OCR光学字符识别
流程:图像获取—图像预处理—图像分割—创建模型句柄—字符识别处理
案例一:使用halcon自带分类器识别

参考代码
* -- OCR 光学字符识别 *读取图片 read_image (Audi2, 'D:/hoclan/audi2.png') *1.定位 -->去掉干扰物 *获得窗口句柄 dev_get_window (WindowHandle) *设置显示边缘模式,方便查看选中内容 dev_set_draw ('margin') *绘制矩形1区域 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形1区域 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *把目标区域扣下来 reduce_domain (Audi2, Rectangle, ImageReduced) *2.提取车牌字符的区域 *(因为OCR 识别的是区域) *设置显示模式为填充模式,因为前面的边缘模式导致二值化区分不好看 dev_set_draw ('fill') *blob 三步骤:1.threshold 2.connection 3.select_shape *二值化 threshold (ImageReduced, Region, 30, 80) *连通分割 connection (Region, ConnectedRegions) *筛选 按区域和高度两个条件筛选 ['area','height'] * 800 <= area <= 1600 * 42 <= height <= 70 select_shape (ConnectedRegions, SelectedRegions, ['area','height'], 'and', [800,42], [1600,70]) *3.进行字符识别 *读取光学字符分类器 * Industrial_0-9A-Z_NoRej.omc 分类器路径 * OCRHandle 识别句柄 read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle) *开始分类 * SelectedRegions 输入 字体(笔记)区域 * ImageReduced 输入 区域所在的图像 * OCRHandle 输入 识别句柄 * Class 输出 识别返回结果 * Confidence 输出 置信度(得分)0.999不一定靠谱啊 do_ocr_multi_class_mlp (SelectedRegions, ImageReduced, OCRHandle, Class, Confidence) *求显示信息的坐标 area_center (SelectedRegions, Area, Row, Column) *显示信息 *disp_message (WindowHandle, Class, 'image', Row+40, Column, 'black', 'true') *窗口显示文本信息 * 输入 显示的信息 Class * 显示跟随的坐标系 'image' 'window' * 显示的坐标 Row, Column * 字体颜色 'black' * 参数键 ['box','box_color'] * 参数值 ['true','white'] dev_disp_text (Class, 'image', Row+50, Column, 'black', ['box','box_color'], ['true','white'])
注意事项
*注意事项: * 1.halcon 自带的分类器 识别过程字体角度不允许存在 太大的偏差 *旋转图像 * 10 指角度!!! *rotate_image (ImageReduced, ImageRotate, 10, 'constant') *2.仅允许在 白纸黑字 的状态下识别,需要使用invert_image 图像灰度值的反转(黑白互转) *invert_image (ImageRotate, ImageInvert)
案例二:ORC训练模式(识别麻将)
场景:halcon自带的分类器不能满足所有场景,因此需要自己训练模型。
参考代码
这个案例以识别麻将为场景
OCR 训练模式 *1.训练 *读取文件 read_image (Image, 'D:/hoclan/OCR/fb.bmp') **--手动修改参数区域 begin--** *要训练的文件类型 fileType := 'fb' *要训练的数量 numbers := 2 *车牌号码字符范围 * 笔记与对应的中文关联起来 text:=['北','發'] *预训练文件路径 ocrTrf:= 'D:/hoclan/001halcon/'+fileType+'_ocr' *保存训练文件地址 ocrOmc:= 'D:/hoclan/001halcon/'+fileType+'_ocr.omc' **--手动修改参数区域 end--** *彩色图转灰度图 rgb1_to_gray (Image, Image) *自己训练的文件 不需要指定白纸黑字 *非白纸黑字需要转 *图像灰度值反转 0>>255 1>>254 *invert_image (Image, Image) *显示边缘模式 dev_set_draw ('margin') *获得窗口句柄 dev_get_window (WindowHandle) *使用一个容器,装 笔记(区域) *创建空对象 gen_empty_obj (arrObj) for Index := 0 to (numbers-1) by 1 *显示图像类型变量 *作用:覆盖下面的文字显示 dev_display (Image) *设置光标位置 set_tposition (WindowHandle, 20, 400) *往窗口写入信息 write_string (WindowHandle, '绘制第'+(Index+1)+'个,左键按下绘制,右键结束') *绘制矩形1,得到坐标信息 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形区域1 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *图像剪切 reduce_domain (Image, Rectangle, ImageReduced) *二值化 --> 得到字体的笔记(区域) threshold (ImageReduced, Region, 30, 80) *对象拼接 arrObj + Region = arrObj concat_obj (arrObj, Region, arrObj) endfor *笔记与预训练文件关联起来 for Index1 := 1 to numbers by 1 *选择对象 从arrObj 里选择 *赋值给 ObjectSelected *索引 从1开始的,特殊!!! select_obj (arrObj, ObjectSelected, Index1) *追加训练模型到预训练文件 * 笔记区域 ObjectSelected * 区域所在图像 ImageReduced * 区域对应的字符 text[Index-1] * 预训练文件全路径 'train_ocr' append_ocr_trainf (ObjectSelected, Image, text[Index1-1], ocrTrf) *append 追加的模式,优点:可以无限添加 缺点:训练错误没有办法单独删除错误的那一个 *覆盖的形式写入 每次训练都是最新的文件 *write_ocr_trainf (ObjectSelected, Image, text[Index1-1], ocrTrf) endfor *读取训练文件 * CharacterNames 库存在的关联字符串 * CharacterCount 每个字符串关联过的次数(训练次数) read_ocr_trainf_names (ocrTrf, CharacterNames, CharacterCount) *创建训练句柄 * 8, 10 字符宽,高 * 字符参数 'constant', 'default', * CharacterNames 库存的关联字符 * 80 因此的神经元个数 * OCRHandle 输出 训练的句柄 create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, 80, 'none', 10, 42, OCRHandle) *开始训练 * 200 训练次数 0.01 每次叠加的值 trainf_ocr_class_mlp (OCRHandle, ocrTrf, 200, 1, 0.01, Error, ErrorLog) *保存训练文件 write_ocr_class_mlp (OCRHandle, ocrOmc) *2.验证 *清除 OCR 句柄 (方便验证,所以清除前面的) clear_ocr_class_mlp (OCRHandle) *从本地加载分离器 * ocrOmc 路径 read_ocr_class_mlp (ocrOmc, OCRHandle1) *试验 庭 是否能识别出来(最好用中间的测试) select_obj (arrObj, ObjectSelected1, 2) *ocr识别 do_ocr_multi_class_mlp (ObjectSelected1, Image, OCRHandle1, Class, Confidence)
注意事项
*注意:常见问题 *1.放一个没有训练过的笔记,识别不会报错(只会误判),往往会识别成最后一个训练的笔记 *因此需要 Class(结果) + Confidence(置信度),其中置信度>0.98 才算识别成功 *2.完善训练样本——生成大批量复杂样本 * 助手 》 OCR助手 》 文件 》 加载训练文件 * OCR 》 浏览训练文件 》 生成样本变形 》 保存训练文件
识别麻将
要点解析
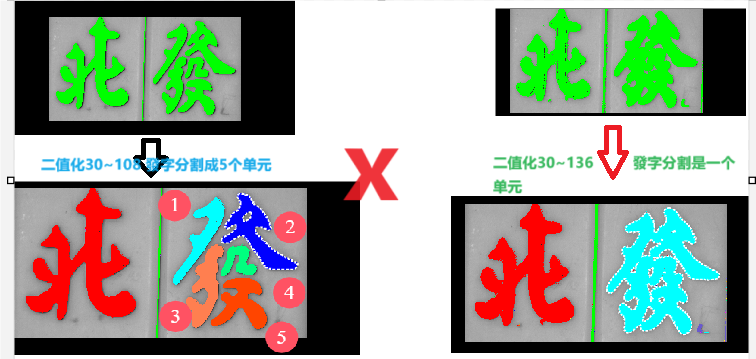
代码
*OCR 识别作业2 * 识别麻将 read_image (Image1, 'D:/hoclan/OCR/fb.bmp') *获得窗口句柄 dev_get_window (WindowHandle) *设置显示边缘模式,方便查看选中内容 dev_set_draw ('margin') rgb1_to_gray (Image1, Image1) *绘制矩形1区域 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形1区域 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *把目标区域扣下来 reduce_domain (Image1, Rectangle, ImageReduced) *图像反转 *invert_image (ImageReduced, ImageReduced) *设置显示模式为填充模式,因为前面的边缘模式导致二值化区分不好看 dev_set_draw ('fill') *blob 三步骤:1.threshold 2.connection 3.select_shape *二值化 136 threshold (ImageReduced, Region, 30, 136) *连通分割 connection (Region, ConnectedRegions) *筛选 按条件筛选 select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 38650.8, 65000) *3.进行字符识别 fbOcrOmc:= 'D:/hoclan/001halcon/fb_ocr.omc' *读取光学字符分类器 read_ocr_class_mlp (fbOcrOmc, OCRHandle) *开始分类 do_ocr_multi_class_mlp (SelectedRegions, ImageReduced, OCRHandle, Class, Confidence) *求显示信息的坐标 area_center (SelectedRegions, Area, Row, Column) dev_display (Image1) *窗口显示文本信息 dev_disp_text (Class+Confidence, 'image', Row+150, Column, 'black', ['box','box_color'], ['true','white'])

案例三:ORC识别车牌号码(训练模式)
参考代码
其中用到的训练模式需要自己参考上面案例二训练后使用
* OCR识别作业 * 1.识别李老师车牌号码 *读取图片 read_image (Car1, 'D:/hoclan/OCR/car1.jpg') *转灰度图 rgb1_to_gray (Car1, Car1) carOcrOmc:= 'D:/hoclan/001halcon/car_ocr.omc' *获得窗口句柄 dev_get_window (WindowHandle) *设置显示边缘模式,方便查看选中内容 dev_set_draw ('margin') *绘制矩形1区域 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形1区域 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *把目标区域扣下来 reduce_domain (Car1, Rectangle, ImageReduced) *转白纸黑字才能识别 invert_image (ImageReduced, ImageReduced) *2.提取车牌字符的区域 *(因为OCR 识别的是区域) *设置显示模式为填充模式,因为前面的边缘模式导致二值化区分不好看 dev_set_draw ('fill') *blob 三步骤:1.threshold 2.connection 3.select_shape *二值化 threshold (ImageReduced, Region, 0, 60) *连通分割 connection (Region, ConnectedRegions) *筛选 按区高度 select_shape (ConnectedRegions, SelectedRegions1, 'height', 'and', 100, 130) *3.进行字符识别 *读取光学字符分类器 * Industrial_0-9A-Z_NoRej.omc 分类器路径 * OCRHandle 识别句柄 *read_ocr_class_mlp (carOcrOmc, OCRHandle) read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle) *开始分类 * SelectedRegions 输入 字体(笔记)区域 * ImageReduced 输入 区域所在的图像 * OCRHandle 输入 识别句柄 * Class 输出 识别返回结果 * Confidence 输出 置信度(得分)0.999不一定靠谱啊 do_ocr_multi_class_mlp (SelectedRegions1, ImageReduced, OCRHandle, Class, Confidence) * 车牌特殊字O和I的处理 for Index := 0 to |Class|-1 by 1 if (Class[Index] == 'I') Class[Index] := '1' elseif (Class[Index] == 'O') Class[Index] := '0' endif endfor *求显示信息的坐标 area_center (SelectedRegions1, Area, Row, Column) *处理汉字 *如果可信度小于0.98,则是识别不达标,转汉字处理 *先找到汉字的区域 for Index1 := 0 to |Class|-1 by 1 if (Confidence[Index1] < 0.98) *绘制矩形1区域 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形1区域 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *把目标区域扣下来 reduce_domain (Car1, Rectangle, ImageReduced) *转白纸黑字才能识别 invert_image (ImageReduced, ImageReduced) *设置显示模式为填充模式,因为前面的边缘模式导致二值化区分不好看 dev_set_draw ('fill') *blob 三步骤:1.threshold 2.connection 3.select_shape *二值化 threshold (ImageReduced, Region, 0, 60) *连通分割 connection (Region, ConnectedRegions) *筛选 按区高度 select_shape (ConnectedRegions, SelectedRegions1, 'height', 'and', 100, 130) *读取光学字符分类器 read_ocr_class_mlp (carOcrOmc, OCRHandle) *开始分类 do_ocr_multi_class_mlp (SelectedRegions1, ImageReduced, OCRHandle, Class1, Confidence1) *赋值 Confidence[Index1] := Confidence1 Class[Index1] := Class1 break endif endfor *窗口显示文本信息 dev_disp_text (Class, 'image', Row+40, Column, 'black', ['box','box_color'], ['true','white'])
案例三:ORC识别+极坐标转换
参考代码
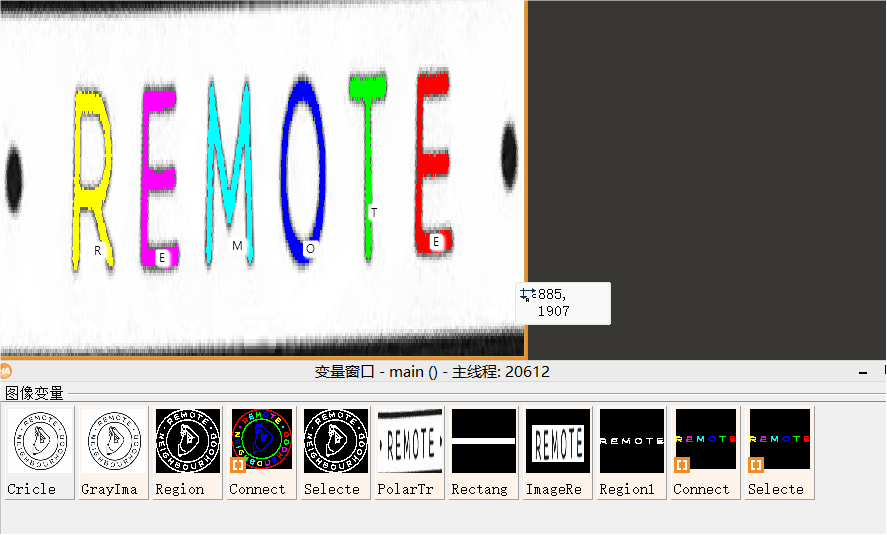
*3.扇形区域平铺 read_image (Cricle, 'D:/hoclan/OCR/cricle.png') rgb1_to_gray (Cricle, GrayImage) *得到圆心 threshold (Cricle, Region, 0, 50) connection (Region, ConnectedRegions) select_shape (Region, SelectedRegions, 'area', 'and', 50000, 53000) area_center (SelectedRegions, Area, Row, Column) * Row, Column 圆的中心点坐标 * 45, 135 起始、结束弧度 (注意这里位置反写) * 0, 100 极坐标的开始和结束极长(注意这里位置反写) * 512, 512 输出图片的宽高 polar_trans_image_ext (Cricle, PolarTransImage, \ Row, Column,\ rad(155), rad(25),\ Row-30,Row-150, \ 900, 120, 'nearest_neighbor') dev_get_window (WindowHandle) *绘制矩形1区域 draw_rectangle1 (WindowHandle, Row1, Column1, Row2, Column2) *创建矩形1区域 gen_rectangle1 (Rectangle, Row1, Column1, Row2, Column2) *把目标区域扣下来 reduce_domain (PolarTransImage, Rectangle, ImageReduced) rgb1_to_gray (ImageReduced, ImageReduced) *blob三步 threshold (ImageReduced, Region1, 0, 90) connection (Region1, ConnectedRegions1) select_shape (ConnectedRegions1, SelectedRegions2, 'area', 'and', 700, 1550) area_center (SelectedRegions2, Area1, Row3, Column3) *读取光学字符分类器 read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle) *开始分类 do_ocr_multi_class_mlp (SelectedRegions2, ImageReduced, OCRHandle, Class, Confidence) *窗口显示文本信息 dev_disp_text (Class, 'image', Row3+20, Column3, 'black', ['box','box_color'], ['true','white'])