MySQL索引的基本使用
转自:https://www.cnblogs.com/whgk/p/6179612.html
一、什么是索引?为什么要建立索引?
索引用于快速找出在某一列中有一特定值的行。如果不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行;表越大,查询数据所花费的时间就越多。如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
例如:有一张person表,其中有2W条记录。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。如果有了索引且将Phone字段设置为索引,那么会将该Phone字段通过一定的方法进行存储,以便查询该字段上的信息时能够快速找到对应的数据,而不必在遍历2W条数据了。
其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段。
二、MySQL中索引的优点和缺点和使用原则
优点:
1、所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
2、大大加快数据的查询速度
缺点:
1、空间上:
索引需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
2、时间上:
a. 创建索引要耗费时间
b. 维护索引也要耗费时间,并且随着数据量的增加所耗费的时间也会增加(当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。)
使用原则:
通过上面说的优点和缺点,我们应该可以知道,并不是每个字段度设置索引就好,也不是索引越多越好,而是需要自己合理的使用。
1、对经常更新的表就避免对其创建索引,对经常用于查询的字段应该创建索引,
2、数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
3、在不同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在不同值较多的字段上建立索引。
4、不常用的字段不要建立索引
5、字段特别长的,比如text,不要建立索引
三、索引的分类
注意:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
MyISAM和InnoDB存储引擎:只支持BTREE索引
MEMORY/HEAP存储引擎:支持HASH和BTREE索引
索引我们分为四类来讲 单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引、
1.1、单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了。
1.1.1、普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
1.1.2、唯一索引:索引列中的值必须是唯一的,但是允许为空值,
1.1.3、主键索引:是一种特殊的唯一索引,不允许有空值。
1.2、组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。
1.3、全文索引:全文索引只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引;介绍了要求,再说说什么是全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"MySQL索引学习记录"这句话,通过"索引",可能就可以找到该条记录。这里说的是可能,因为全文索引的使用涉及了很多细节,这里只描述了大概意思。
1.4、空间索引:空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。在创建空间索引时,使用SPATIAL关键字。要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。具体细节见下。
四、索引操作(创建和删除)
4.1、创建索引
4.1.1.1、创建普通索引
在创建表时,创建普通索引(使用index或key)
CREATE TABLE book ( bookid INT NOT NULL, bookname VARCHAR(255) NOT NULL, authors VARCHAR(255) NOT NULL, info VARCHAR(255) NULL, comment VARCHAR(255) NULL, year_publication YEAR NOT NULL, INDEX(year_publication) ); CREATE TABLE book2 ( bookid INT NOT NULL, bookname VARCHAR(255) NOT NULL, authors VARCHAR(255) NOT NULL, info VARCHAR(255) NULL, comment VARCHAR(255) NULL, year_publication YEAR NOT NULL, KEY(year_publication) );
测试:是否使用了索引进行查询。(explain是用来验证是否使用了索引)
EXPLAIN SELECT * FROM book WHERE year_publication = 1990;
说明:虽然表中没数据,但是有EXPLAIN关键字,用来查看索引是否正在被使用,并且输出其使用的索引的信息。

id: SELECT识别符。这是SELECT的查询序列号,也就是一条语句中,该select是第几次出现。在次语句中,select就只有一个,所以是1.
select_type:所使用的SELECT查询类型,SIMPLE表示为简单的SELECT,不实用UNION或子查询,就为简单的SELECT。也就是说在该SELECT查询时会使用索引。其他取值,PRIMARY:最外面的SELECT.在拥有子查询时,就会出现两个以上的SELECT。UNION:union(两张表连接)中的第二个或后面的select语句 SUBQUERY:在子查询中,第二SELECT。
table:数据表的名字。他们按被读取的先后顺序排列,这里因为只查询一张表,所以只显示book
type:https://blog.csdn.net/dennis211/article/details/78170079
possible_keys:MySQL在搜索数据记录时可以选用的各个索引,该表中就只有一个索引,year_publication
key:实际选用的索引
key_len:显示了mysql使用索引的长度,当 key 字段的值为 null时,索引的长度就是 null。注意,key_len的值可以告诉你在联合索引中mysql会真正使用了哪些索引。
ref:给出关联关系中另一个数据表中数据列的名字。常量(const),这里使用的是1990,就是常量。
rows:MySQL在执行这个查询时预计会从这个数据表里读出的数据行的个数。
extra:提供了与关联操作有关的信息,没有则什么都不写。
上面的一大堆东西能看懂多少看多少,我们最主要的是看possible_keys和key 这两个属性,上面显示了key为year_publication。说明使用了索引。
4.1.1.2、创建唯一索引
CREATE TABLE t1 ( id INT NOT NULL, name CHAR(30) NOT NULL, UNIQUE INDEX UniqIdx(id) );
解释:对id字段使用了索引,并且索引名字为UniqIdx。
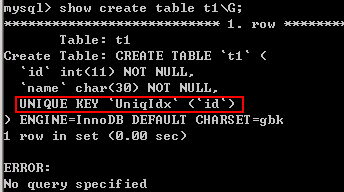
要查看其中查询时使用的索引,必须先往表中插入数据,然后再查询数据,不然查找一个没有的id值,是不会使用索引的。(?原因:原因是所有的id应该会存储到一个const tables中,到其中并没有该id值,那么就没有查找的必要了。)
INSERT INTO t1 VALUES(1,'xxx');
1). 查询:
SELECT * FROM t1 WHERE id = 1;
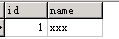
2). 验证是否使用索引:
EXPLAIN SELECT * FROM t1 WHERE id = 1;

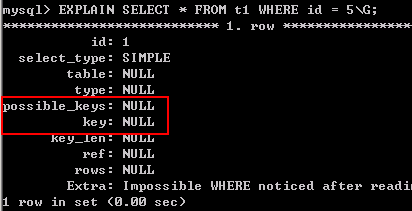
3). 查询一个表中不存在的id值,则不会使用索引:
EXPLAIN SELECT * FROM t1 WHERE id = 5;
4.1.1.3、创建主键索引
CREATE TABLE t2 ( id INT NOT NULL, name CHAR(10), PRIMARY KEY(id) );
插入数据并查询:
INSERT INTO t2 VALUES(1,'QQQ'); EXPLAIN SELECT * FROM t2 WHERE id = 1;

note:我们以前声明的主键约束,就是一个主键索引
4.1.1.4、创建单列索引
前面几个例子就是单列索引。
4.1.1.5、创建组合索引
组合索引就是在多个字段上创建一个索引
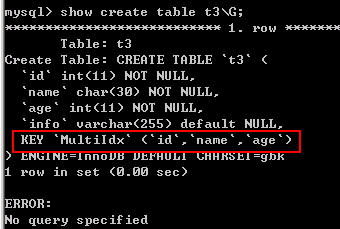
例子;创建一个表t3,在表中的id、name和age字段上建立组合索引
CREATE TABLE t3 ( id INT NOT NULL, name CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR(255), INDEX MultiIdx(id,name,age) );
最左前缀:
组合索引就是遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀。
例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引可以索引下面字段组合(id,name,age)、(id,name)、(id,age)或者(id)。如果要查询的字段不构成索引最左面的前缀,那么就不会是用索引,比如,name、age或者(name,age)组合就不会使用索引查询
插入数据:
INSERT INTO t3 VALUES(1,'jack',23,'student');
1). 查询id和name字段
EXPLAIN SELECT * FROM t3 WHERE id = 1 AND name = 'jack';

2). 查询(age,name)字段,这样就不会使用索引查询
EXPLAIN SELECT * FROM t3 WHERE age = 23 AND name = 'jack';

关于使用索引后,查询结果的返回顺序问题
1). 创建表t6,在sorcerer和name上创建组合索引
CREATE TABLE t6 ( id INT NOT NULL, name CHAR(30) NOT NULL, age INT NOT NULL, sorce INT, INDEX index_sorce_name(sorce,name) ); INSERT INTO t6 VALUES(8,'jack',23,80),(9,'john',24,80),(10,'tom',25,80),(11,'jack',25,80),(12,'john',24,80);
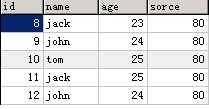
2). 查询所有成绩为80的行
SELECT * FROM t6 WHERE sorce = 80;
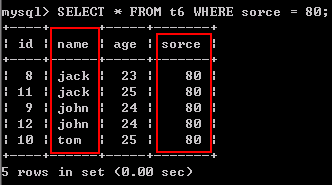
可以看出,结果按name和score来进行排序
3). 查看是否使用了索引
EXPLAIN SELECT * FROM t6 WHERE sorce = 80;

4). 删除索引后,再查询
DROP INDEX index_sorce_name on t6; SELECT * FROM t6 WHERE sorce = 80;
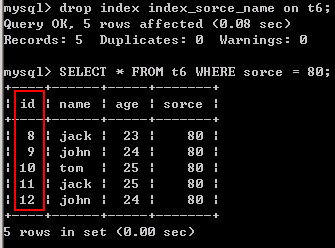
可以看出,结果按照id进行排序
4.1.1.6、创建全文索引
全文索引可以用于全文搜索,但只有MyISAM存储引擎支持FULLTEXT索引,并且只为CHAR、VARCHAR和TEXT列服务。索引总是对整个列进行,不支持前缀索引。
CREATE TABLE t4 ( id INT NOT NULL, name CHAR(30) NOT NULL, age INT NOT NULL, info VARCHAR(255), FULLTEXT INDEX FullTxtIdx(info) )ENGINE=MyISAM;
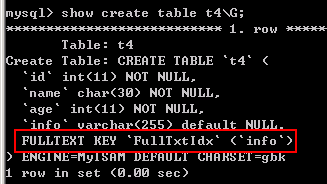 (这里test数据库中,表t4的存储引擎为MyISAM)
(这里test数据库中,表t4的存储引擎为MyISAM)
什么叫做全文搜索:就是在很多文字中,通过关键字就能够找到该记录。
插入数据:
INSERT INTO t4 VALUES(8,'jack',3,'text is so good,hei,my name is bob'),(9,'john',4,'my name is gorlr'),(10,tom,5,'mysql index test');
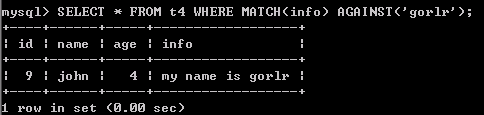
1). 查询:
SELECT * FROM t4 WHERE MATCH(info) AGAINST('gorlr');
2). 测试是否使用了索引进行查询:
EXPLAIN SELECT * FROM t4 WHERE MATCH(info) AGAINST('gorlr');

note:在使用全文搜索时,需要借助MATCH函数,并且其全文搜索的限制比较多,比如只能通过MyISAM引擎;比如只能在CHAR,VARCHAR,TEXT上设置全文索引;比如搜索的关键字默认至少要4个字符,搜索的关键字太短就会被忽略掉;比如表中至少要有三行数据才能搜到;等等。参考这里。
4.1.1.7、创建空间索引
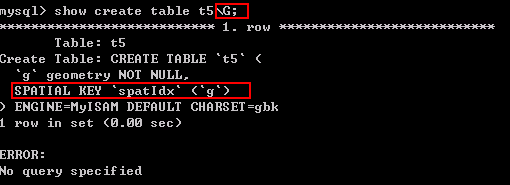
空间索引也必须使用MyISAM引擎, 并且空间类型的字段必须为非空。具体应用未明白。
CREATE TABLE t5 ( g GEOMETRY NOT NULL, SPATIAL INDEX spatIdx(g) ) ENGINE = MyISAM;
4.1.2.1、查看已经创建的索引
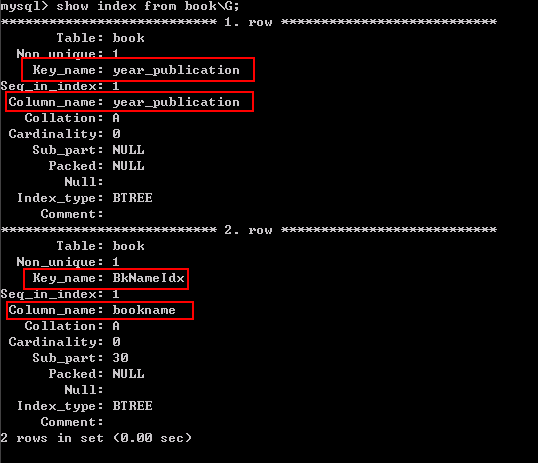
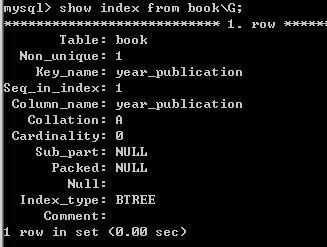
SHOW INDEX FROM 表名\G; #(\G只是让输出的格式更好看)
Table:创建索引的表
Non_unique:表示索引非唯一,1代表 非唯一索引, 0代表 唯一索引,意思就是该索引是不是唯一索引
Key_name:索引名称
Seq_in_index 表示该字段在索引中的位置,单列索引的话该值为1,组合索引为每个字段在索引定义中的顺序(这个只需要知道单列索引该值就为1,组合索引为别的)
Column_name:表示定义索引的列字段
Sub_part:表示索引的长度
Null:表示该字段是否能为空值
Index_type:表示索引类型
4.1.2.2、在已经存在的表上创建索引
1). 使用ADD INDEX
格式:ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (索引字段名)[ASC|DESC]
以book表为例,本来已经有了一个year_publication,现在我们为该表在加一个普通索引
ALTER TABLE book ADD INDEX BkNameIdx(bookname(30));
2). 使用CREATE INDEX创建索引
格式:CREATE [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] 索引名称 ON 表名(创建索引的字段名[length])[ASC|DESC]
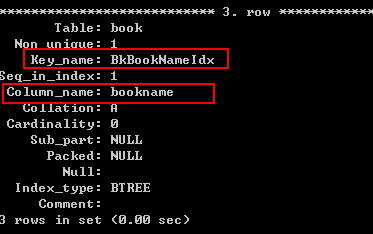
例:为book表增加一个普通索引,字段为authors
CREATE INDEX BkBookNameIdx ON book(bookname);
添加索引的两种方式
1. 在创建表的同时创建索引;
2. 在创建了表之后给表添加索引。
4.2、删除索引
删除索引的两种操作
格式一:ALTER TABLE 表名 DROP INDEX 索引名。
例:删除book表中的名称为BkBookNameIdx的索引。
ALTER TABLE book DROP INDEX BkBookNameIdx;
格式二:DROP INDEX 索引名 ON 表名;
例:删除book表中名为BkNameIdx的索引
DROP INDEX BkNameIdx ON book;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号