Neo4j 图数据科学(Graph Data Science, GDS)基础:图算法
 速成,用着用着就都会了。
速成,用着用着就都会了。
译自官网课程: Neo4j Graph Data Science Fundamentals | Free Neo4j Courses from GraphAcademy
官网文档: Graph algorithms - Neo4j Graph Data Science
1 算法层和执行模式
这一节介绍不同的算法层级, 算法的不同执行模式, 以及如何估计在GDS中运行算法所需的内存.
学完这节你将会:
- 了解每个算法层级的意义
- 了解每种算法的执行模式的使用时机
- 知道如何估算在你的数据上运行GDS算法所需要的内存
1.1 层级
GDS算法被分为三个层级: alpha, beta和产品质量层.
- 产品质量: 表示该算法在稳定性和可扩展性方面已经过测试. 这个层级的算法以
gds.<algorithm>为前缀. - Beta: 表示该算法是产品质量层的候选算法. 这个级别的算法前缀为
gds.beta.<algorithm>. - Alpha: 表示该算法是实验性的, 可能随时被改变或删除. 本层的算法前缀为
gds.alpha.<algorithm>.
1.2 执行模式
GDS算法有4种执行模式, 决定了如何处理算法的结果.
stream: 将算法的结果作为一个记录流返回.stats: 返回一条总结性的统计记录, 但不向Neo4j数据库写入数据或修改任何数据.mutate: 将算法的结果写到内存中的图投影中, 并返回一条总结性的统计记录.write: 将算法的结果写回原Neo4j数据库, 并返回一条总结性的统计记录.
只有产品质量层的算法才能保证拥有所有执行模式.
更多细节以及练习参照: Running algorithms - Neo4j Graph Data Science.
1.3 内存估算
随着数据规模的增长, 数据科学工作者面临的一个普遍挑战是弄清楚需要多少内存来支持他们的分析和机器学习工作流程. 这往往需要大量的实验和试错. 为了规避这个问题, GDS提供了一个估计程序, 允许你在实际执行算法之前估计在数据上使用算法所需的内存. 对不同的算法和执行模式使用估计程序, 只需要简单地在命令后面加上.estimate.
只有产品质量层的算法才能保证拥有所有执行模式.
更多细节以及练习参照: Memory Estimation - Neo4j Graph Data Science.
1.4 一般性算法语法
综合上述内容, 所有GDS算法都遵循以下语法:
CALL gds[.<tier>].<algorithm>.<execution-mode>[.<estimate>](
graphName: STRING,
configuration: MAP
)
2 中心性与重要性
中心性算法被用来确定图中不同节点的重要性.
中心性的常见使用案例有:
- 推荐: 识别并推荐你提供的产品目录中最有影响力或最受欢迎的项目
- 供应链分析: 找到你的供应链中最关键的节点, 比如网络中的供应商, 制造成品的部分原材料, 或者是航线中的一个港口.
- 欺诈和异常检测 (anomaly detection) : 寻找有许多共同标识符的用户, 或在多个社区之间充当桥梁的用户.
2.2 度中心性 (degree centrality) 算法实例
度中心性 (degree centrality) 是最普遍和最简单的中心性算法之一. 它计算一个节点拥有的关系数量. 在GDS的应用中, 我们特别地计算了外度 (out-degree) 中心性, 即计算从一个节点发出的关系. 下面是一个使用度中心性来计算每个演员演过的电影数量的例子.
首先创建图投影.
CALL gds.graph.project('proj', ['Actor','Movie'], 'ACTED_IN');
然后用stream模式计算度中心性.
//get top 5 most prolific actors (those in the most movies)
//using degree centrality which counts number of `ACTED_IN` relationships
CALL gds.degree.stream('proj')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS actorName, score AS numberOfMoviesActedIn
ORDER BY numberOfMoviesActedIn DESCENDING, actorName LIMIT 5
| actorName | numberOfMoviesActedIn |
|---|---|
| Robert De Niro | 56.0 |
| Bruce Willis | 49.0 |
| Nicolas Cage | 45.0 |
| Samuel L. Jackson | 45.0 |
| Clint Eastwood | 40.0 |
前三名演员应该是: "Robert De Niro", "Bruce Willis", 和 "Nicolas Cage".
2.3 PageRank (网页排名) 算法实例
另一种常见的中心性算法是PageRank算法. PageRank算法适合于衡量有向图 (directed graph) 中节点影响力, 特别是在关系代表某种形式的流动的情况下, 如在支付网络, 供应链和物流, 通信, 路由以及网站和链接的图中.
PageRank算法最初是由谷歌联合创始人Larry Page和Sergey Brin于1996年在斯坦福大学开发的, 是关于一种新型搜索引擎的研究项目的一部分. 此后, 它一直被谷歌搜索公司用于在其搜索引擎结果中对网页进行排名.
总的来说, PageRank 算法通过计算来自相邻节点的传入关系的数量来估计节点的重要性, 关系按这些相邻节点的重要性和外度中心性进行加权. 基本假设是, 更重要的节点可能按比例地拥有来自其他导入节点的更多的传入关系. 如果有兴趣更深入地了解, PageRank - Neo4j Graph Data Science提供了PageRank的全面技术解释.
下例应用PageRank来寻找1990年及以后上映且收入至少为1000万美元电影的导演→演员网络中最有影响力的人.
首先, 创建图投影. 这种情况我们可以使用Cypher投影创建一个拥有(Person)-[:DIRECTED_ACTOR]->(Person)的图. 全面分析这张图可以来了解导演和演员之间的影响.
//drop last graph projection
CALL gds.graph.drop('proj', false);
//create Cypher projection for network of people directing actors
//filter to recent high grossing movies
CALL gds.graph.project.cypher(
'proj',
'MATCH (a:Person) RETURN id(a) AS id, labels(a) AS labels',
'MATCH (a1:Person)-[:DIRECTED]->(m:Movie)<-[:ACTED_IN]-(a2)
WHERE m.year >= 1990 AND m.revenue >= 10000000
RETURN id(a1) AS source , id(a2) AS target, count(*) AS actedWithCount,
"DIRECTED_ACTOR" AS type'
);
接下来用PageRank来找到导演-演员网络中最有影响力的前5位人物.
CALL gds.pageRank.stream('proj')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS personName, score AS influence
ORDER BY influence DESCENDING, personName LIMIT 5
| personName | influence |
|---|---|
| Robert De Niro | 0.6358739386030579 |
| Greg Kinnear | 0.6100648813587659 |
| Sandra Bullock | 0.6091624705383082 |
| Alec Baldwin | 0.5716254867353054 |
| Bruce Willis | 0.5366320764428817 |
前三名演员应该是: "Robert De Niro", "Greg Kinnear", 和 "Sandra Bullock".
2.4 其他中心性算法
其他GDS产品质量层级的中心化算法包括:
- 间隙中心性 (Betweenness Centrality) 算法: 衡量一个节点在图中其他节点之间的程度. 它经常被用来寻找图的一部分到另一部分的桥梁节点.
- 特征向量中心性 (Eigenvector Centrality) 算法: 衡量节点的横向影响力. 与PageRank类似, 但只对邻接矩阵 (adjacency matrix) 的最大特征向量起作用, 因此不会以同样的方式收敛, 并且更强烈地倾向于度数高的节点. 它在某些特定用例中可能更合适, 特别是不定向关系中.
- 文章排名 (Article Rank) 算法: PageRank算法的变体, 它假定源自低度节点的关系比来自高度节点的关系具有更高的影响力.
完整的产品质量层级的中心性算法列表可以在Centrality - Neo4j Graph Data Science找到.
3 路径搜索 (Path Finding) 算法
路径搜索算法在两个或多个节点之间寻找最短路径, 或评估路径的可用性和质量.
路径搜索的常见用例是:
- 供应链分析: 识别原产地和目的地之间或原材料和成品之间的最快路径
- 客户经历: 分析构成客户体验的事件. 例如, 在医疗保健领域一个住院病人从入院到出院的经历.
3.1 Dijkstra源-目标最短路径 (Dijkstra Source-Target Shortest Path) 算法
一个常见的, 行业标准的类似性算法是Dijkstra算法. 它计算一个源节点和一个目标节点之间的最短路径. 像GDS中的许多其他路径搜索算法一样, Dijkstra算法支持加权关系, 以便在比较路径时考虑距离或其他成本属性.
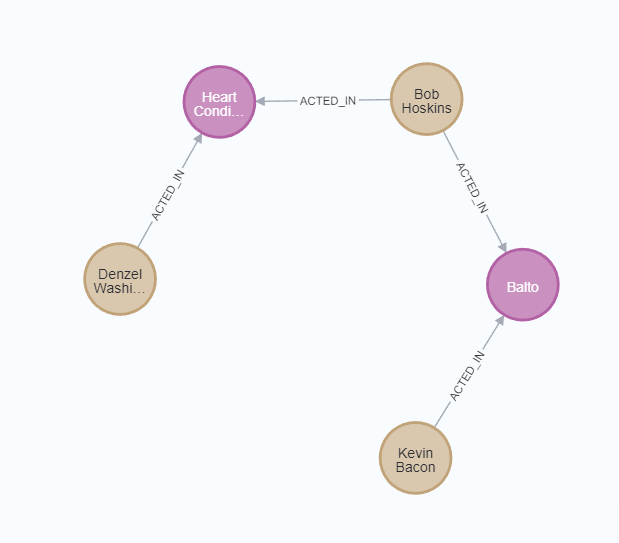
下例使用Dijkstra源-目标最短路径算法来寻找演员 "Kevin Bacon" 和 "Denzel Washington" 之间最短路径.
首先, 创建图投影.
CALL gds.graph.project('proj',
['Person','Movie'],
{
ACTED_IN:{orientation:'UNDIRECTED'},
DIRECTED:{orientation:'UNDIRECTED'}
}
);
然后运行Dijkstra最短路径算法.
MATCH (a:Actor)
WHERE a.name IN ['Kevin Bacon', 'Denzel Washington']
WITH collect(id(a)) AS nodeIds
CALL gds.shortestPath.dijkstra.stream('proj', {sourceNode:nodeIds[0], TargetNode:nodeIds[1]})
YIELD sourceNode, targetNode, path
RETURN gds.util.asNode(sourceNode).name AS sourceNodeName,
gds.util.asNode(targetNode).name AS targetNodeName,
nodes(path) as path;
这应该会返回一个Kevin Bacon与Denzel Washington之间的四跳路经.
3.2 其他路径搜索算法
其他GDS产品层的路径搜索算法可以分成几个不同的子类别:
两个节点之间的最短路径:
- A*算法最短路径 (A* Shortest Path) : Dijkstra算法的一个扩展, 使用启发式函数来加快计算速度.
- 颜氏算法最短路径 (Yen's Algorithm Shortest Path) : Dijkstra的一个扩展, 允许找到多条最短路径, 即前\(k\)条最短路径.
一个源节点与多个其他目标节点之间的最短路径:
- Dijkstra单源最短路径 (Dijkstra Single-Source Shortest Path) : Dijkstra算法在一个源和多个目标之间最短路径的实现.
- Delta-Stepping单源最短路径 (Delta-Stepping Single-Source Shortest Path) : 平行的最短路径计算. 计算速度比Dijkstra单源最短路径快, 但使用更多内存.
一个源节点与多个其他目标节点之间的一般路径搜索:
- 广度优先搜索 (Breadth-First Search, BFS) : 在每次迭代中, 按照与源节点距离增加的顺序搜索路径.
- 深度优先搜索 (Depth First Search, DFS) : 在每次迭代中沿单一多跳路径尽可能地搜索.
产品层级的中心性算法的完整列表可以在Path finding - Neo4j Graph Data Science中找到.
4 社区检测 (Community Detection) 算法
社区检测算法被用来评估节点组在图中的聚类或分区情况. GDS的大部分社区检测功能集中在区分和分配这些节点组的ID, 以便进行下游分析, 可视化或其他处理.
社区检测的常见用例包括:
- 欺诈检测: 通过识别经常发生可疑交易的账户及相互之间共享标识符, 找到欺诈团伙.
- 客户360: 将多个记录和互动区分为一个单一的客户档案, 这样一个组织就有了一个关于每个客户信息来源的汇总.
- 市场细分: 根据优先级, 行为, 兴趣和其他标准, 将目标市场划分为好接触的子群体.
4.1 Louvain社区检测
一个常见的社区检测算法是Louvain算法. Louvain算法对每个社区的模块化程度进行了最大化. 模块化度量了将节点分配给社区的质量. 就是度量一个节点在社区中联系的紧密程度比在随机网络中的联系紧密多少.
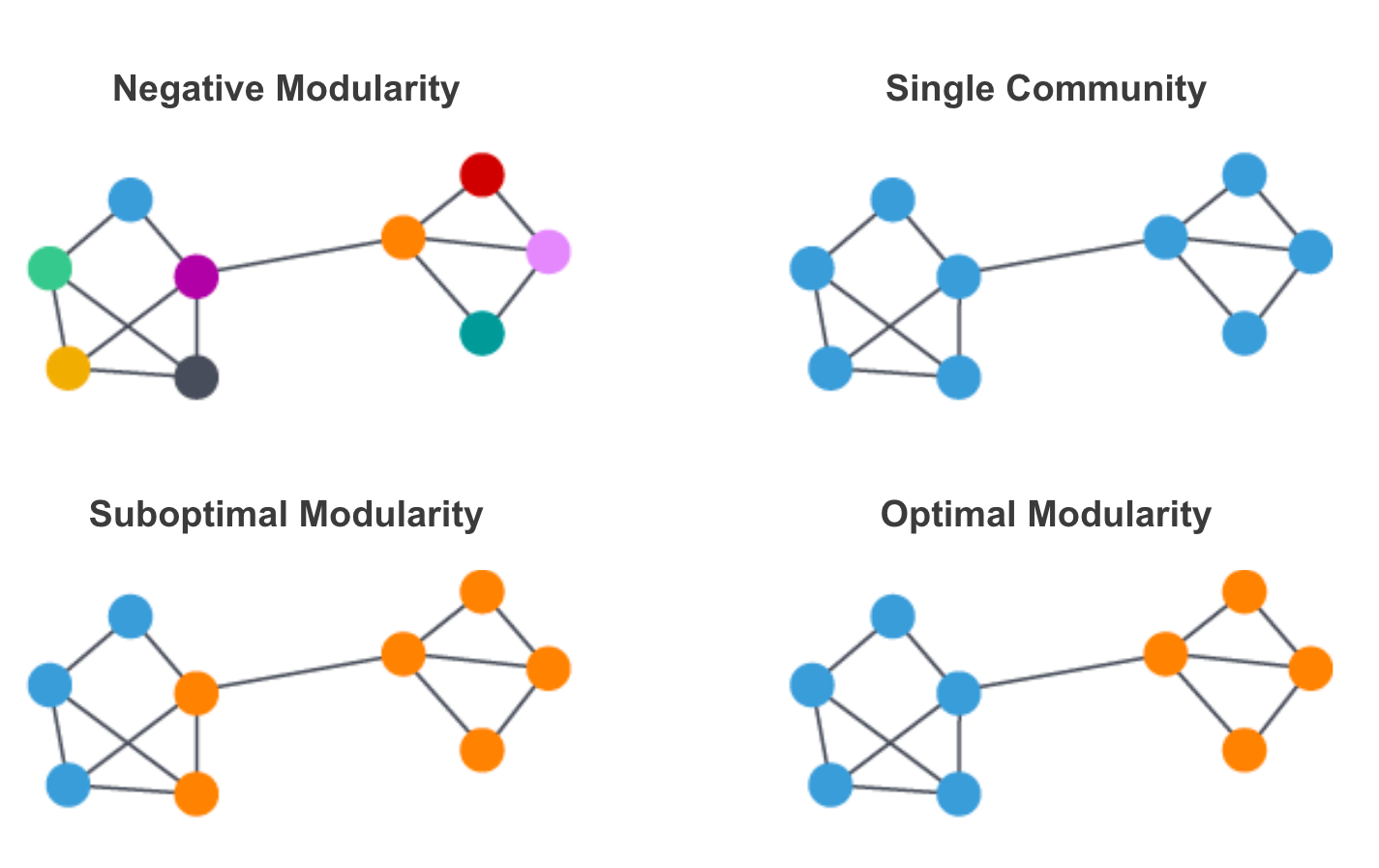
Louvain算法通过层次聚类递归地将社区合并在一起来实现模块优化. 有多个参数可用于控制Louvain算法的性能和产生的社区数量和规模. 包括最大的迭代次数和使用的层级, 以及评估收敛/停止条件的容忍度参数. Louvain - Neo4j Graph Data Science涵盖了这些参数和调整的更多细节.
需要注意的是Louvain是一个随机的算法. 因此, 社区分配在重新运行时可能会有一些变化. 当图没有一个自然的, 区分得较好的群落结构时, 运行之间的变化会变得更加显著. Louvain包括一个seedProperty参数, 可以用来分配初始的群落ID, 实现多次运行的一致. 另外, 如果一致性对你的使用情况很重要, 可以考虑其他的社群检测算法, 如弱连接成分 (WWC) , 采取更确定的分区方法来分配社群, 多次运行结果不会改变.
下例运行Louvain算法来了解我们的电影推荐的图中演员和导演的社区.
首先创建一个带有电影, 演员和导演的图投影. 投影的关系是UNDIRECTED, 这样Louvain算法效果最好.
CALL gds.graph.project('proj', ['Movie', 'Person'], {
ACTED_IN:{orientation:'UNDIRECTED'},
DIRECTED:{orientation:'UNDIRECTED'}
});
然后我们可以运行Louvain算法. 这里, 我们将在mutate模式下运行Louvain算法, 以保存社区ID, 并返回社区数量, 分布, 模块化程度的统计数据, 以及Louvain算法如何处理图形的信息.
CALL gds.louvain.mutate('proj', {mutateProperty:'communityId'})
我们可以用一个stream操作来验证投影中的communityId节点属性。
CALL gds.graph.streamNodeProperty('proj','communityId', ['Person'])
YIELD nodeId, propertyValue
WITH gds.util.asNode(nodeId) AS n, propertyValue AS communityId
WHERE n:Person
RETURN n.name, communityId LIMIT 5
| n.name | communityId |
|---|---|
| François Lallement | 24047 |
| Jules-Eugène Legris | 24047 |
| Lillian Gish | 16346 |
| Mae Marsh | 16346 |
| Henry B. Walthall | 16346 |
4.2 其他社区检测算法
下面是其他一些产品质量层的社区检测算法. 社区检测算法的完整列表可以在Community detection - Neo4j Graph Data Science中找到.
-
标签传播 (Label Propagation) : 与Louvain算法相似. 是可以很好地并行的快速算法. 对于大型图非常合适.
-
弱连接成分 (Weakly Connected Components, WCC) : 将图划分为连接节点的集合, 以使得
-
在同一集合中,任何节点能到达任意其他节点
-
不同集合的节点之间不存在路径
-
-
三角形计数 (Triangle Count) : 计算每个节点的三角形的数量. 可用于检测社区的凝聚力和图的稳定性.
-
局部聚类系数 (Local Clustering Coefficient) : 计算图中每个节点的本地聚类系数, 这是一个描述该节点与其相邻节点聚集程度的指标.
5 节点嵌入 (Node Embedding) 算法
节点嵌入的目标是计算节点的低维向量表示, 使向量之间的相似性 (eg. 点积) 接近于原图中节点之间的相似性. 这些向量也被称为嵌入, 对探索性数据分析, 相似性测量和机器学习非常有用.
5.1 直观理解
图3展示了 节点嵌入的原理, 即在图中靠近的节点最终在二维嵌入空间中也会靠近. 因此, 嵌入从图中获取结构, 即n维邻接矩阵, 并将其近似为每个节点的2维向量. 由于维度大大降低, 嵌入向量在下游过程中的使用效率更高. 例如, 它们可以被用于聚类分析, 或者作为训练节点分类或链接预测模型的特征.
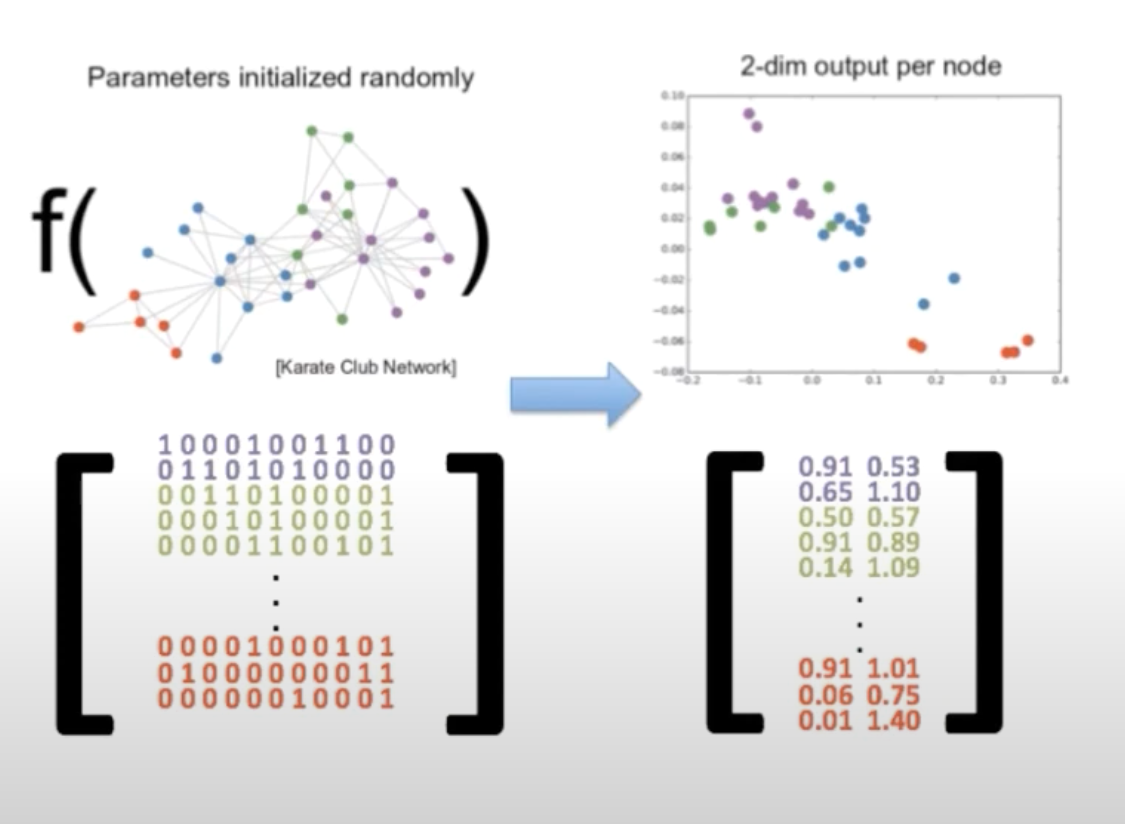
当然, 在现实问题中, 节点嵌入通常会大于2个维度, 通常最终会达到数百或更大, 尤其是当应用于具有数百万或数十亿节点的大型图时. 节点嵌入也不必严格基于图中节点的接近程度来确定相似性. 节点嵌入最常用于基于关系跳数和共同相邻节点的距离的相似性, 也可以在计算嵌入向量时考虑节点属性和其他 "全局视图" 节点属性.
5.2 用例
节点嵌入在多种情况下都有应用, 比如推荐, 异常和欺诈检测, 实体解析和其他形式的知识图谱的完成等.
节点嵌入向量本身并不提供见解, 它们的创建是为了启用或扩展其他分析方法. 常见的工作流程包括:
- 探索性数据分析 (Exploratory Data Analysis, EDA) 如在TSNE图中可视化嵌入,以更好地理解图形结构和潜在的节点集群
- 相似性测量 (Similarity Measurements) : 节点嵌入将使你可以使用K近邻算法 (KNN) 或其他技术来扩展大型图中的相似性推断. 这对于扩展基于记忆的推荐系统非常有用, 例如协同过滤 (collaborative filtering) 的变体. 它还可以用于欺诈检测等领域的半监督技术, 例如, 我们可能想生成与一组已知欺诈实体相似的线索.
- 用于机器学习的特征: 节点嵌入向量可以作为各种机器学习问题的特征. 例如, 在一个在线零售商的用户购买的关系图中, 我们可以使用嵌入来训练一个机器学习模型, 以预测用户接下来可能有兴趣购买的产品.
5.3 快速随机投影算法 (Fast Random Projection, FastRP)
GDS提供了一种叫做快速随机投影的节点嵌入技术的个性化实现, 简称FastRP.
FastRP利用概率抽样技术生成图的稀疏表示, 允许极快地计算嵌入向量, 其质量与传统的随机游走 (random walk) 和神经网络技术 (如Node2vec和GraphSage) 产生的向量相当. 刚开始在GDS中探索图的嵌入时, FastRP将是很好的选择.
FastRP有多个调整参数, 在现实应用中, 这些参数可能是需要考虑的重要因素. 以下是几个重要的注意事项:
embeddingDimension: 适用于GDS中的所有节点嵌入算法. 控制嵌入向量的长度. 设置这个参数是对维数和准确性的权衡. 更大的嵌入维度将更准确地捕捉图的结构, 但也需要更长的时间来生成和产生嵌入向量, 需要更多的内存和计算来处理下游. 嵌入维度的选择在很大程度上取决于图中节点的数量. 由于嵌入所能编码的信息量受到其维度的限制, 更大的图将倾向于需要更大的嵌入维度. 典型的取值是128-1024范围内的2的次数. 在拥有100K节点的图形上, 不小于256的维度能有好的结果.IterationWeights: 控制两个方面: 中间嵌入的迭代次数, 及其对最终节点嵌入的相对影响. 该参数是一个数值列表, 每一个数字表示一次迭代, 数值大小是应用于该迭代的权重. 默认是[0.0, 1.0, 1.0]. 一般而言, 第i次迭代的中间嵌入包含的特征取决于可通过长度为i的路径到达的节点.
还有其他参数可以控制规范化的强度和节点的影响, 详参Fast Random Projection - Neo4j Graph Data Science.
5.4 FastRP实例
下例在电影图中的人物节点生成FastRP嵌入, 基于他们所演和/或导演的电影组成的.
同样, 从图投影开始.
CALL gds.graph.project('proj', ['Movie', 'Person'], {
ACTED_IN:{orientation:'UNDIRECTED'},
DIRECTED:{orientation:'UNDIRECTED'}
});
然后运行FastRP. 出于演示的目的, 我们将只使用64维的嵌入. 我们也能在这里设置randomSeed来控制多次运行之间的一致性.
CALL gds.fastRP.stream('proj', {embeddingDimension:64, randomSeed:7474})
YIELD nodeId, embedding
WITH gds.util.asNode(nodeId) AS n, embedding
WHERE n:Person
RETURN id(n), n.name, embedding LIMIT 5
| id(n) | n.name | embedding |
|---|---|---|
| 9816 | François Lallement | A list of 64 values. Same below. 长度为64的列表, 下同. |
| 9817 | Jules-Eugène Legris | |
| 9818 | Lillian Gish | |
| 9819 | Mae Marsh | |
| 9820 | Henry B. Walthall |
理论上, 这些嵌入可用于相似性测量, 以了解哪些演员最相似, 并可用于内容推荐系统, 根据用户最近观看的电影的演员和/或导演, 向他们推荐电影.
5.5 其他节点嵌入算法
GDS还实现了Node2Vec, 该算法基于图中的随机游走计算节点的矢量表示. 以及GraphSage, 一种归纳建模方法, 利用节点属性和图结构计算节点嵌入.
6 相似性算法
相似性算法, 顾名思义, 是用来推断节点对之间的相似性. 在GDS中, 这些算法在图投影上成批地运行. 当根据用户指定的指标和阈值识别出类似的节点对时, 就会在这对节点之间画出一个具有相似性程度属性的关系. 根据运行算法时使用的执行模式, 这些相似性关系可以被作为记录流返回, 写到内存图中, 或写回数据库中.
类似性算法的常见用例包括:
- 欺诈检测: 通过分析一组新的用户账户与标记账户的相似程度, 发现潜在的欺诈用户账户
- 推荐系统: 在网上零售店中, 识别与用户正在浏览的商品相匹配的商品, 以获得用户印象并提高购买率
- 实体解析: 根据图中的活动或识别信息,识别出彼此相似的节点
6.1 GDS中的相似性算法
GDS有两种主要的相似性算法:
- 节点相似性: 根据图中共享的相邻节点的相对比例来确定节点之间的相似性. 当可解释性很重要时, 节点相似性是一个很好的选择. 你还能把比较范围缩小到数据的一个子集. 缩小范围的例子包括只关注单一社区, 新增加的节点, 或与感兴趣的子图特定距离内的节点.
- K近邻算法 (KNN) : 基于节点属性来确定相似性. 如果调整得当, GDS的KNN实现可以很好地用于大型图的全局推断. 它可以与嵌入和其他图算法一起使用, 根据图中的接近程度, 节点属性, 社区结构, 重要性/中心性等来确定节点之间的相似性.
6.2 度量相似性的选择
节点相似性算法和KNN都提供了不同的度量相似性的选择. 节点相似性算法可以选择jaccard相似度和重叠相似度. KNN的度量选择由节点属性类型驱动. 整数列表可选jaccard相似度和重叠相似度, 浮点列表可选余弦相似度, 皮尔逊相关度和欧几里得距离. 使用不同的度量当然会改变相似度值, 也会稍微改变解释. 更多关于节点相似性的不同度量: Node Similarity - Neo4j Graph Data Science, 关于KNN的不同度量: K-Nearest Neighbors - Neo4j Graph Data Science.
6.3 控制比较的范围
将每个节点与图中的其他节点进行比较是一项计算成本很高的工作,其复杂度大约为\(O(n^2)\). GDS对节点相似性算法和KNN算法的实现都有内部机制来智能地选择节点对进行比较, 使运行更快, 规模更大. 用户也能通过调整参数来调整节点对的采样, 选择比较的方式.
节点相似性算法有一个关于节点的degreeCutOff参数, 允许对要选择的节点的度中心性设置一个下限.
KNN算法有各种参数可以调整, 来权衡节点比较的速度与完整性, 包括采样率, 初始采样器方法, 迭代间的随机连接数, 以及其他一些参数. 在K-Nearest Neighbors - Neo4j Graph Data Science中可以阅读更多相关信息.
6.4 控制结果的范围
对于相似性比较, 我们可能还想控制返回的结果数量, 只考虑最相关的节点对. 节点相似性算法和KNN算法都有一个topK参数来限制每个节点返回的相似性比较的数量. 节点相似性算法更有能力在不仅仅每个节点的基础上, 而是在全局范围里限制结果.
6.5 KNN算法的应用实例
用之前从节点嵌入中计算出来的嵌入来推断演员和导演之间基于参与过的电影的相似性. 用以下代码重新生成投影:
CALL gds.graph.project('proj', ['Movie', 'Person'], {
ACTED_IN:{orientation:'UNDIRECTED'},
DIRECTED:{orientation:'UNDIRECTED'}
});
然后, 我们将像之前一样运行FastRP算法, 但在mutate模式下, 这样嵌入将被保存在投影中.
CALL gds.fastRP.mutate('proj', {
embeddingDimension:64,
randomSeed:7474,
mutateProperty:'embedding'
})
然后我们可以运行相似性算法. 我们将使用默认的余弦度量. 为了便于演示, topK将会限制为1, 这样我们就可以看到每个节点的最相似的配对.
CALL gds.knn.stream('proj', {nodeLabels:['Person'], nodeProperties:['embedding'], topK:1})
YIELD node1, node2, similarity
RETURN gds.util.asNode(node1).name AS actorName1,
gds.util.asNode(node2).name AS actorName2,
similarity
LIMIT 5
| actorName1 | actorName2 | similarity |
|---|---|---|
| François Lallement | Giacomo Baessato | 0.7103928923606873 |
| Jules-Eugène Legris | Patrick O'Connell | 0.6735765337944031 |
| Lillian Gish | Mae Marsh | 0.8979091048240662 |
| Mae Marsh | Lillian Gish | 0.8979091048240662 |
| Henry B. Walthall | Mary Alden | 0.6870026588439941 |
6.6 相似性函数
除了节点相似性算法和KNN算法, GDS还提供了一组函数, 可以用来计算两个数组之间的相似性, 使用的相似性指标包括jaccard相似度, 重叠相似度, 皮尔逊相关度, 余弦相似度和一些其他的度量. 完整的文档见Similarity functions - Neo4j Graph Data Science. 当你想测量单个节点对之间的相似性而不是整个图的相似性时, 这些函数很有用.
本文作者:ZZN而已
本文链接:https://www.cnblogs.com/zerozhao/p/neo4j-graph-algorithms.html
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号