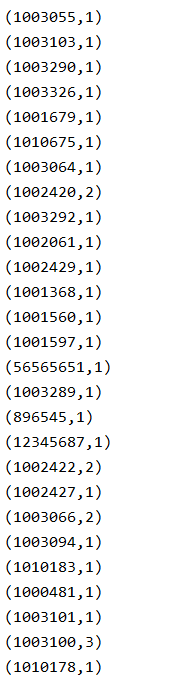
scala使用spark进行单词统计
1.功能简介:
对txt文件中的单词进行数量统计并将结果输出到控制台上
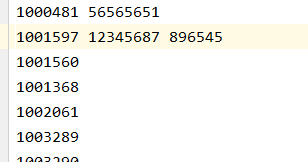
2.TXT文件内容样式
3.源代码
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object spark01_wordcount { def main(args: Array[String]): Unit = { //单词统计 val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparConf) val lines:RDD[String] = sc.textFile("filepath") //filepath为txt文件路径 val words:RDD[String]=lines.flatMap(_.split(" ")) //此处为通过空格将每行数据进行切分,也可改为其他分隔符如逗号 val wordGroup:RDD[(String,Iterable[String])] =words.groupBy(word=>word) val wordToCount =wordGroup.map { case (word,list) => { (word,list.size) } } val array:Array[(String,Int)] = wordToCount.collect() array.foreach(println) sc.stop() } }
4.结果截图