Neo4j 图数据科学(Graph Data Science, GDS)介绍
译自官网课程: Introduction to Neo4j Graph Data Science | Free Neo4j Courses from GraphAcademy
官网文档: The Neo4j Graph Data Science Library Manual v2.1 - Neo4j Graph Data Science
1 Neo4j GDS概述
1.1 GDS插件和兼容性
GDS是作为Neo4j图形数据库的库和插件提供的, 需要作为扩展与配置更新一起安装. 按照性能不同有免费版本和付费的企业版, 但包括图算法和机器学习方法在内的分析方法都是一样的.
GDS库与Neo4j的版本兼容性可以在这里找到. 通常情况下, 两者的最新版是兼用的, 所以推荐总是升级到最新的版本.
1.2 安装
Neo4j Desktop的GDS安装过程最简单. 安装并打开Neo4j Desktop可以直接在数据库的Plugins标签中找到GDS:
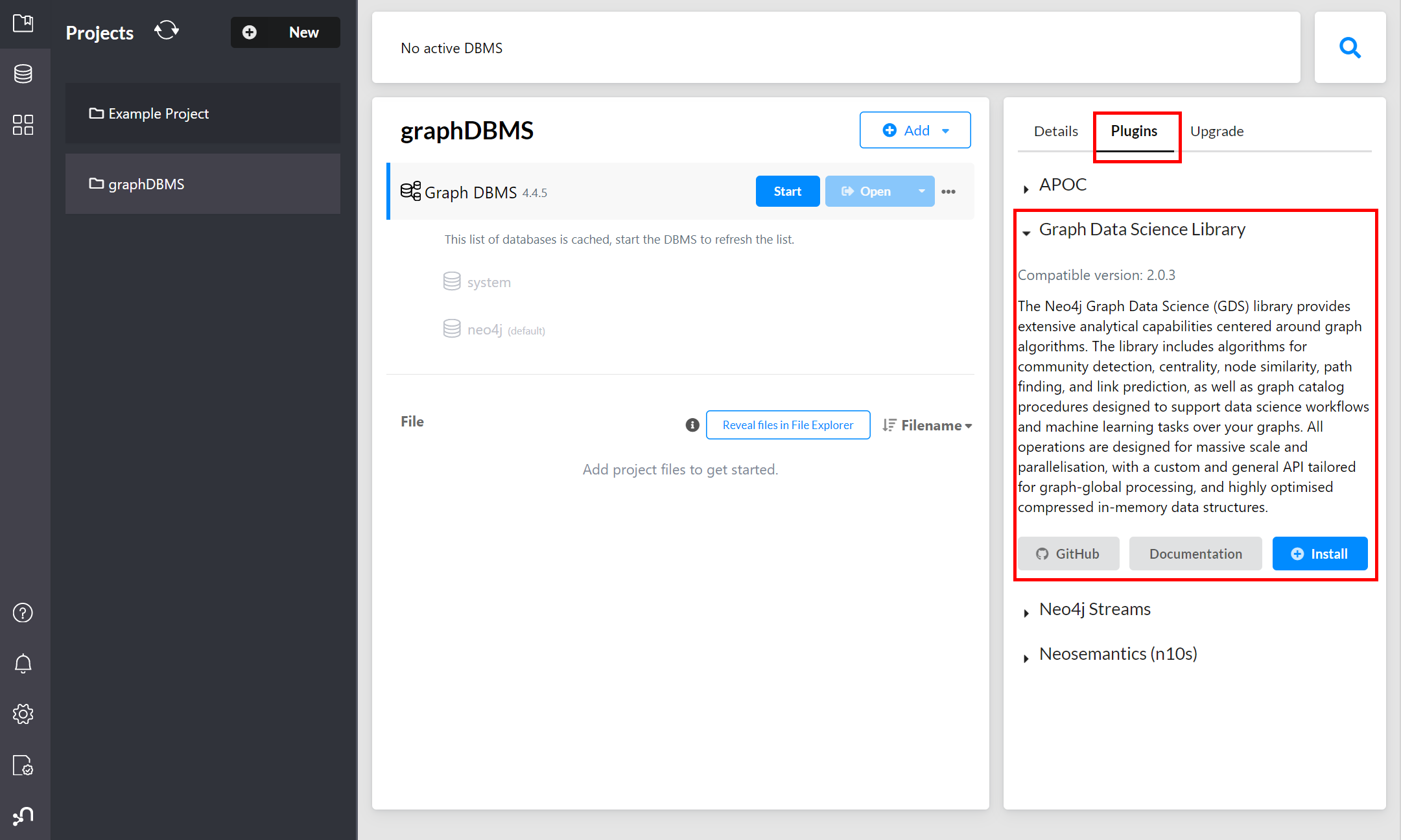
点击Install将下载GDS库并将其安装在数据库的plugins/目录下. 同时设置文件中将会添加以下条目:
dbms.security.procedures.unrestricted=gds.*
这个配置项是必要的, 因为GDS库访问Neo4j的低级组件, 以使性能最大化.
如果配置了程序允许列表, 请确保也包括GDS库的程序:
dbms.security.procedures.allowlist=gds.*
在Neo4j Desktop, 至少在最近的版本中, 该配置应该被禁用或默认包含 (这几句我看不懂, 专业不对口没两天我逐渐明白了一切) .
关于GDS在其他Neo4j部署类型上的安装, 包括独立服务器, docker和causal集群, 请参见安装文档. 企业版配置文档中可以找到付费企业许可证相关信息.
1.3 GDS的工作方式
在高层次上, GDS的工作方式是将数据转化并加载到一个为高性能图分析而优化的内存格式中. GDS在这种内存图格式上执行图算法, 特征工程和机器学习方法. 使得数据科学能够高效和可扩展地应用于展示整个或大部分图数据库的大型图 .
1.3.1 基本工作流程
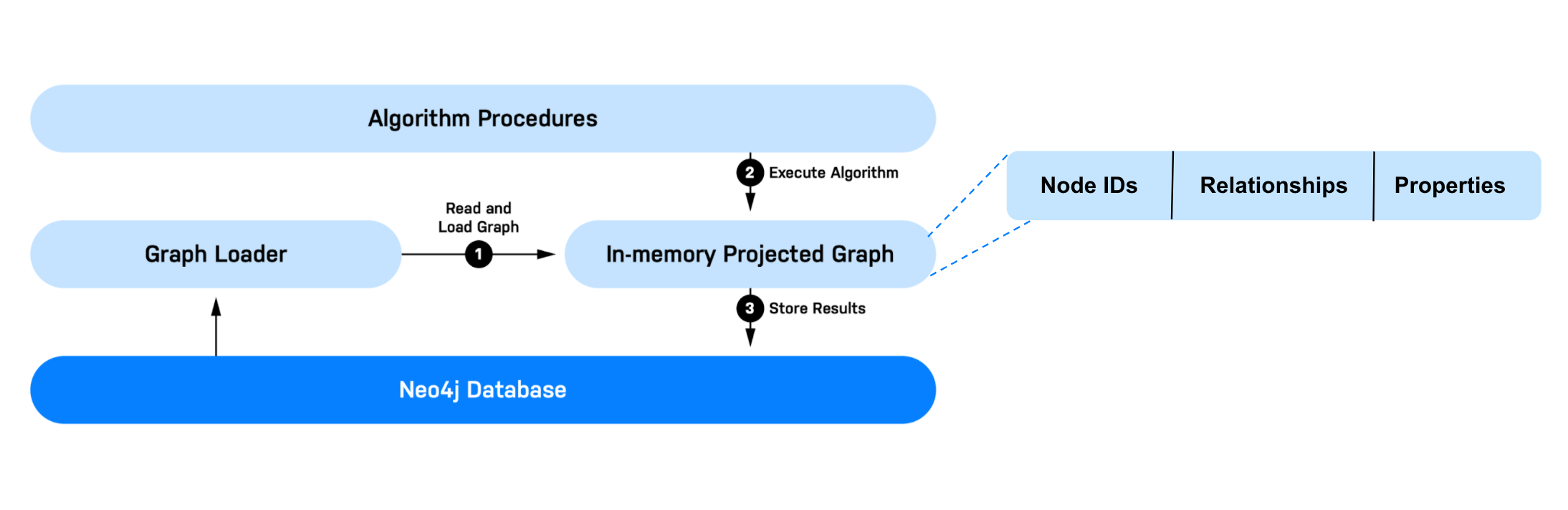
- 读取和加载图: GDS需要从Neo4j数据库中读取数据, 进行转换, 并将其加载到内存图中. 在GDS中, 这个过程称为投射图 (projecting a graph) , 把内存中的图称为图的投影(graph projection) . GDS可以同时容纳多个图的投影, 由一个叫做图目录 (Graph Catalog) 的组件管理. 图目录和图投影管理将在下一个模块中更详细地介绍.
- 执行算法: 包括经典的图算法, 如中心性算法 (centrality) , 社区检测算法 (community detection) , 路径搜索算法 (path finding) 等. 它还包括嵌入法 (embeddings) , 一种强大的图特征工程的形式, 以及机器学习管道 (machine learning pipelines) .
- 储存结果: 结果可以写回到数据库, 以csv格式导出, 或输出到另一个应用程序或下游工作流程.
配置之类的不想看, 而且事实是这前面整个部分我都看不懂. 可恶啊, 本来时间不够我干嘛要从头开始. 可是我啥都爱从头, 有始 (不一定有终) 强迫症.
2 图管理 (Graph Management)
2.1 图目录 (Graph Catalog)
图目录允许在GDS中管理图投影, 包括
- 创建 (投射) 图
- 查看图的细节
- 删除图投影
- 导出图投影
- 将图投影属性写回数据库
2.1.1 图目录怎么用
用以下形式的命令调用图目录操作
CALL gds.graph.<command>
例:
列出当前存在于数据库中的图投影
CALL gds.graph.list()
由于还没有创建任何投影, 将返回一个空列表.
在推荐图中, 我们可以用以下命令从Actor和Movie节点以及ACTED_IN关系中创建一个投影.
CALL gds.graph.project('my-graph-projection', ['Actor','Movie'], 'ACTED_IN')
再次列出图表,我们可以看到刚刚创建的图的信息
CALL gds.graph.list() YIELD graphName, nodeCount, relationshipCount, schema
| graphName | nodeCount | relationshipCount | schema |
|---|---|---|---|
| my-graph-projection | 24568 | 35910 | {"relationships":{"ACTED_IN":{}},"nodes":{"Movie":{},"Actor":{}}} |
2.1.2 运行算法
正如之前提到的, 创建投影是为高效地运行图算法和进行图数据科学提供空间.
例:
计算Actor节点的度中心性 (degree centrality) . 具体的度中心算法 (degree centrality algorithm) 之类的在Neo4j图数据科学基础课程中有介绍. 目前只需要知道它将会计算每个演员参演的电影的数量, 并将数据储存到一个叫numberOfMoviesActedIn的节点属性中 (还不会被写入到数据库中) .
CALL gds.degree.mutate('my-graph-projection', {mutateProperty:'numberOfMoviesActedIn'})
2.1.3 流动和写入节点属性
有时候我们会想从算法计算中获取结果并将结果流向另一个进程或写回数据库. 图目录提供了串流和写入节点以及关系属性的方法.
例:
使用numberOfMoviesActedIn的例子, 我们可以使用streamNodeProperty图目录操作, 根据电影数量获得前10名最高产的演员.
CALL gds.graph.streamNodeProperty('my-graph-projection','numberOfMoviesActedIn')
YIELD nodeId, propertyValue
RETURN gds.util.asNode(nodeId).name AS actorName, propertyValue AS numberOfMoviesActedIn
ORDER BY numberOfMoviesActedIn DESCENDING, actorName LIMIT 10
| actorName | numberOfMoviesActedIn |
|---|---|
| Robert De Niro | 56.0 |
| Bruce Willis | 49.0 |
| Nicolas Cage | 45.0 |
| Samuel L. Jackson | 45.0 |
| Clint Eastwood | 40.0 |
| Michael Caine | 40.0 |
| Gene Hackman | 38.0 |
| John Cusack | 38.0 |
| John Travolta | 38.0 |
| Morgan Freeman | 38.0 |
如果我们想把属性写回数据库, 我们可以使用writeNodeProperties操作.
CALL gds.graph.writeNodeProperties('my-graph-projection',['numberOfMoviesActedIn'], ['Actor'])
然后我们就能查询按电影数量计算的前10名最高产的演员.
MATCH (a:Actor)
RETURN a.name, a.numberOfMoviesActedIn
ORDER BY a.numberOfMoviesActedIn DESCENDING, a.name LIMIT 10
2.1.4 导出图
在数据科学工作流程中, 可能会遇到这样的情况: 在执行完图算法和其他分析后, 需要从图投影中批量导出数据. 例如, 你可能想
- 导出图特征,用于在另一个环境中训练机器学习模型
- 为下游分析或与同事分享需要创建单独的分析视图
- 生成分析结果的快照并保存到文件系统
图目录有两种导出操作:
gds.graph.export将图导出到一个新的数据库中——高效地将投影复制到一个单独的Neo4j数据库中gds.beta.graph.export.csv将图导出到csv文件中
2.1.5 删除图
投影的图形会占用内存, 所以一旦完成了对图形投影的处理, 明智的做法是将其删除.
CALL gds.graph.drop('my-graph-projection')
现在再列出图的投影就又会返回空列表了.
CALL gds.graph.list()
2.1.6 其他图目录操作
图目录中还有一些其他的管理操作, 比如子集投影 (subsetting projections, subgraph projections) , 删除和移除操作. 可以在图目录文档中找到所有操作.
3 原生投影 (Native Projections)
在GDS中有两种主要的投影类型, 原生投影 (Native Projections) 和Cypher投影. 总的来说, 原生投影注重效率和性能的优化, 以支持大规模的图数据科学. Cypher投影注重灵活性和个性化, 更适合探索性分析, 试验和较小的图投影.
3.1 关于原生投影
实际上上文已经使用过原生投影原生投影gds.graph.project(). 原生投影直接从Neo4j存储文件中读取, 提供了最佳性能. 推荐使用于开发和生产阶段.
除了从数据库中原封不动地投射节点和关系元素外, 原生投影还提供了多种其他功能. 下面是其中一些主要的功能:
- 纳入数值型节点和关系属性
- 改变关系方向 (direction) 或 "朝向 (orientation) "
- 聚合平行关系
这些有助于为不同类型的分析工作流程和算法的投影做准备.
下面介绍了原生投影的基本语法已经一些常见的配置.
3.2 基本语法
原生投影有三个强制参数: graphName, nodeProjection和relationshipProjection. 此外, 可选参数configuration允许我们进一步配置图的创建.
| 参数名称 | 类型 | 是否可选 | 描述 |
|---|---|---|---|
graphName |
String | 否 | 图在目录中存储的名称 |
nodeProjection |
String, List or Map | 否 | 投射节点的配置 |
relationshipProjection |
String, List or Map | 否 | 投射关系的配置 |
configuration |
Map | 是 | 配置原生投影的附加参数 |
nodeProjection和relationshipProjection有很多不同的选项. 总之就是用使用实例来介绍基础.
3.3 基础原生投影
首先考虑一个非常基本的情形, 我们想不带任何属性地按原样投射节点和关系. 可以对想包含的节点标签和关系使用类似列表的语法. 例如, 我们投影User节点和Movie节点的RATED关系. 这种类型的投影在基于图数据科学的推荐系统中非常常见, 因为它支持隐式协作过滤 (Implicit Collaborative Filtering) 的变化——一种基于记忆的推荐方法.
CALL gds.graph.project('native-proj',['User', 'Movie'], ['RATED']);
还有各种形式的速记语法. 例如, 如果计划仅包含一个节点标签或关系类型, 可以只使用单个字符串值. 我们可以为 relationshipProjection 输入 RATED 值获得等效的投影.
CALL gds.graph.project('native-proj',['User', 'Movie'], 'RATED');

如果试图用一个已经存在的名字创建一个新的图形投影, 就会报错. 要继续首先要运行gds.graph.drop()来删除现有的图投影.
CALL gds.graph.drop('native-proj');
通配符'*'可以匹配数据库中的所有节点和关系. 以下是对所有节点和关系的投影.
CALL gds.graph.project('native-proj','*', '*');
3.4 改变关系方向
原生投影也允许改变关系的方向. 为了描述好方向的概念, 以及为什么要改变方向, 我们需要介绍定向关系 (directed relationship) 和无定向关系 (undirected relationship) 之间的区别.
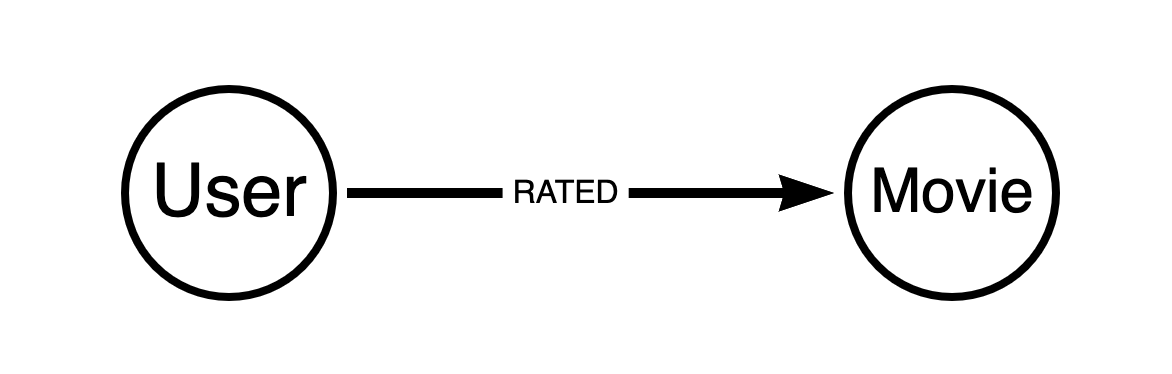
定向关系是不对称的. 它从一个源节点到一个目标节点, 如下图所示. 这种类型的关系可能包含额外的限定属性, 例如一个加权或强度指标 (a weighting or strength indicator) .
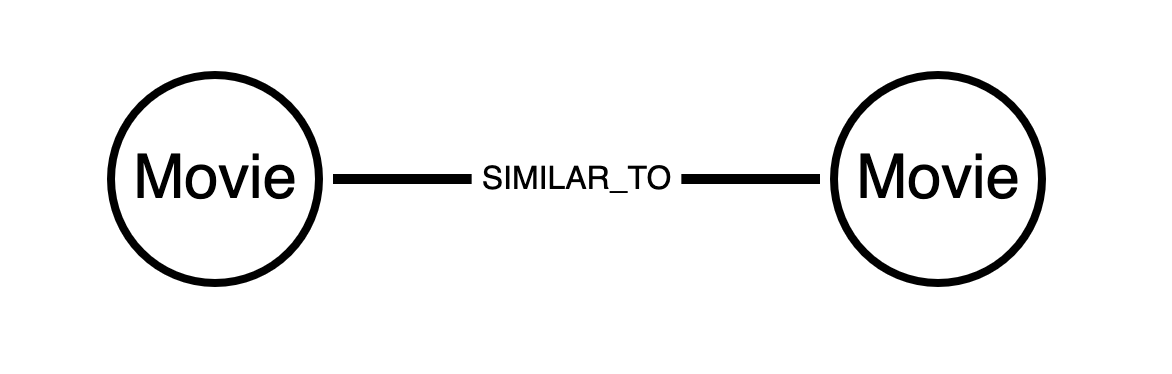
无定向关系是对称的, 没有方向性, 存在于两个节点之间, 没有源或目标.
neo4j数据库中的关系都被设定为定向的. 但是一些图算法作用于无定向关系. 还有一些算法适用于定向关系, 但我们可能需要转换关系的方向来获得我们想要的分析结果.
考虑到这一点, 在relationshipProjection中我们有三个方向相关的选项可以应用于关系类型:
NATURAL: 与数据库中的方向一致 (默认)REVERSE: 与数据库中的方向相反UNDIRECTED: 无定向
以之前投射的图为例. 假设我们想计算每部电影的用户评分的数量. 如果我们像之前那样使用度调用 (degree call) , 所有返回的值都将是零.
CALL gds.graph.drop('native-proj', false);
CALL gds.graph.project('native-proj',['User', 'Movie'], ['RATED']);
CALL gds.degree.mutate('native-proj', {mutateProperty: 'ratingCount'});
CALL gds.graph.streamNodeProperty('native-proj','ratingCount', ['Movie'])
YIELD nodeId, propertyValue
RETURN gds.util.asNode(nodeId).title AS movieTitle, propertyValue AS ratingCount
ORDER BY movieTitle DESCENDING LIMIT 5
| movieTitle | ratingCount |
|---|---|
| İtirazım Var | 0.0 |
| À nous la liberté (Freedom for Us) | 0.0 |
| ¡Three Amigos! | 0.0 |
| xXx: State of the Union | 0.0 |
| xXx | 0.0 |
这个结果与关系的方向有关. 接下来删除这个图然后投射一个RATED关系反过来的新图.
CALL gds.graph.drop('native-proj', false);
//replace with a project that has reversed relationship orientation
CALL gds.graph.project(
'native-proj',
['User', 'Movie'],
{RATED_BY: {type: 'RATED', orientation: 'REVERSE'}}
);
CALL gds.degree.mutate('native-proj', {mutateProperty: 'ratingCount'});
现在再使用度调用 (degree call) 就会得到我们想要的结果.
CALL gds.graph.streamNodeProperty('native-proj','ratingCount', ['Movie'])
YIELD nodeId, propertyValue
RETURN gds.util.asNode(nodeId).title AS movieTitle, propertyValue AS ratingCount
ORDER BY movieTitle DESCENDING LIMIT 5
| movieTitle | ratingCount |
|---|---|
| İtirazım Var | 1.0 |
| À nous la liberté (Freedom for Us) | 1.0 |
| ¡Three Amigos!31.0 | 31.0 |
| xXx: State of the Union | 1.0 |
| xXx | 23.0 |
3.5 纳入节点和关系属性
节点和关系属性在图分析可能会有用, 可以充当图算法的权重和机器学习的特征.
下面是一个纳入了多个movie节点属性和rating关系属性的例子。
CALL gds.graph.drop('native-proj', false);
CALL gds.graph.project(
'native-proj',
['User', 'Movie'],
{RATED: {orientation: 'UNDIRECTED'}},
{
nodeProperties:{
revenue: {defaultValue: 0}, // (1)
budget: {defaultValue: 0},
runtime: {defaultValue: 0}
},
relationshipProperties: ['rating'] // (3)
}
);
注意:
defaultValue参数允许我们用一个默认值来填补缺失值. 此情况我们使用的是0.- 简化语法没有默认值, 因为根据数据模型, 这些值不应该缺少.
如何利用这些属性将在Neo4j Graph Data Science Fundamentals课程中详细介绍. 在设置默认值和替代配置方面有多种不同的选择, 例如为所有节点标签和关系类型设置属性, 而不是为每个节点单独设置. 如果你想了解更多这方面的细节, 请参考文档.
3.6 平行关系聚合
Neo4j数据库允许在两个节点之间存储多个相同类型和方向的关系 (平行关系) . 例如, 在一个金融交易数据图存在用户之间相互汇款. 如果一个用户多次向同一个用户汇款就能形成多个平行关系.

有时你会想把这些平行关系聚合成一个单一的关系, 为运行图算法或机器学习做准备. 因为图算法可能会单独计算两个节点之间的每个关系, 但我们需要考虑的只是它们之间是否存在一种单一的关系. 也有时候我们会想让两个拥有更多平行关系的节点之间的联系的权重更高, 对于一些算法, 如果不先聚合关系会很难实现.
原生投影允许这种聚合. 在进行关系聚合时, 你也可以生成聚合的静态数据, 如平行关系计数或关系属性的总和或平均数, 然后可以作为权重使用.
下面是一个没有任何属性的关系聚合的例子.
CALL gds.graph.project(
'user-proj',
['User'],
{
SENT_MONEY_TO: { aggregation: 'SINGLE' }
}
);
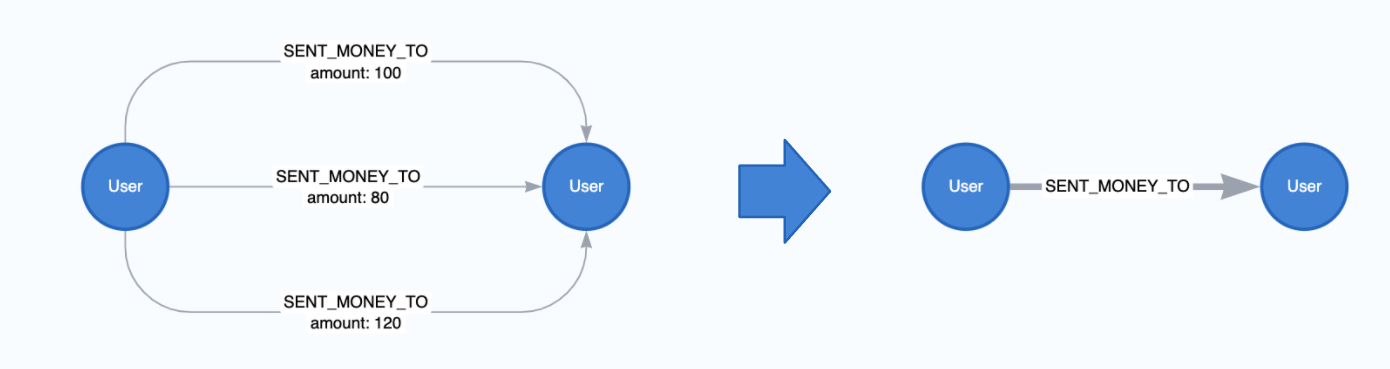
也可以创建一个带有关系数的属性.
CALL gds.graph.project(
'user-proj',
['User'],
{
SENT_MONEY_TO: {
properties: {
numberOfTransactions: {
// the wildcard '*' is a placeholder, signaling that
// the value of the relationship property is derived
// and not based on Neo4j property.
property: '*',
aggregation: 'COUNT'
}
}
}
}
);
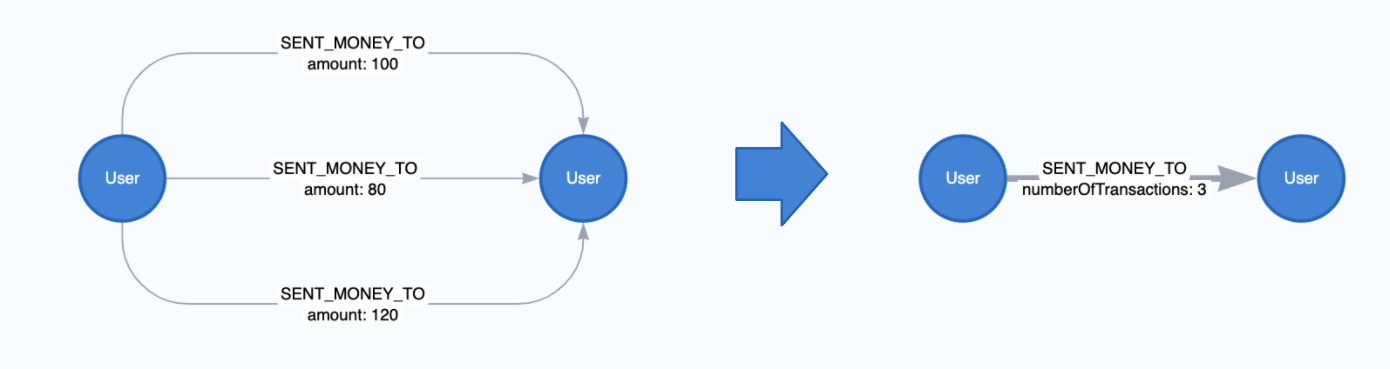
在聚合过程中, 我们也可以取关系属性的总和, 最小或最大. 下面是一个有总和的例子.
CALL gds.graph.project(
'user-proj',
['User'],
{
SENT_MONEY_TO: {
properties: {
totalAmount: {
property: 'amount',
aggregation: 'SUM'
}
}
}
}
);
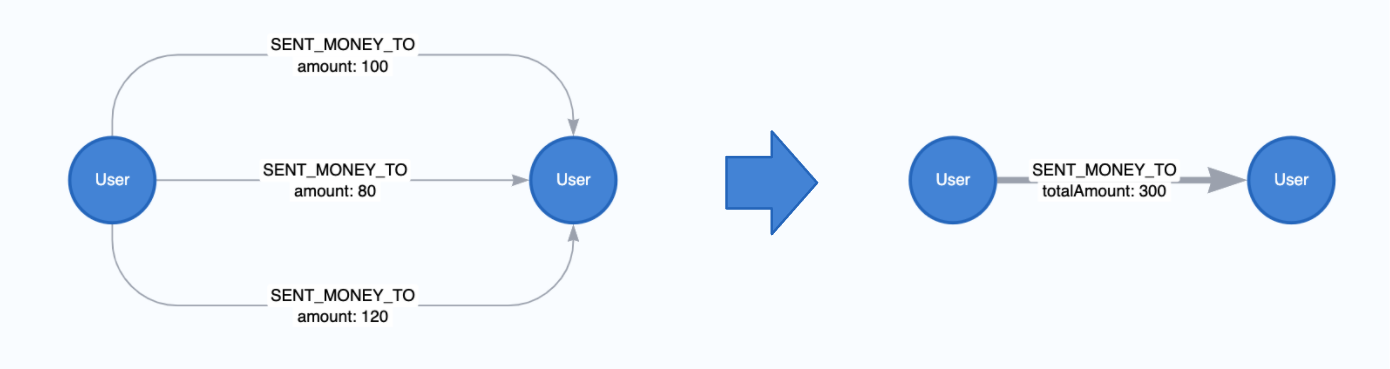
3.7 其他本地投影的配置和功能
这里介绍了基础知识, 但实际上有许多扩展的语法和配置选项可用于原生投影. 一般来说, 不会了就看文档.
4 Cypher投影
虽然原生投影又快又扩展性好, 但它却没有Cypher那样灵活的过滤和聚合能力. Cypher投影使用Cypher来定义投影模式, 更加灵活.
Cypher投影建议用于更需要灵活性和个性化的探索性分析和开发阶段. 也可以用于生产环境, 只探索图的一小部分子集, 如相对较小节点附件区域.
虽然Cypher投影更灵活和个性化, 但比原生投影更耗费性能, 因此在大型图上的表现没有那么快那么好. 使用Cypher投影时要权衡好利弊.
下面将会讨论Cypher投影的语法, 一个很有用的例子, 以及当工作流成熟时从Cypher投影过渡到原生投影的常见策略.
4.1 语法
与原生投影类似, Cypher投影有三个强制参数: graphName, nodeQuery和relationshipQuery. 此外, 可选参数configuration允许我们进一步配置图的创建.
| 参数名称 | 是否可选 | 描述 |
|---|---|---|
graphName |
否 | 图在目录中存储的名称 |
nodeQuery |
否 | 投影节点的Cypher语句. 查询结果必须包含一个id列. 可以选择指定一个labels列来表示节点标签, 其他列做为属性. |
relationshipProjection |
否 | 投影关系的Cypher语句. 查询结果必须包含source和target列. 可以选择指定一个type列来表示关系类型, 其他列做为属性. |
configuration |
是 | 配置Cypher投影的附加参数 |
4.2 应用实例
之前我们根据演员参演过的电影数量来决定哪些演员最多产. 假设我们现在想使用另一种方式度量演员的影响力, 计算近期高票房电影与其一同出演的其他演员的数量.
在这个例子中,如果一部电影是在1990年或之后上映的,我们就称之为 "近期",如果它的收入$\geq$100万美元,我们就称之为高票房。
直接用原生投影不容易解决这个问题. 然而,我们可以使用一个 Cypher 投影获得适当的节点,并直接在Actor节点之间聚合以及创建一个拥有actedWithCount属性的ACTED_WITH关系.
CALL gds.graph.project.cypher(
'proj-cypher',
'MATCH (a:Actor) RETURN id(a) AS id, labels(a) AS labels',
'MATCH (a1:Actor)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(a2)
WHERE m.year >= 1990 AND m.revenue >= 1000000
RETURN id(a1) AS source , id(a2) AS target, count(*) AS actedWithCount, "ACTED_WITH" AS type'
);
然后我们就可以像之前那样应用度中心算法. 我们将通过actedWithCount属性对程度中心性进行加权, 并直接将前10名的结果传输回来. 这就计算出了该演员在最近的高票房电影中与其他演员合作的次数.
CALL gds.degree.stream('proj-cypher',{relationshipWeightProperty: 'actedWithCount'})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC LIMIT 5
| name | score |
|---|---|
| Robert De Niro | 123.0 |
| Bruce Willis | 120.0 |
| Johnny Depp | 102.0 |
| Denzel Washington | 99.0 |
| Nicolas Cage | 90.0 |
4.3 什么时候该使用Cypher投影
在上面的例子中, 有两处无法直接使用原生投影. 它们也恰好是使用Cypher投影的两种最常见的情况.
- 复杂的过滤: 使用节点以及关系属性的条件或其他更复杂的
MATCH/WHERE条件来从图中筛选, 而不仅仅用节点标签和关系类型. - 聚合有权重的多跳路径 (Multi-Hop Paths) : 关系投影需要将
(Actor)-[ACTED_IN]-(Movie)-[ACTED_IN]-(Actor)形式聚合为(Actor)-[ACTED_WITH {actedWithCount}]-(Actor)形式, 其中actedWithCount是关系的权重属性. 这种投影需要将多跳路径转化为连接源节点和目标节点的聚合关系, 在图分析中经常出现.
Cypher投影也有一些其他的特殊用例, 包括合并不同的节点标签和关系类型, 以及根据属性条件或其他查询逻辑定义节点之间的虚拟关系.
4.4 过渡到原生投影
虽然Cypher投影在这些模式的试验和图的小子集上表现很好, 但我们鼓励在工作流程成熟, 图投影变大, 快速性能变得更重要时过渡到原生投影.
例如, 经过上面的计算, 我们可以改用以下工作流程, 利用了原生投影中的塌陷路径 (collapse path) . 这种技术不对产生的关系加权, 所以虽然演员排名不完全相同, 但非常相似.
//set a node label based on recent release and revenue conditions
MATCH (m:Movie)
WHERE m.year >= 1990 AND m.revenue >= 1000000
SET m:RecentBigMovie;
//native projection with reverse relationships
CALL gds.graph.project('proj-native',
['Actor','RecentBigMovie'],
{
ACTED_IN:{type:'ACTED_IN'},
HAS_ACTOR:{type:'ACTED_IN', orientation: 'REVERSE'}
}
);
//collapse path utility for relationship aggregation - no weight property
CALL gds.alpha.collapsePath.mutate('proj-native',{
relationshipTypes: ['ACTED_IN', 'HAS_ACTOR'],
allowSelfLoops: false,
mutateRelationshipType: 'ACTED_WITH'
});
//count actors that acted with the most other actors in recent high grossing movies and stream the top 10
CALL gds.degree.stream('proj-native', {nodeLabels:['Actor'], relationshipTypes: ['ACTED_WITH']})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC LIMIT 10
| name | score |
|---|---|
| Bruce Willis | 114.0 |
| Robert De Niro | 109.0 |
| Denzel Washington | 96.0 |
| Johnny Depp | 90.0 |
| Nicolas Cage | 86.0 |
| Julianne Moore | 84.0 |
| Samuel L. Jackson | 82.0 |
| Morgan Freeman | 81.0 |
| Ben Affleck | 81.0 |
| Brad Pitt | 79.0 |
以下是根据最初的使用情况, 从Cypher投影过渡到本地投影的工作流程的一些一般提示:
- 用节点属性条件进行过滤: 为符合属性条件的节点添加标签, 以便能在原生投影中过滤
- 用关系属性条件进行过滤: 如果可能, 为每个满足属性条件的关系的源节点和目标节点添加一个标签. 否则, 考虑在你的数据模型中添加一个额外的关系类型来获取满足条件的关系.
- 聚合多跳路径:
- 查看坍缩路径是否能满足需求. 它不对关系进行加权, 但结果往往可以与加权的聚合非常相似
- 对于大型投影上的某些类型的问题,可以使用相似性和嵌入算法来近似聚合关系
对于其他复杂的使用场景, 通常会回到你在Neo4j数据库中的数据模型. 是否有可能调整你的数据模型, 使节点标签和关系类型更好地区分你想要过滤的数据, 以用于数据科学? 这可能涉及到将某些路径聚合成单一的关系, 开发更多的节点标签和或关系类型, 或其他类型的转换.
本文作者:ZZN而已
本文链接:https://www.cnblogs.com/zerozhao/p/neo4j-gds-intro.html
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号