

集合之LinkedHashSet(含JDK1.8源码分析)
一、前言
上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的。
二、linkedHashSet的数据结构
因为linkedHashSet的底层是基于linkedHashMap实现的,所以linkedHashSet的数据结构就是linkedHashMap的数据结构,因为前面已经分析过了linkedHashMap的数据结构,这里不再赘述。集合之LinkedHashMap(含JDK1.8源码分析)。
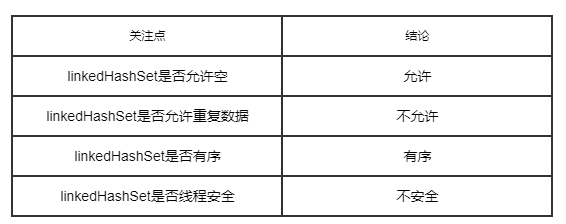
四个关注点在linkedHashSet上的答案
三、linkedHashSet源码分析-属性及构造函数
3.1 类的继承关系
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable
说明:继承HashSet,实现了Set接口,其内定义了一些共有的操作。
3.2 类的属性
由上图可知,除了本身的序列号,linkedHashSet并没有定义一些新的属性,其属性都是继承自hashSet。
3.3 类的构造函数
说明:如上图所示,linkedHashSet的四种构造函数都是基于linkedHashMap实现的,这里列出一种,其它几种也是一样。
/** * Constructs a new, empty linked hash set with the specified initial * capacity and load factor. * * @param initialCapacity the initial capacity of the linked hash set * @param loadFactor the load factor of the linked hash set * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ public LinkedHashSet(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor, true); }
通过super调用父类hashSet对应的构造函数,如下:
/** * Constructs a new, empty linked hash set. (This package private * constructor is only used by LinkedHashSet.) The backing * HashMap instance is a LinkedHashMap with the specified initial * capacity and the specified load factor. * * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @param dummy ignored (distinguishes this * constructor from other int, float constructor.) * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
四、linkedHashSet源码分析-核心函数
linkedHashSet的add方法,contains方法,remove方法等等都是继承自hashSet的,也是基于hashMap实现的,只是一些细节上还是基于linkedHashMap实现而已,前面已经分析过,这里不再赘述。
举例:
public class Test { public static void main(String[] args) { LinkedHashSet linkedHashSet = new LinkedHashSet<>(); linkedHashSet.add("zs"); linkedHashSet.add("ls"); linkedHashSet.add("ww"); linkedHashSet.add("zl"); linkedHashSet.add(null); linkedHashSet.add("zs"); System.out.println(linkedHashSet); boolean zs1 = linkedHashSet.remove("zs"); System.out.println("删除zs===" + zs1); System.out.println(linkedHashSet); boolean zs = linkedHashSet.contains("zs"); System.out.println("是否包含zs===" + zs); } }
结果:可见,linkedHashSet允许空值,不允许重复数据,元素按照插入顺序排列。
[zs, ls, ww, zl, null] 删除zs===true [ls, ww, zl, null] 是否包含zs===false
五、总结
可见,linkedHashSet是与linkedHashMap相对应的,分析完linkedHashMap再来看linkedHashSet就很简单了。

