

更多技术博客,请关注微信公众号:运维之美
1、get方法
举例:抓取豆瓣排行榜
from email import header
import requests
url='https://movie.douban.com/j/new_search_subjects'
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
Param={
'sort': 'U',
'range': '0,10',
'tags':'',
'start': 0
}
resp=requests.get(url,params=Param,headers=header)
print(resp.text)
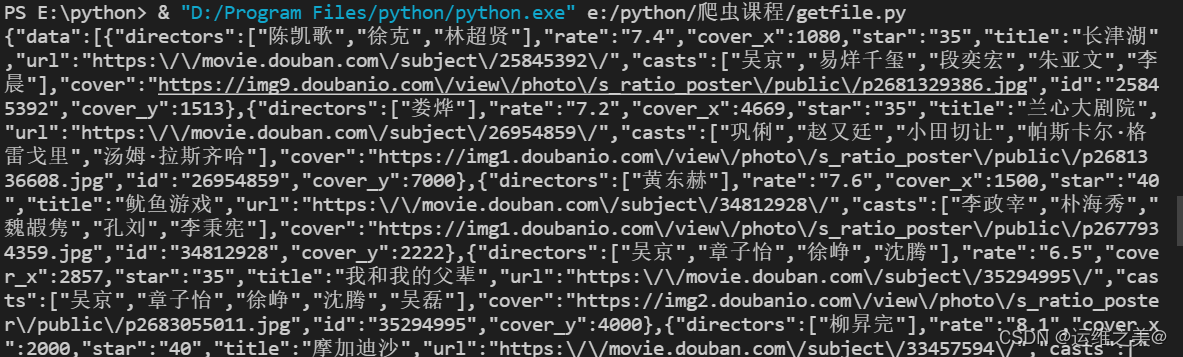
2、post方法
#!/usr/bin/env python
from email import header
import requests
url= "https://fanyi.youdao.com/translate"
paylod={
'i': '中国',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16487427921580',
'sign': '557e98b1b334eea2bc873c2a95a4d9d4',
'lts': '1648742792158',
'bv': 'e8f74db749b4a06c7bd041e0d09507d4',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
resp=requests.post(url=url,data=paylod,headers=header)
print(resp.text)

3、总结
-
get请求中带的参数为params,post使用的参数为data(F12中为paylod或者from data),具体参数可以从F12中获取
-
如果脚本运行后返回为空,可能是被反扒了,可以在请求中带上User-Agent参数
-
params理解为url中?后的拼接地址,加上参数后,url get中请求会重组,可以用print(resp.request.url来查看完整请求)
-
print(resp.request.headers)可以打印python运行的默认header信息,会被服务器认为是程序发起而反扒,所以需要修改。
默认header
-``
{‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36’, ‘Accept-Encoding’: ‘gzip, deflate’, ‘Accept’: ‘/’, ‘Connection’: ‘keep-alive’, ‘Content-Length’: ‘252’, ‘Content-Type’: ‘application/x-www-form-urlencoded’}`


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫