
针对复杂场景的 OCR 文本识别,推荐一个Python 库!
大家好,我是 zeroing~
1,前言
之前谈到图片文本 OCR 识别时,写过一篇文章介绍了一个 Python 包 pytesseract ,具体内容可参考
介绍一个Python 包 ,几行代码可实现 OCR 文本识别!这篇文章 ,pytesseract 包是基于 Tesseract 封装得到的,这个包虽然支持多语言文本识别,但对于不同语言文本识别,准确率却不一样,例如英文识别准确率高,而中文文本较低;
英文字符识别,整体来看基本不会出错,但对于图片中的中文字符,经常出现乱码、识别失败,
2,EasyOCR 介绍
今天将介绍一个的用于 文本OCR 新的Python 包 EasyOCR ,这个包是基于训练好的 Deep Learning 模型开发的,模型包含功能:文本检测、文本识别
EasyOCR 包从开源到现在 10 个月不到,但在 Github 已经有 10k+ star,到目前为止经过四次版本迭代,有以下几个特点:
- 1,到目前为止 支持70+种语言文本识别,包括但不限于 英语、中文、日语、韩语等;
- 2,源于深度学习技术,识别精度很高;对于正常图片文本识别来说,准确率能达到 100% ;

- 3,不仅适用于单语言,同样也适用于多语言(例如一张图片中需要同时识别中文、英语、日语三类语言);

- 4,支持 GPU 加速,GPU 识别速度要比 CPU 快 6~7 倍;(需要提前配置好 cuda、 pytorch、torchvision Python 环境);
对比传统 OCR 只具有图片文本识别之外,EasyOCR 还具有 文本检测 功能(图片中识别到的文本框,在图片中的定位以 左上、右上、右下、左下 坐标顺序依次返回),效果如下图:

上图中 EasyOCR 最终输出的是右图的 文本信息 ,左图中的红色线框是后面经处理加上去的
3,EasyOCR 使用
上面对 EasyOCR 程序包做了简单介绍,下面介绍一下它的基本用法
安装
EasyOCR 已经上传到 Pypi 上面了,可通过 pip 命令完成安装
pip install easyocr
EasyOCR 的模型是基于 pytorch 框架训练的,在 easyocr 下载同时会下载一些其它附加 python 包,例如 pytorch, torchvision 等,时间需要久一点(需要注意下,easyocr 默认安装的是 pytorch 的 cpu 版本,需要 gpu 配置的小伙伴可以搜一下 pytorch-gpu 相关教程进行配置);
使用方法
虽然 EasyOCR 安装步骤很简单,只有一行代码;但使用过程中会出现包版本不匹配、环境项缺失 等问题,在使用过程中,我遇到了两个因为环境错误导致无法使用的问题,这里我贴在下方并附上解决方案,遇到的小伙伴们可以参考下,当然没遇到的话更好
1,from ._remap import _map_array
ImportError: DLL load failed: The specified module could not be found
该问题是由于 C++ 运行包丢失造成的,解决方案,终端输入以下命令安装即可
pip install msvc-runtime
**2,train error : ImportError: cannot import name 'Optional' **
该问题是由于 pytorch 与 torchvision 版本不符造成的,安装 easyocr 时默认安装的 torchvision 版本为 0.5.0,对应 pytorch 相兼容的版本应该为 1.4.0,但通过下方命令安装时
pip install torch==1.14.0
会安装失败,解决方法:通过另一种 安装命令即可
pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.htm
easyocr 将所有功能都封装到一个类中 Reader ,可通过调用类里面的三种方法 readtext、detect、recognize 来实现,
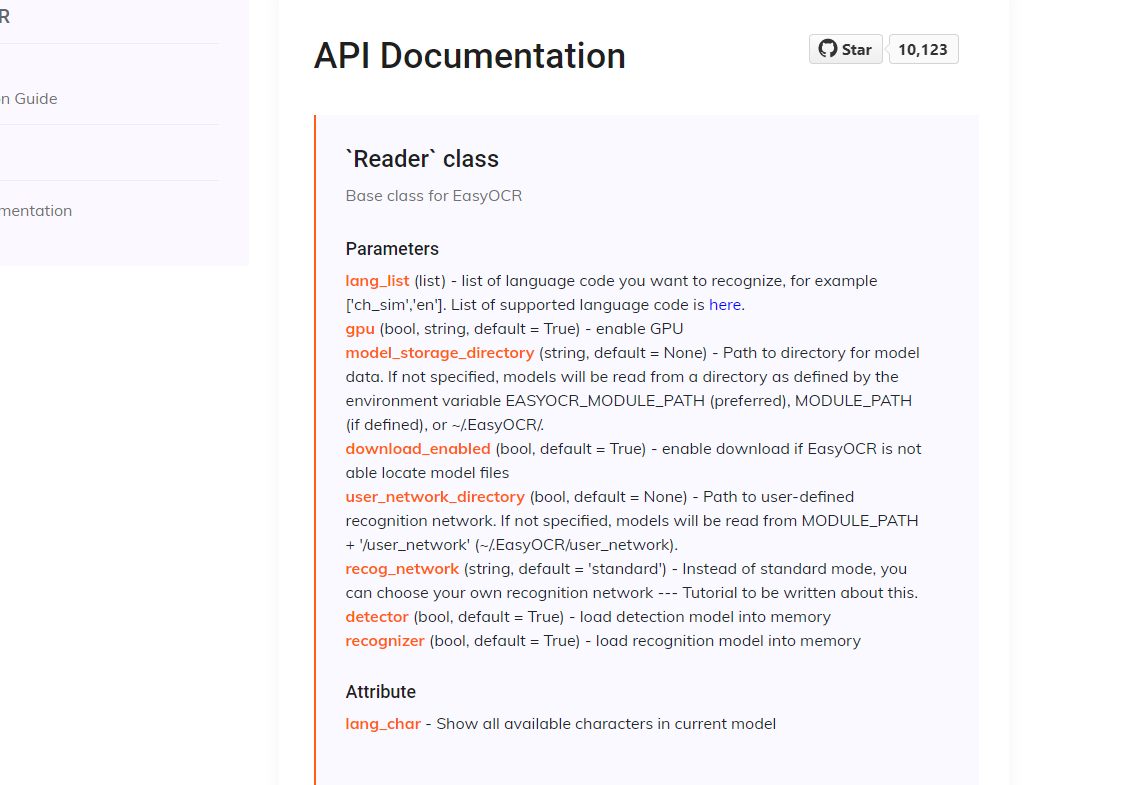
detect 方法用于检测图像中的文本框,最终返回两个列表,来表示文本框在图像中的位置,一个为 horizontal_list 格式为 [x_min,x_max,y_min,y_max] ,另一个为 free_list ,格式为 [[x1,y1],[x2,y2],[x3,y3],[x4,y4]],

上面这张图是 B 站用于在用户登录时弹出的验证码界面,在接下来的例子中都以这张图作为模板,detect 函数的使用方法如下
import easyocr
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.detect('ceshi.png')
print(result)
### ouput
([[11, 133, 11, 31], [158, 238, 2, 34], [199, 235, 315, 333]], [])
使用时,首先需要创建一个 Reader 类,在类中需要指定一些参数:
- lang_list,用来指定需要识别语言代码(例如中文、英文),以列表形式存放,关于语言代码可参考下方(这里只贴出部分,详情可参考官网):
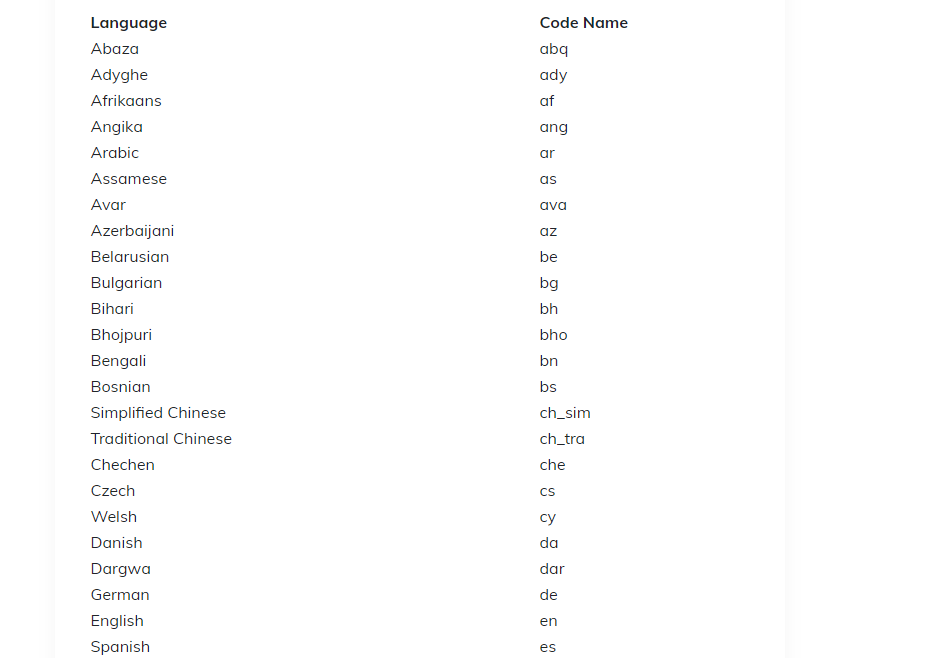
- gpu,布尔值,表示是否需要使用GPU,默认为 True;
- model_storage_directoy,字符串类型,默认为
~./EasyOCR/.用于指定网络模型的存储路径,建议自己指定一个新路径;
最终会输出两个列表,分别表示 horizontal_list, free_list
recognize 用于识别,使用该函数时需要提供三个参数,image、horizontal_list、free_list,使用时与 detect 相搭配
- image 表示图片;
- horizontal_list、free_list 分别表示矩形文本框列表,是函数
detect的两个输出列表
使用方法如下
import easyocr
from PIL import Image,ImageDraw
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.recognize('ceshi.png',horizontal_list=[[11, 133, 11, 31], [158, 238, 2, 34], [199, 235, 315, 333]],free_list=[])
print(result)
### output
[([[158, 2], [238, 2], [238, 34], [158, 34]], '带鱼', 0.48613545298576355), ([[11, 11], [133, 11], [133, 31], [11, 31]], '清在下图依次点击:', 0.46184659004211426), ([[199, 315], [235, 315], [235, 333], [199, 333]], '确认', 0.31680089235305786)]
最终 recognize 方法会返回每个文本框中的文本信息
readtext 函数是将 detect 和 recognize 方法相结合:先利用 detect 函数识别图像中文本框的位置坐标,将坐标列表输入 recognize 进行识别,最终返回每个文本信息及位置坐标,函数框架如下:
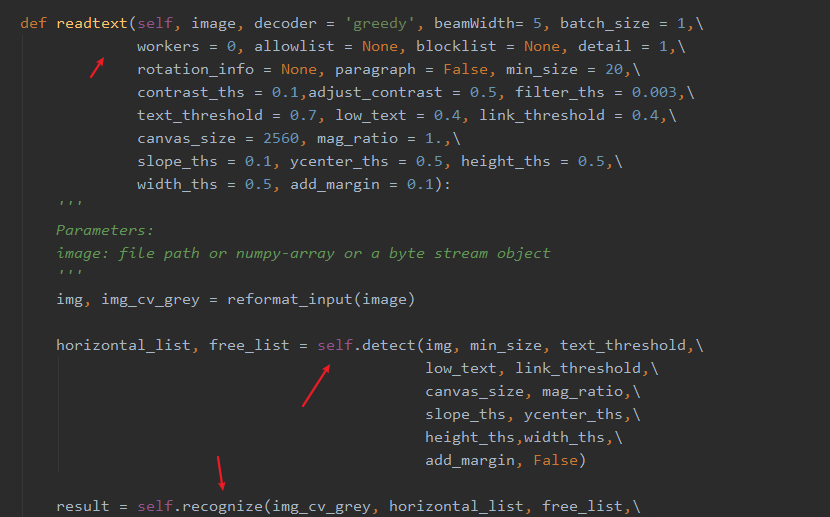
import easyocr
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.readtext('ceshi.png')
print(result)
### ouput
Using CPU. Note: This module is much faster with a GPU.
[([[158, 2], [238, 2], [238, 34], [158, 34]], '带鱼', 0.48613545298576355), ([[11, 11], [133, 11], [133, 31], [11, 31]], '清在下图依次点击:', 0.46184659004211426), ([[199, 315], [235, 315], [235, 333], [199, 333]], '确认', 0.31680089235305786)]
得到坐标之后,为了更直观地观察到检测结果的正确性,可通过 PIL 把图像中文本框给绘制出来
import easyocr
from PIL import Image,ImageDraw
reader = easyocr.Reader(['ch_sim','en'],gpu=False,model_storage_directory='./model')
result = reader.readtext('ceshi.png')
img = Image.open('ceshi.png')
draw = ImageDraw.Draw(img)
for i in result:
draw.rectangle((tuple(i[0][0]),tuple(i[0][2])),fill=None,outline='red',width=2)
img.save("ceshi3.png")
效果如下

结果来看,除了图片中间的 带鱼 文本信息没有识别出来之外,其他区域的文本信息都能取得不错的识别和检测效果;
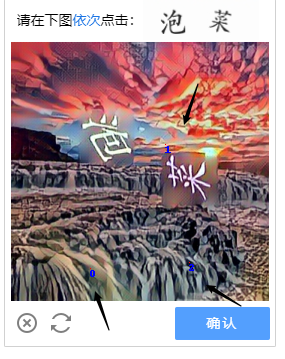
这里解释一下识别失败的原因,仔细观察的话会发现上面这张图并不是现实中真实存在的,而是通过深度学习技术生成的一个虚拟图像例如 GAN,里面的文本信息不是单一地将文字贴到图片上,我猜测是经过一些加密处理,
为了验证我的猜测,这里我借助了超级鹰打码平提供的API 接口,但最终依然得不到很好的识别效果(图中的蓝色字体位置代表打码平台识别结果)
上面只介绍了easyocr 方法中 的一些常规参数,还有许多默认参数没有介绍,比如 batch_size 控制每次识别图片的数量,有了这个参数可以实现批量识别,但前提需要 GPU 大内存的支撑;adjust_contrast 调整图像对比度;
关于 easyocr 更多详细信息,感兴趣的小伙伴可看官方文档:Document API,
好了,以上就是本篇文章全部内容,最后感谢大家的阅读!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号