

Java IO3:字节流
一、流类
Java的流式的输入/输出是建立在四个抽象类的基础上的,InputStream、OutputStream、Reader、Writer,它们定义了流式子类的通用方法,用来创建具体的流式子类,程序通过这些具体的子类执行输入/输出操作。
InputStream和OutputStream为字节流设计,Reader和Writer为字符流设计,字节流和字符流形成分离的层次结构。一般来说,处理字符或字符串使用字符流类,处理字节或二进制对象使用字节流。
操作文件流时,不管是字符流还是字节流,都可以按照以下方式进行:
1、使用File类找到一个对象
2、通过File类的对象去实例化字节流或字符流的子类
3、进行字节(字符)的读、写操作
4、关闭文件流
二、OutputStream(字节输出流)
OutputStream是定义了Java流式字节输出模式的抽象类。该类的所有方法返回一个void值并且在出错的情况下引发一个IOException,OutputStream提供的抽象方法有:
| 方 法 | 作 用 |
| void close() | 关闭输出流,关闭后的写操作会引发IOException |
| flush() | 刷新此输出流并强制写出所有缓冲的输出字节 |
| write(byte[] b) | 向一个输出流写一个完整的字节数组 |
| write(byte[] b, int off, int len) | 以b[off]为起点,向文件写入字节数组b中len个字节 |
| write(int b) | 向输出流写入单个字节,注意参数是一个int型,它允许设计者不必把参数转换成字节型就可以调用write()方法 |
三、FileOutputStream(文件字节输出流)
FileOutpuStream应该是Java中最常见的字节输出流了,它创建一个可向文件写入字节的类OutputStream,它常用的构造方法如下:
1、FileOutputStream(String name)
2、FileOutputStream(File file)
3、FileOutputStream(File file, boolean append)
前两个构造方法类似,前者输入文件的绝对路径,后者输入File的实例对象,和RandomAccessFile一样,推荐后者。第三个构造方法有一点不同,append如果设置为true,文件则以搜索路径模式打开,写入的内容会添加到文件的末尾,而不会覆盖原文件。FileOutputStream的创建不依赖于文件是否存在,在创建对象时,FileOutputSStream会在打开输出文件之前就创建它。这种情况下如果试图打开一个只读文件,会引发IOException。FileOutputStream,写一个例子,现在我的D盘路径下并没有"stream.txt"这个文件:
public class Test { public static void main(String[] args) throws IOException { File file = new File("D:/stream.txt"); //创建文件字节输出流 OutputStream outputStream = new FileOutputStream(file,true); byte[] bytes = "hello world".getBytes(); //将字节数组写入文件 outputStream.write(bytes); //关闭字节输出流 outputStream.close(); } }
结果:打开stream.txt文件
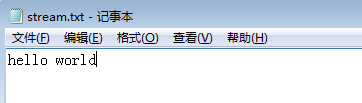
看到D盘下多了"stream.txt",且文件中的内容和我们写入的一致,同样这个例子也证明了FileOutputStream并不依赖指定路径下的文件是否存在。那如果指定路径下本来就有文件,那么写入操作将会覆盖该文件的内容而不是追加,很好证明:
public class Test { public static void main(String[] args) throws IOException { File file = new File("D:/stream.txt"); //创建文件字节输出流 OutputStream outputStream = new FileOutputStream(file); byte[] bytes = "hello world".getBytes(); //将字节数组写入文件 outputStream.write(bytes); //关闭字节输出流 outputStream.close(); } }
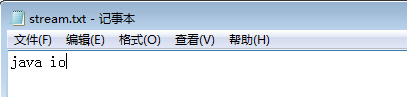
同样的操作,将写入的内容更换一下,还是写入到刚才的那个文件stream.txt
结果:打开该文件,发现文件内容已经由hello world 被覆盖为java io
补充说明:字节流与字符流的区别,先上结论:字符流使用了缓冲区,而字节流没有使用缓冲区。参考:java 字节流与字符流的区别
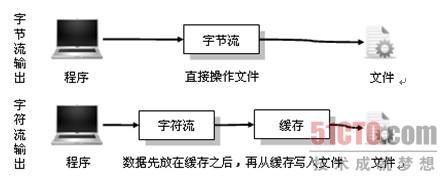
以及Java IO中缓冲区的作用,参考:javaIO缓冲区

四、InputStream(字节输入流)
InputStream是定义了Java流式字节输入模式的抽象类。该类所有方法在出错的时候都会引发一个IOException,InputStream提供的抽象方法有:
| 方 法 | 作 用 |
| int available() | 返回当前可读的字节数 |
| void close() | 关闭此输入流并释放与该流关联的所有系统资源,关闭之后再读取会产生IOException |
| int mark(int readlimit) | 在输入流中放置一个标记,该流在读取N个Bytes字节前都保持有效 |
| boolean markSupported() | 如果调用的流支持mark()/reset()就返回true |
| int read() | 如果下一个字节可读取则返回一个整形,遇到文件尾时返回-1 |
| int read(byte[] b) | 试图读取输入流中b.length个字节到b中,并返回实际成功读取的字节数,遇到文件尾则返回-1 |
| int read(byte[] b, int off, int len) | 将输入流中最多len个数组直接读入byte数组,off表示数组b中写入数据的初始偏移量。注意,三个read方法,在输入数据可用、检测到流末尾或者抛出异常前,此方法将一直阻塞 |
| void reset() | 重新设置输入指针到先前设置的标记处 |
| long skip(long n) | 跳过和丢弃此输入流中数据的n个字节 |
五、文件字节输入流
FileInputStream应该是Java中最常见的字节输入流了,它创建一个能从文件读取字节的InputStream类,它的两个常用构造方法如下:
1、FileInputStream(String name)
2、FileInputStream(File file)
和FileOutputStream差不多,推荐后者的用法。FileInputStream,同样写一个例子解释read(byte[])方法,操作的是上面D盘下生成的"stream.txt":
public class Test { public static void main(String[] args) throws IOException { File file = new File("D:/stream.txt"); //创建文件字节输入流 InputStream inputStream = new FileInputStream(file); //获取文件中的字节长度,构建字节数组 long length = file.length(); byte[] bytes = new byte[(int) length]; System.out.println("未将文件内容读取到byte数组中之前,byte数组中各字节的大小====="); for(byte aByte : bytes) { System.out.println(aByte); } System.out.println("将文件内容读取到byte数组中之后,byte数组中各字节的大小====="); int readByteNumber = inputStream.read(bytes); for(byte aByte : bytes) { System.out.println(aByte); } System.out.println("从文件中实际读取的字节数:" + readByteNumber); String readContent = new String(bytes,0,readByteNumber); System.out.println("从文件中读取到的内容是:" + readContent); inputStream.close(); } }
结果:
未将文件内容读取到byte数组中之前,byte数组中各字节的大小===== 0 0 0 0 0 0 0 0 0 0 0 0 0 0 将文件内容读取到byte数组中之后,byte数组中各字节的大小===== 104 101 108 108 111 32 119 111 114 108 100 33 33 33 从文件中实际读取的字节数:14 从文件中读取到的内容是:hello world!!!
说明:要区分清楚,OutputStream的作用是将内容由Java内存输出到文件中、InputStream是将内容由文件输入到Java内存中。read(byte[] b)方法之前讲明了,表示"试图读取b.length个字节到b中,并返回从文件中实际读取的字节数",返回的是实际字节的大小。不要误以为"Hello World!!!"是14个字符即28个字节,字节流底层是以byte为单位而不是以char为单位的,因此文件里面只有14个字节罢了。
置于read()方法返回的是下一个字节的大小,但read时是从文件头开始读的,所以返回的the next byte of data就是第一个字节的大小。
举例:read()方法获取文件中字节的大小:
public class Test { public static void main(String[] args) throws IOException { File file = new File("D:/stream.txt"); //创建文件字节输入流 InputStream inputStream = new FileInputStream(file); int read; do{ read = inputStream.read(); System.out.println(read); }while(read != -1); } }
结果:
104 101 108 108 111 32 119 111 114 108 100 33 33 33 -1
说明:-1表明已到文件的末尾。
六、BufferedInputStream和BuffereOutputStream
BufferedInputStream和BufferedOutputStream这两个类分别是FilterInputStream和FilterOutputStream的子类,作为装饰器子类,使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。
我们有必要知道不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
同时正因为它们实现了缓冲功能,所以要注意在使用BufferedOutputStream写完数据后,要调用flush()方法或close()方法,强行将缓冲区中的数据写出。否则可能无法写出数据。与之相似还BufferedReader和BufferedWriter两个类。
BufferedInputStream和BufferedOutputStream类就是实现了缓冲功能的输入流/输出流。使用带缓冲的输入输出流,效率更高,速度更快。
举例:
public class Test { public static void main(String[] args) throws IOException { File file = new File("D:" + File.separator + "buffered.txt"); OutputStream outputStream = new FileOutputStream(file); //构建字节缓冲输出流 BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(outputStream); byte[] bytes = "hello 中国 world 执行".getBytes(); //将字符串中的内容写入到文件中 bufferedOutputStream.write(bytes); //关闭输出流 bufferedOutputStream.close(); outputStream.close(); InputStream inputStream = new FileInputStream(file); //构建字节缓冲输入流 BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream); byte[] bytes1 = new byte[1024]; int lineContent = 0; //将文件内容读取到bytes中 while((lineContent = bufferedInputStream.read(bytes)) != -1){ System.out.println(new String(bytes) ); } //关闭输入流 bufferedInputStream.close(); inputStream.close(); } }
结果:
hello 中国 world 执行
参考资料:

