别名可以指向一个或多个索引,并且可以在任何需要索引名称的API中使用。
别名为我们提供了极大的灵活性。它们允许我们执行以下操作:
1)在正在运行的集群上的一个索引和另一个索引之间透明切换;
2)对多个索引进行分组组合(例如,last_three_months的索引别名:是过去3个月索引logstash_201903, logstash_201904, logstash_201905的组合);
3)在索引中的文档子集上创建“视图”(结合业务场景,会提升检索效率)。
通俗解释:
索引别名类似:windows的快捷方式,linux的软链接,mysql的视图。
- 前提:Elasitcsearch创建索引后,索引名不允许改。很多业务场景下单一索引可能无法满足要求。
- 场景1:PB级别增量数据,借助rollover api实现,由基于日期的n个索引组成,显然,对外提供服务使用别名会很便捷。
- 场景2:试想,线上提供服务的某个索引出了问题,比如:某字段分词定义不准确,如何保证对外提供服务不停止(不更改业务代码)的前提下更换索引,显然,别名更合适。
注意:实际业务场景使用别名会很方便、灵活、快捷、业务松耦合!!
二、字段别名
在Elasticsearch Mapping定义的6.4+版本才有的字段类型。通俗解释:
试想一下有一种业务场景。比如在实际的业务开发中:需要对Facebook、twitter行采集,采集入库的是两个业务团队。他们对content,分别使用了两个字段。其中一个是,content。另外一个是cont。
这时候存储到elasticsearch会有两个字段。这样如果我们在检索、写业务代码的时候,是不是要写两个不同的字段来处理呢?
如果有可能写成一个字段,代码方面就很避开业务耦合,很方便了。
三、索引别名实践
- 步骤1:别名关联已有索引:

POST /_aliases?pretty { "actions": [ { "add": { "index": "visitor_logs_2017", "alias": "visitor_logs" } }, { "add": { "index": "visitor_logs_2018", "alias": "visitor_logs" } } ] }
- 步骤2:使用别名检索:
GET /visitor_logs/_search
四、索引别名的作用
1、大数据管理
场景: 实战中,可能需要基于时间的数据保留策略(利用rollover机制实现),并从系统中删除旧数据。
使用索引别名:
- 好处1:来简化从Elasticsearch中删除数据的过程。
- 好处2:在没有任何停机时间的情况下从Elasticsearch中删除最旧的数据,不会出现任何查询中断,也不会进行任何客户端更改。
基于时间索引的实现机制如下:
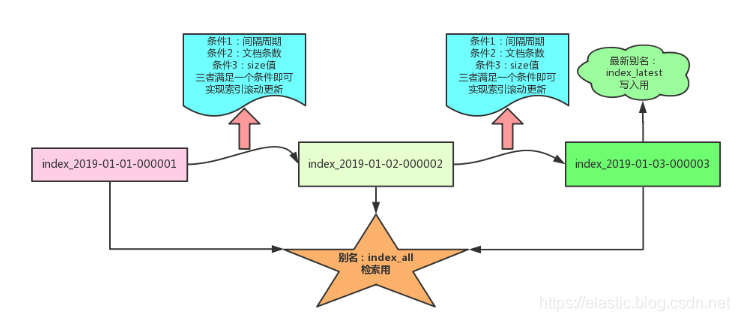
试想一下:如果不是基于时间的索引,而使用大索引,删除历史数据会发生什么?
答案:
- 删除索引数据只能使用:delete_by_query,相比删除索引,delete_by_query删除数据只是逻辑删除;
- 真正的删除实际是段合并后的物理删除分段,也就是delete_by_query后,有一段时间磁盘空间不降反升。此时的检索效率会非常低。
2、用户无感知的重建索引
实战中,索引的设计可能不是一步到位。随着业务的扩展,可能会在开发的中后期,调整索引Mapping结构,
比如:
- ik_smart改成ik_max_word分词以高效分词,
- long类型改成keyword以提升检索效率,
- 修改索引分片数以便于机器横向扩展,
- 索引分成更小粒度的索引等以提升性能。
通常的做法,都需要借助:reindex操作完成索引的迁移。
如果要确保线上环境的可靠运行且用户无感知(即无需告知用户,不影响用户的业务),使用别名指向更改前和更改后的索引是绝佳方案。
实战举例:
POST /_aliases?pretty { "actions": [ { "remove": { "index": "visitor_logs_2018", "alias": "visitor_logs" } }, { "add": { "index": "visitor_logs_2018_01", "alias": "visitor_logs" } } ] }
试想一下,如果没有索引别名呢?
答案:
- 无法保证查询的连续性;
- 无法保证线上业务查询的可靠性(需要告知用户,业务中断一段时间)。
五、索引别名常见问题及坑解读
问题1:ES批量插入可以使用别名插入吗?
会报错:no write index is defined for alias [xxx]. ...
注意:索引别名不是在任何地方都通用。写入或更新数据的时候需要指明物理索引,不要向别名写入数据。
问题2:ES怎么获取所有别名信息 alias
如何通过索引别名查找实际索引名称?
GET _cat/aliases
问题3:使用别名和基于索引效率一样吗?
是一致的。前提:索引和别名指向相同的数据,相同的检索条件。
原理:索引别名只是物理索引的软链接名称而已。
问题4:如何使用别名提升检索效率?
-
方式一:基于时间创建索引,指定多索引别名。
比如分为:近1年索引别名,近3个月索引别名,近1个月索引别名,近1周索引别名,近3天索引别名。
检索的时候,先敲定时间范围,然后在指定范围的别名下检索。
核心原理:物理上基于时间做了分隔,再加上冷热数据分离机制,会极大缩小了检索样本。 -
方式二:使用filter 别名或者 路由别名机制,提升效率。
filter Alias上代码,实际业务中极易被忽视,但会极大提升效率。
POST /_aliases { "actions" : [ { "add" : { "index" : "test1", "alias" : "alias2", "filter" : { "term" : { "user" : "kimchy" } } } } ] }

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步