

Selenium 报表自动化测试——黑盒测试篇
https://testerhome.com/topics/10742
背景
公司的ERP系统有很多报表页面,每个月都会有一两个报表的功能进行修改,页面查询条件很多,
功能测试的同事尽可能的穷举出各种参数组合去查询,但由于参数组合的数量太大,人工测试的用例只能算九牛一毛,
依然有大部分漏测的场景可能发现问题,上线之后被用户投诉。
基于这个背景,引入自动化测试,旨在通过程序穷举出各种查询场景自动进行测试,并记录各场景的测试结果。
需求
从背景中收集到以下需求:
- 页面上有很多查询条件
- 穷举查询条件的组合
- 记录各组合的测试结果
分析
先看看页面长什么样子。
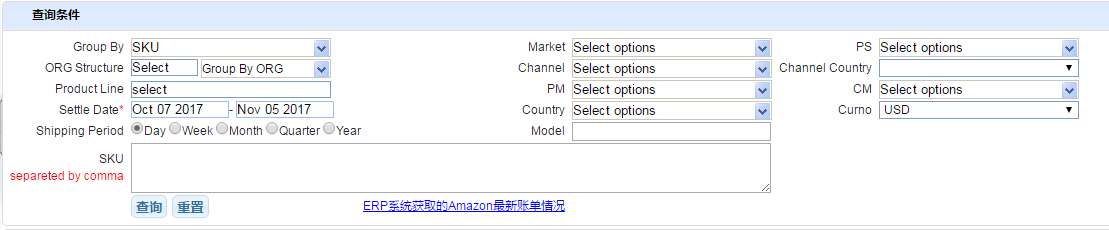
由此页面我们可以得出参数的大致列表:
<aa></aa>
<bb></bb>
<cc></cc>
<dd></dd>
<ee></ee>
……
我们把这些参数进行组合,(此处省略N字。。。组合公式自行去查阅资料)可以得到以下数量
组合数量 = 2的参数个数次幂-1
假设页面有3个参数aa,bb,cc,那么组合出来的参数为:{[aa], [bb], [cc], [aa,bb], [aa,cc], [bb,cc], [aa,bb,cc]}
如果页面有10个参数,则这些参数组合的数量为:2的10次方-1 = 1023
但上面求出来的数量仅仅只是参数的值为固定数量的组合个数,但实际上某个参数的取值可能是以下情况:
<aa>value1,value2,value3</aa>
or
<aa>value1</aa>
or
<aa>value1,value2</aa>
or
……
我们可以得知
页面条件组合出来的数量无穷大!!!
解决思路
从实际场景出发,了解业务初衷
我们从上面的分析可以得出一个结论,这是一个看似无法完成的任务。怎么把一个理论上来说不可能完成
的任务,变成一个可行的解决方案,就需要我们对实际的业务进行分析了。
先说自动化面临的问题:
- 自动化用例量庞大。假设页面有10个参数,每个参数固定一个值,则有1023个组合
- 自动化用例耗时长。一个完整的页面输入参数点击查询的用例大概需要5~10秒的时间,再乘以以千为单位的用例个数。。。 不说其他,单这两项就够秒杀该功能不适合做自动化的。 怎么办呢?竟然正常的路走不通,那我们就想点非常规的路子。
咱们不妨抛开业务,想想什么自动化用例才是好用例:
- 脚本通用,一份脚本支持所有用例执行。

- 脚本执行时间短,最好分分钟跑完。

- 覆盖更多测试场景,这个当然是越多越好。

回到正题,竟然这个业务本身就非常特殊,我们就没有必要去遵循自动化用例的设计原则了,直接按照我们心目中的完美用例去实现。
- 脚本通用。我们可以写一份脚本,然后通过循环读取参数去页面查询。
- 执行时间。如此庞大的用例量自然无法通过人工来写的,我们就想办法通过程序去自动生成用例。
- 覆盖度高。从业务角度来设置查询场景,如:参数全设置查询,参数不设置查询,等各种场景。
解决方案
最终我们得出一个比较满意的测试解决方案:
- 使用数据驱动模式,维护参数配置文件,一份代码,所有用例都可执行
- 测试用例通过参数组合生成,提供开关控制用例生成数量
- 指定场景测试+随机测试(从参数组合中抓取随机数量的组合)
测试流程图
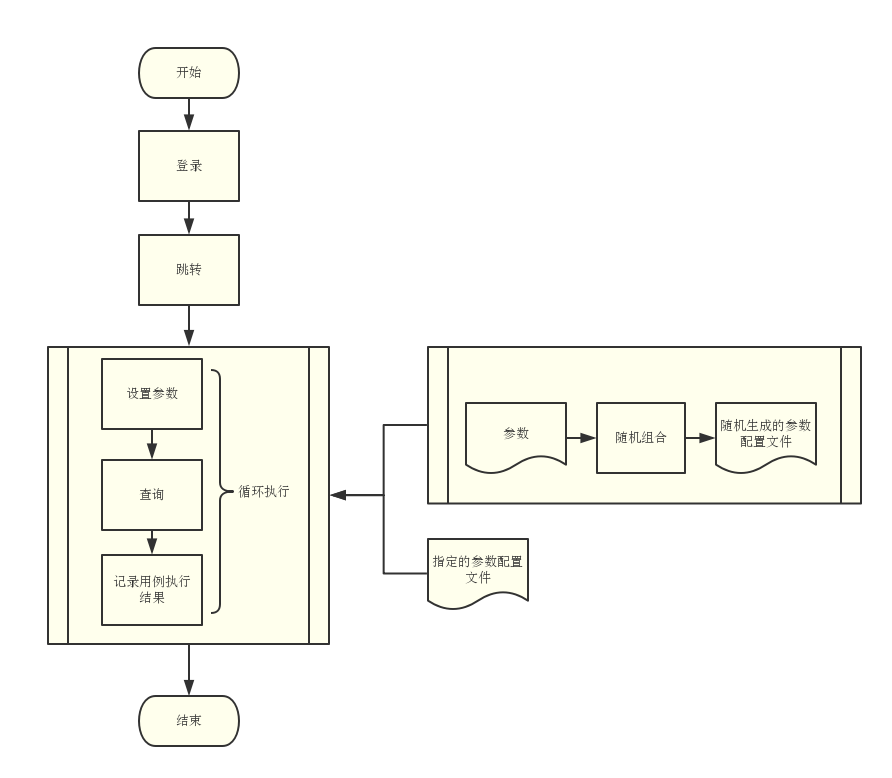
实现的功能
- 代码与业务分离。不再需要写大量场景的自动化用例代码,仅需维护参数配置文件
- 测试用例根据配置文件中的参数随机生成测试场景,场景数量可控(配置文件提供指定数量)
- 2层随机机制(查询条件随机组合,查询条件中具体条件中的值随机组合),保证了场景的覆盖度
- 2种测试方式(随机场景测试,指定场景测试)
- 明确的测试结果。只关注点击查询后的页面结果,忽略自动化操作页面元素失败干扰测试结果(用例在页面操作失败依然往下执行)
用例代码
public class RandomParamatersQueryTest {
private WebDriver webDriver = null;
private SoftAssert softAssert = new SoftAssert();
WebManager webManager = null;
WebElementCheck webCheck = null;
@Test
public void randomParamatersQueryTest() {
String parameterXmlPath = ConfigReader.getInstance().getValue("parameterXmlPath");
String randomCaseXmlPath = ConfigReader.getInstance().getValue("randomCaseXmlPath");
String randomexcelPath = ConfigReader.getInstance().getValue("randomexcelPath");
// 使用Firefox浏览器
webDriver = WebDriverManager.GetDriver(BroswerType.FIREFOX);
webManager = new WebManager(webDriver, softAssert);
webCheck = new WebElementCheck(webDriver, softAssert);
PublicMethod common = new PublicMethod(webManager, webCheck);
SalesReport sReport = new SalesReport(webManager);
// 登录、跳转到指定报表页
common.login(ConfigReader.getInstance().getValue("loginURL"), ConfigReader.getInstance().getValue("loginEmail"),
ConfigReader.getInstance().getValue("loginPassword"));
sReport.navigateToSalesReport();
sReport.switchToFrame();
// 参数生成参数配置文件
ReportProvider.saveParamatersToCaseXML(parameterXmlPath, randomCaseXmlPath);
webManager.threadWait(3);
// 读取参数配置文件,做UI自动化测试
XmlReader xmlReader = XmlReader.getInstance(randomCaseXmlPath);
// 创建测试报告Excel
String reportName = "sales report";
ExcelOperate.getInstance().createExcel(reportName, randomexcelPath);
List<String> configIds = xmlReader.getAttributeValue("id");
for (String configId : configIds) {
try {
// 设置查询参数
sReport.setQueryParas(randomCaseXmlPath, configId);
sReport.clickSearch();
try {
// 判断错误提示框是否出现,如果出现,判定该用例执行失败
webManager.dynamicWaitAppearAndThrowException(WebElementType.XPATH,
"//div[@class='ui-dialog ui-widget ui-widget-content ui-corner-all ui-draggable ui-resizable']",
2);
webManager.threadWait(1);
String message = webCheck.getProperty(WebElementType.XPATH, "//div[@id='alert_dialog']",
CheckPropertyType.INNERTEXT);
ExcelOperate.getInstance().excelWrite2003(randomexcelPath, ExcelUpdateMode.ADD, reportName,
configId, "fail", message);
} catch (Exception e) {
// 错误框未出现,判定用例执行成功
ExcelOperate.getInstance().excelWrite2003(randomexcelPath, ExcelUpdateMode.ADD, reportName,
configId, "success", "");
} finally {
webManager.refreshBroswer();
sReport.navigateToSalesReport();
sReport.switchToFrame();
}
} catch (Exception e) {
// 任何错误都不抛出,保证用例的循环执行
}
}
common.logout();
}
}
两种测试方式
随机测试与指定测试的区别在于用例配置文件一个是根据参数随机生成,一个是用户自己指定场景的参数
随机测试
参数文件
<?xml version="1.0" encoding="UTF-8"?>
<Testcases xmlns="testcase">
<parameters>
<grouptype>1,2,3</grouptype>
<market>504</market>
<ps>2877</ps>
<orggroupby>1,2,3,4,5</orggroupby>
<channel>287</channel>
<channelcountry></channelcountry>
<productline></productline>
<pm></pm>
<cm>2877</cm>
<salesdate>2017-02-01,2017-02-02</salesdate>
<country>US,UK,FR</country>
<curno>USD</curno>
<shippingperiod>1</shippingperiod>
<model>TT-BH07</model>
<sku>53-10007-001</sku>
</parameters>
</Testcases>
生成的随机测试参数配置文件每次都会改变,这样保证了用例的场景覆盖度(生成的case数量可控,在配置文件中设置即可)
<?xml version="1.0" encoding="UTF-8"?>
<Testcases xmlns="testcase">
<Testcase xmlns="" id="case1">
<country>US,UK,FR</country>
<channel>287</channel>
<curno>USD</curno>
<shippingperiod>1</shippingperiod>
<grouptype>1,2,3</grouptype>
<salesdatefrom>2017-02-01</salesdatefrom>
<salesdateto>2017-02-02</salesdateto>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case2">
<cm>2877</cm>
<shippingperiod>1</shippingperiod>
</Testcase>
<Testcase xmlns="" id="case3">
<country>US,UK,FR</country>
<ps>2877</ps>
<cm>2877</cm>
<curno>USD</curno>
<market>504</market>
<orggroupby>1,2,3,4,5</orggroupby>
<salesdatefrom>2017-02-01</salesdatefrom>
<salesdateto>2017-02-02</salesdateto>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case4">
<country>US,UK,FR</country>
<channel>287</channel>
<cm>2877</cm>
<market>504</market>
<grouptype>1,2,3</grouptype>
<orggroupby>1,2,3,4,5</orggroupby>
<salesdatefrom>2017-02-01</salesdatefrom>
<salesdateto>2017-02-02</salesdateto>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case5">
<shippingperiod>1</shippingperiod>
<market>504</market>
<orggroupby>1,2,3,4,5</orggroupby>
<model>TT-BH07</model>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case6">
<country>US,UK,FR</country>
<channel>287</channel>
<curno>USD</curno>
<shippingperiod>1</shippingperiod>
<model>TT-BH07</model>
</Testcase>
<Testcase xmlns="" id="case7">
<country>US,UK,FR</country>
<ps>2877</ps>
<channel>287</channel>
<curno>USD</curno>
<market>504</market>
<orggroupby>1,2,3,4,5</orggroupby>
<model>TT-BH07</model>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case8">
<cm>2877</cm>
<curno>USD</curno>
<market>504</market>
<grouptype>1,2,3</grouptype>
<salesdatefrom>2017-02-01</salesdatefrom>
<salesdateto>2017-02-02</salesdateto>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case9">
<country>US,UK,FR</country>
<ps>2877</ps>
<curno>USD</curno>
<shippingperiod>1</shippingperiod>
<market>504</market>
<grouptype>1,2,3</grouptype>
<model>TT-BH07</model>
<sku>53-10007-001</sku>
</Testcase>
<Testcase xmlns="" id="case10">
<ps>2877</ps>
<curno>USD</curno>
<market>504</market>
<model>TT-BH07</model>
</Testcase>
</Testcases>
指定测试
参数文件
<?xml version="1.0" encoding="UTF-8"?>
<Testcases xmlns="testcase">
<Testcase id="allparamaters">
<grouptype>1,2,3,4,5,6,7,8,9,53,54,55</grouptype>
<market>504</market>
<ps>3817,3782,2877,1620,3619,3661</ps>
<orglist>1,2,3,4,5</orglist>
<channel>12</channel>
<channelcountry></channelcountry>
<productline></productline>
<pm>3660,3619,1620,2887,3813</pm>
<cm>3661,2877,3782,1620,3817</cm>
<salesdatefrom>2017-02-01</salesdatefrom>
<salesdateto>2017-02-02</salesdateto>
<country>CA,CN,DE,ES,FR,HK,IT,JP,UK,US</country>
<curno></curno>
<shippingperiod></shippingperiod>
<model></model>
<sku></sku>
</Testcase>
<Testcase id="noneparamaters">
<grouptype></grouptype>
<market></market>
<ps></ps>
<orglist></orglist>
<channel></channel>
<channelcountry></channelcountry>
<productline></productline>
<pm></pm>
<cm></cm>
<salesdatefrom></salesdatefrom>
<salesdateto></salesdateto>
<country></country>
<curno></curno>
<shippingperiod></shippingperiod>
<model></model>
<sku></sku>
</Testcase>
</Testcases>
总结
通过指定测试场景与随机测试场景,达到报表黑盒自动化测试的目的。
结尾
下一篇将分享报表数据初始化的流程,对数据进行白盒自动化测试。
有两种测试机制的,指定测试和随机测试。
基于业务背景:
我们会把典型场景的参数配置在指定配置文件中。这一块执行完后,我们在业务上认可其可达到90%的覆盖度。
再通过参数组合出场景,生成测试场景的参数用例。理论上讲,只要有足够的资源,不用随机抽取数量,直接全跑,肯定可以达到100%覆盖的。
但实际情况是这些耗时的用例,性价比并不高,收益也很低,而且需要非常大的成本。
所以我们提供一个可设置的随机数量阀值,找到一个平衡的随机数值,抽取用例进行测试。每次执行随机测试,都用这部分随机用例去提高剩下10%的覆盖度
建议你还是去看看正交覆盖法、all-pairwise算法,然后回头再来审视自己的做法
case组合用正交法 或 all-pairwise 生成case,个人更加倾向正交法;其次,我觉得这块主要测试的是数据,没必要使用UI,直接采用 字段case组合 + 接口请求+ 监测sql执行语句 比对 可能效率更高
设计思路:从参数配置文件中读取参数,生成参数组合的case,读取case中参数值,通过selenium、js、jQuery等手段将该值设置到UI对应的条件中进行查询。如此,一份代码即可执行所有场景的测试用例。
文中黑盒测试的重点是:对页面的条件进行组合后单击查询按钮。这是一个大数据量的操作,因此不对返回数据做校验,只看本次组合的条件在页面是否可正常使用。如果查询失败,系统会有弹出框提示失败原因,这个应该很好理解的。我们抓取这个框是否在一定的时间内出现,如果出现则判定本次查询失败,记录用例结果。
涉及到数据校验,需要做指定的校验处理,不适合随机性的测试。比如使用什么条件,查询了多少条数据出来,通过xpath、css、id、name等等方式得到页面查询出来的值,然后再对其进行验证。
涉及大量业务数据的校验,不适合做黑盒的测试。
另外从你的描述来看,校验的逻辑也会非常多,UI自动化需要写太多校验代码,事倍功半。
你可以考虑从接口测试下手,接口测试在校验方面很简单,直接对response的结果做对比就行。
接口测试你可以考虑postman,现在网上也有很多开源的接口测试平台,都可以满足你的需求。如果不想用别人的工具,也可以自己写框架,python的话可以使用request库,java的话,用httpclient类。都可以做接口测试的
其实我这边的业务刚好是对数据校验这块问题比较注重,你有什么样比较通用的接口测试方法吗?
先简单介绍下我的情况,需求那边有很频繁的报表提测任务,而且经常是新增报表,数据源来源于比较复杂的业务方数据表,所以做统计的过程经常是很多表进行关联各种条件查询,如果每次都检查开发的sql取数逻辑,一个报表就需要花费比较多的测试时间了
报表查询确实很难穷尽,但用户又会用各种你预想不到的组合进行查询
all-pairwise难道已经被人忘记了么
靠随机,还说能保证覆盖率?
UI报表自动化怎么造数据?数据源怎么来的,UI上操作吗,我去年做的方案是接口自动化来实现


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!