大数据基础
一. 大数据基础入门:Hadoop的背景起源之一
1.为什么要学习大数据
- 目的:会有很好的工作
- 对比:Java与大数据对比,大数据薪水比较高
2.什么是大数据
举例说明如下:
- 商品推荐 (用大数据统计购物网站商品的销量,可以清楚哪些商品卖的好,哪些商品卖的不好)。 大数据处理的问题:(1)大量订单如何存储? (2)大量订单如何计算?
- 天气预报 (可统计过去N年的数据) ,同上用大数据进行对天气数据的存储和计算。
- 根据以上两条案例可知大数据的本质:
- (1) 数据的存储:分布式文件系统(分布式存储) (2)数据的计算:分布式计算
3.Java和大数据是什么关系
- Hadoop:基于Java语言开发
- Spark:基于Scala语言,Scala基于Java语言
4.学习大数据需要的基础和路线
- 学习大数据需要的基础:
(1) Java基础(只需JavaSE知识,不需要学习JavaEE知识)--->类、继承、I/O、反射、泛型......
(2) Linux基础(Linux的操作)---->创建文件、目录、vi编辑器......
- 学习路线:
(1) Java基础和Linux基础
(2) Hadoop的学习:体系结构、原理、编程
a.第一阶段:HDFS(分布式文件系统)、MapReduce(是一个Java程序,用于大数据的计算)、HBase(NoSQL数据库),这三个是Hadoop中最核心的组件。
b.第二阶段:数据分析引擎:hive、pig 数据采集引擎:dqoop、flume
c.第三阶段: web管理工具:HUE Zookeeper:实现Hadoop的HA Oozie:数据流引擎
(3) Spark的学习
a.第一阶段:Scala编程语言
b.第二阶段:Spark Core---->基于内存、数据的计算
c.第三阶段:Spark SQL----->类似Oracle中的SQL语句
d.第四阶段:Spark Streaming------>进行实时计算(流式计算):例如:自来水厂
(4) Apache Storm的学习
Apache Storm类似Spark Streaming,进行实时计算的系统,实时计算的结果保存在Redis数据库中。所以还需要学习NoSQL数据库Redis(基于内存的数据库)
二. 大数据基础入门:Hadoop的背景起源之二
1. 什么是大数据、本质?
(1)数据的存储:分布式文件系统(分布式存储)------->HDFS: Hadoop Distributed File System 来源于 GFS: Google File System
(2)数据的计算:分布式计算
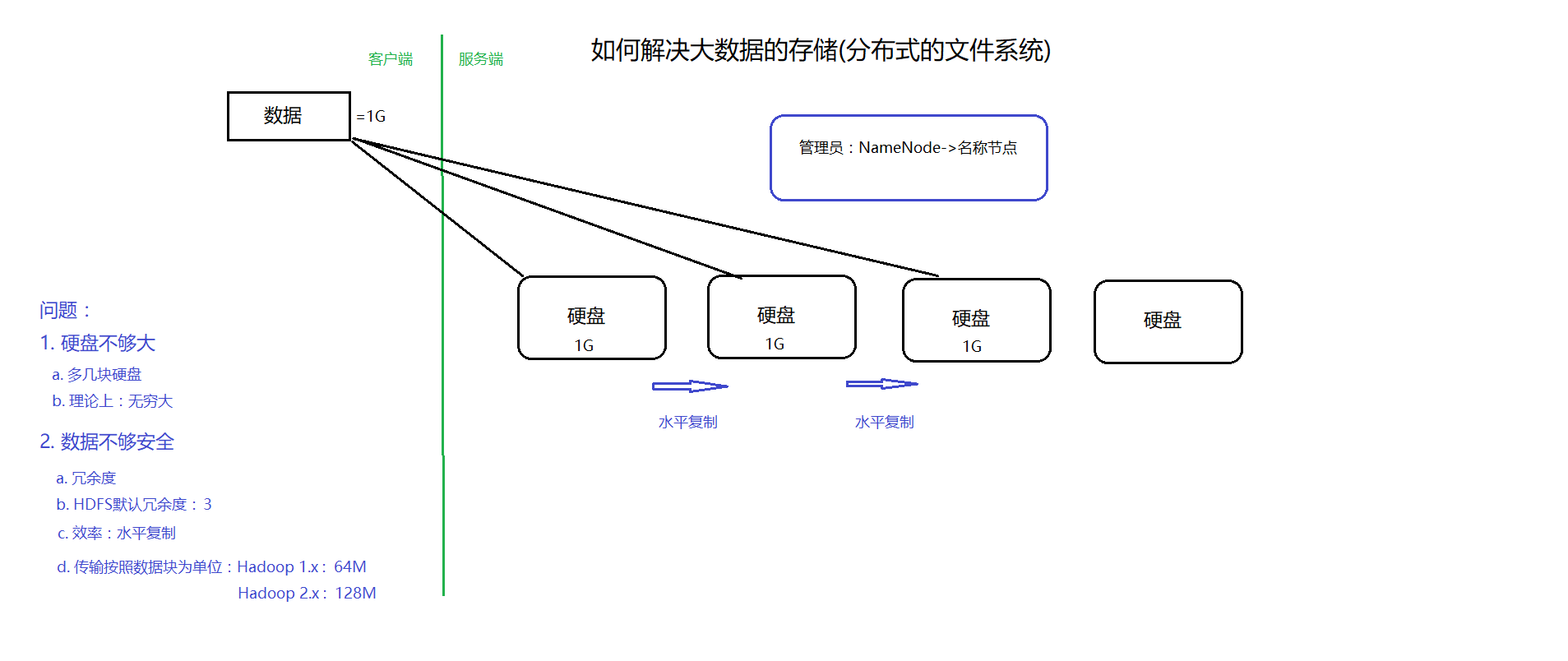
2. 如何解决大数据的存储?
(1)GFS:没有硬盘的,数据只能存在内存中
(2)Hadoop的安装模式:
a. 本地模式: 1台
b. 伪分布模式: 1台
c. 全分布模式: 3台