
如何用 Python 爬取微博评论,通过王某宏事件来手把手教学
今年某圈真热闹,一个料还没过多久一个新料就被爆出来了,吃瓜群众是吃了一茬又一茬
本来公号没有打算写关于 王某宏 相关的技术文,但周末看网友对此事件热度不减,并且热点聚焦在于微博上,之前呢也没采集过微博的相关数据,刚好借此学习一下
一方面可以借机蹭个热度(虽然热度已经算是过去了),另一方面可以学一下新知识,这样做一件事就有双倍快乐 ~,本文主要通过采集了女主最热微博下的部分评论数据,以技术角度对本事件做了简单的可视化分析。
介绍一下本文用到的技术栈:
语言、框架:Python、Vue;
数据存储:MongoDB、txt;
库: WordCloud、jieba、bs4 等;
数据采集
数据是后面所有可视化分析的前提,本文采集的是 女主石锤王某宏的那条微博,9张图总字数达近5000,信息量很大,目前下方评论数量已达 40 万左右
这里借助的是微博老式网页版提供的接口,基本没有什么反爬措施,需要在请求头中加入 Cookie、User-Agent 参数即可,,但还是提醒一点不要访问太过频繁,否则会返回 403 状态码。核心代码如下
headers = {
"Cookie":"你的Cookie",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept-Language": "h-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6",
"Accept":"application/json",
"Content-Type":"application/json;charset=UTF-8",
"refer": "https://weibo.cn/",
}
def parseUrl(page):
url = "https://weibo.cn/comment/hot/L6w2sfDXb"
params = {
"rl": 1,
"page": page,
}
if(page != 1):
# 更换 refer
headers['refer'] = "https://weibo.cn/comment/hot/L6w2sfDXb?rl=1&page={}".format(page-1)
# 格式转换;
res = requests.get(url =url,headers=headers,params=params)
print("request url is {} page is {} response status is {}".format(url,page,res.status_code))
resText = res.content.decode(encoding='utf-8')
soup = BeautifulSoup(resText,'lxml')
# select 正则匹配
for comment_item in soup.select('div[id^="C_"]'):
userName = comment_item.contents[0].text
comment = comment_item.contents[-9].text
likeInfo = comment_item.contents[-5].text
timeInfo = comment_item.contents[-1].text.split("\xa0")[0]
data_info = {
"userName": userName,
"comment": comment,
"likeCount": likeInfo,
"timeInfo": timeInfo
}
if not (collection.find_one({"userName":userName})):
'''查询之前进行一次过滤'''
print("data _json is {}".format(data_info))
collection.insert_one(data_info)
if __name__ =='__main__':
# 爬取之前清空数据库
collection.delete_many({})
time_unit = [0.5,1,2,0.2,0.4,1.2,1.3,0.9]
for i in range(100000):
time.sleep(random.choice(time_uint))
parseUrl(page=i)
需要说明一下,此接口采用分页机制;即使访问的是不同页码下的 url,但采集到的的数据依旧会出现大量重复现象,所以在保存之前或者数据清洗时,建议做一下去重处理:
从上图可以看到,微博为了呈现好一点的可视化效果, timeInfo 字段(代表评论时间)是中文+字符方式展示,在数据可视化之前,需要先做一个时间格式转换,统一与 2021-12-18 05:07:00 相一致,这里我写了个简单的转换函数:
def conver_timeformat(timeStr):
'时间格式转换'
if "今天" in timeStr:
result = re.search("今天[\s\S](\d{1,2}):(\d{1,2})",timeStr)
if(len(result.groups()) ==2):
timeInfo = format(datetime(year=2021,
month=12,
day=19,
hour=int(result.group(1)),
minute= int(result.group(2)),
second=0),
"%Y-%m-%d %H:%M:%S")
else:
timeInfo = format(datetime.now(),"%Y-%m-%d %H:%M:%S")
return timeInfo
if "分钟" in timeStr:
timeInfo = format(datetime.now(), "%Y-%m-%d %H:%M:%S")
return timeInfo
if "月" in timeStr:
result = re.search("(\d{1,2})月(\d{1,2})日[\s\S](\d{1,2}):(\d{1,2})", timeStr)
if (len(result.groups()) == 4):
timeInfo = format(datetime(year=2021,
month=int(result.group(1)),
day=int(result.group(2)),
hour=int(result.group(3)),
minute=int(result.group(4)),
second= 0),
"%Y-%m-%d %H:%M:%S")
return timeInfo
raise RuntimeError("{} 时间格式无法转换".format(timeStr))
可视化分析
评论时间分布
首先,本文对评论的时间分布做一个可视化展示,效果如下:
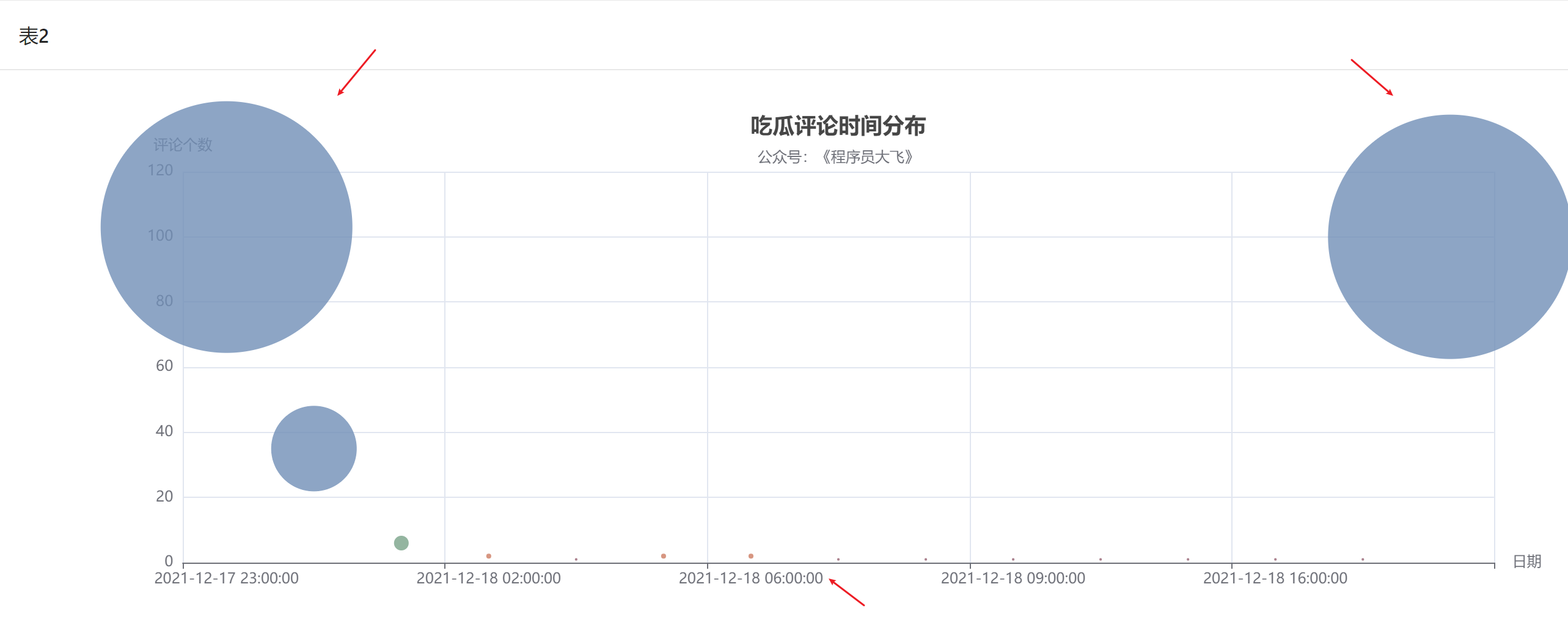
可能采集的数据样本只限于热评【点赞指标】部分,因此时间分布方面出现极大均衡性,整体上评论数集中于两个时间点:17日的 23 时刻,20 日的 0点时刻,而这两个点分别对应女方首次发微博锤男方不端、男方就此事件首次做出回应,,而此时的我正在写这篇文章😢
词云可视化
想看看网友针对此件事情在女方微博都评论了些什么,这里通过两张词云图简单汇总下:

加油、总结、支持 、转移财产 是这张图频率出现最多的词语,都是对女主的鼓励,满满都是正能量

看到这张词云图后,emm怎么说呢,与前面一张词云图对比一下,这张图满满都是对男主的行为的控诉,这张图比较突出的几个词大家自己看吧,这里就不点出来了;另外图中模糊区域是对某些不是很恰当的词语打了下码。
最后,根据评论点赞数对网友评论做了排序,这里选取了其中几个,贴在下方:
获赞个数【97961】
13年结婚14年一胎16年二胎18年三胎……八年婚姻 怀孕生产月子奶娃养娃几乎占据了全部……到头来……做女生 实惨 很讨厌 不喜欢 很烦
--- 利德森医疗
获赞个数【230668】
原来你这么不容易!他居然在玩人设?还能相信感情吗??都怎么了这些人一个个的…唉…'
--- 美女不能秃头
获赞个数【9663】
张爱玲曾写下: 最难熬的日子,都过去了 那种闭着眼,都流泪的感觉 这一辈子都不想再体会了 如今已不再奢求什么陪伴 因为下雨天,连影子都会离开 始于心甘情愿,终于愿赌服输 生不逢时,爱不逢人 所到之处皆是命数 希望以后的日子里 百毒不侵,活的认真, 笑的放肆 抬头遇见的都是柔情@李靚蕾Jinglei
--- Nicole甜儿
小结
本文源码数据获取方式,关注微信公众号【小张Python】,后台回复关键字:211220 即可
好了,以上就是本文的全部内容了,如果对你有所帮助的话,不妨点个赞就是对我最大的鼓励,下期见~
注:本文内容不代表任何立场,仅供学习知识分享,望周知!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号