3、K-近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法
1、定义:如果一个样本在特征空间中的k个最近似(即特征空间中最临近)的样本中大多数属于某一类别,则该样本也属于这个类别。
2、计算公式: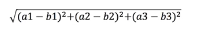 ;
;
3、K-近邻算法需要做标准化处理;
4、K-近邻算法API
5、优点:
1)简单、无需参数处理、无需训练
6、缺点:
1)懒惰算法,对测试样本分类时的计算量大,内存开销大;
2)必须指定k值,k值的选择不当则分类精度不能保证;
7、使用场景:小数据量,几千~几万个样本。
8、加快搜索速度——基于算法的改进KDTree。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号