

正则表达式
1.正则表达式特点
是匹配字符串内容的一种规则。只和字符串相关了
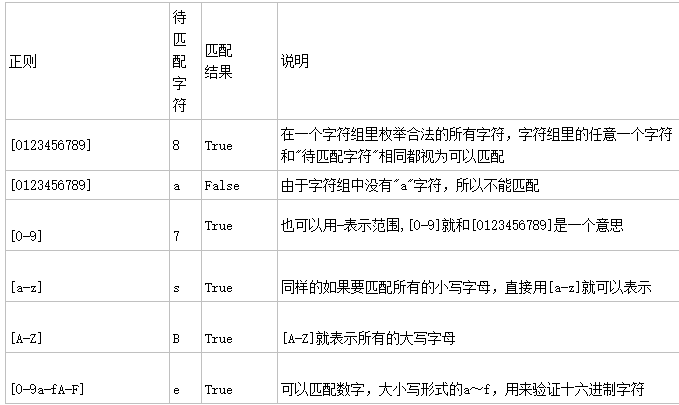
2.字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,一个[]表示一个字
规则[0123456789] 待匹配字符 8
可以用-表示范围,[0-9]就和[0123456789]是一个意思
[9-0]是错误的,数字只能从小到大,是根据ascii码的规则
[a-zA-Z]表示大小写均匹配 [A-Fa-f0-9]用来验证十六进制字符
3.元字符:
3.1 w,s,d
\w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字
\W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符
3.2 . n,t,b
\n 匹配一个换行符 \t 匹配一个制表符(tab键) \b 匹配一个单词的结尾 . 匹配除换行符以外的任意字符
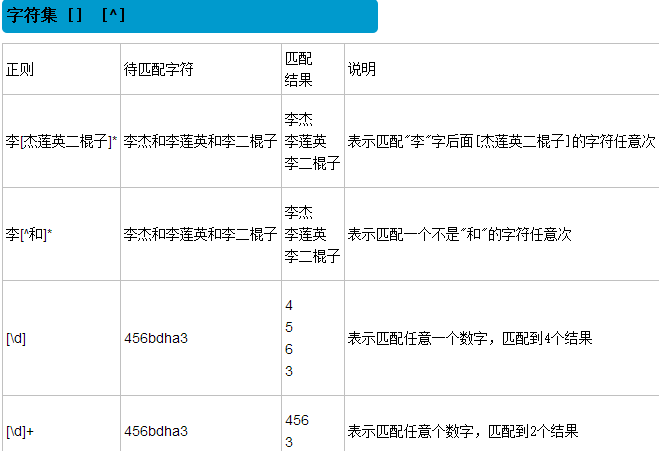
3.3 () [] [^]
()匹配括号内的表达式,也表示一个组 [...]匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符
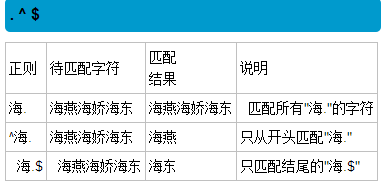
3.4 ^ $ |
1.^匹配字符串的开始 $匹配字符串的结尾 a|b 匹配字符a或字符b
2.^e只能放到最前面 ^la lala 匹配前两个la la$显示后两个la
3.^ey$ 确定一个字符串 ^e.*y$ 以e为开头以y为结尾
4.a|b 有重合的部分先匹配长的,再匹配短的
4.量词:
4.1{n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
4.2 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次
匹配小数: \d+\.\d+ 匹配数字: \d+\.?\d*


5.转义符 \ 将有意义元字符转成普通
\\d \d True 转义\之后变成\\,即可匹配
r'\\d' r'\d' True 在字符串之前加r,让整个字符串不转义
6.贪婪匹配和惰性匹配
*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
.*?的用法


. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 合在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
7.分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部🈶️数字组成,首位不能为0;
如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
1.^[1-9]\d{14}(\d{2}[0-9x])?$ 2.^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
