零成本 API 服务搭建,用 GitHub Actions 自动爬取文章?
2024-08-17 10:50 北桥苏 阅读(295) 评论(0) 收藏 举报前言
本着将成本降到最低,我目前做的应用或小程序都是单机的,也就是不用请求接口,只要一上架就没有任何支出。但是写死的数据毕竟有限,应用的内容单一无法紧跟时事热点,每次打开一个样,自然就没有留存。遇到有错字啥还要更新版本,那有没有方法既能丰富应用内容,又不用增加成本呢?
既要又要,当然也有,找网上提供的免费 API 接上去。但是这种有请求数限制,而且还和自己应用的业务不相关,那就只能自己弄接口了。
既然可以在 GitHub 上搭静态博客,那整一个静态 API (json 文件),时不时地更新或提交新的 json 文件上去,在 C 端应用上不也看起来像是动态的了。所以下面就实践一下如何在 GitHub 上搭建 API 服务,以及如何自动化更新数据(部署爬虫)?
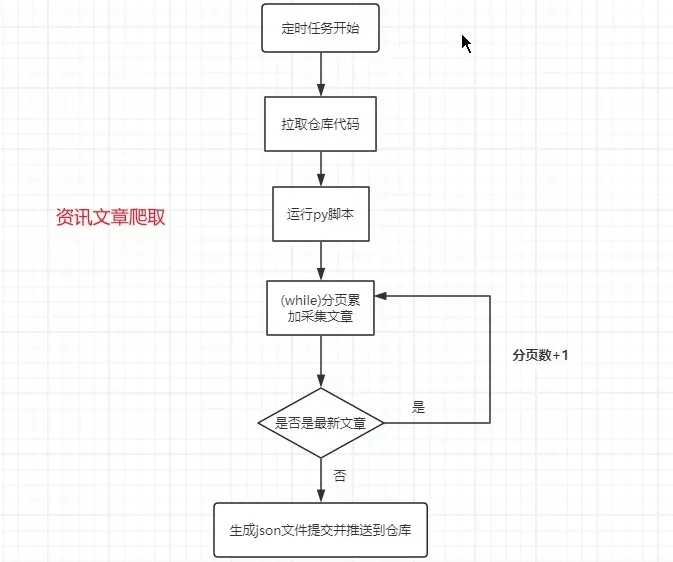
API 服务搭建
方法和之前在 GitHub 上搭建 Hexo 类似,就是给仓库开启 GitHub Pages,可以自行绑定域名,也可以用之前主仓设置的域名后面带当前仓库名访问。当前域名要备案过了,然后用访问资源的方式能访问到 json 文件 (xml、csv 等) 就可以了。
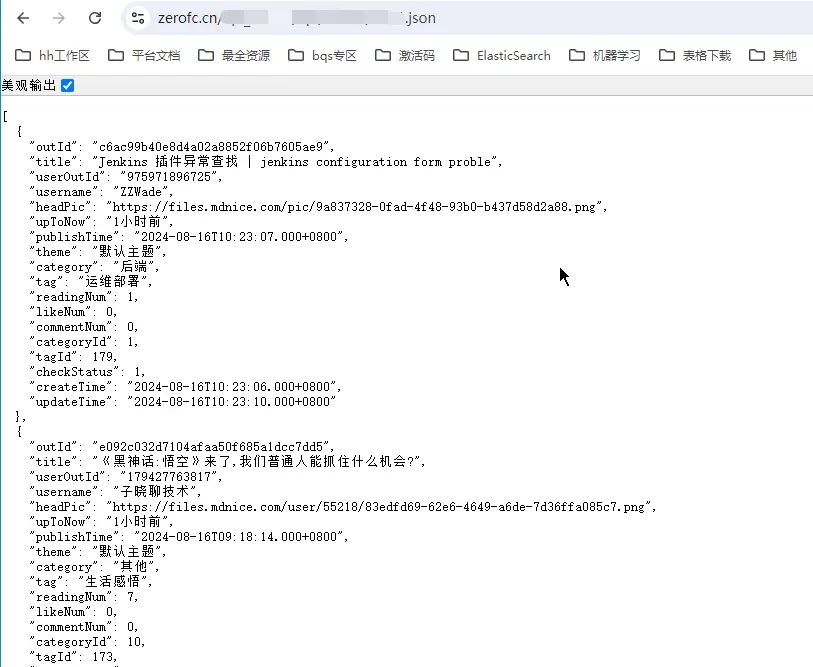
定时爬虫部署
要实现自动化更新数据,那就要定时手动上传和直接爬虫爬取,可以通过 GitHub Actions 工作流的方式实现,下面第一次使用的方式演示如何创建并运行 workflow。
创建推送 TOKEN
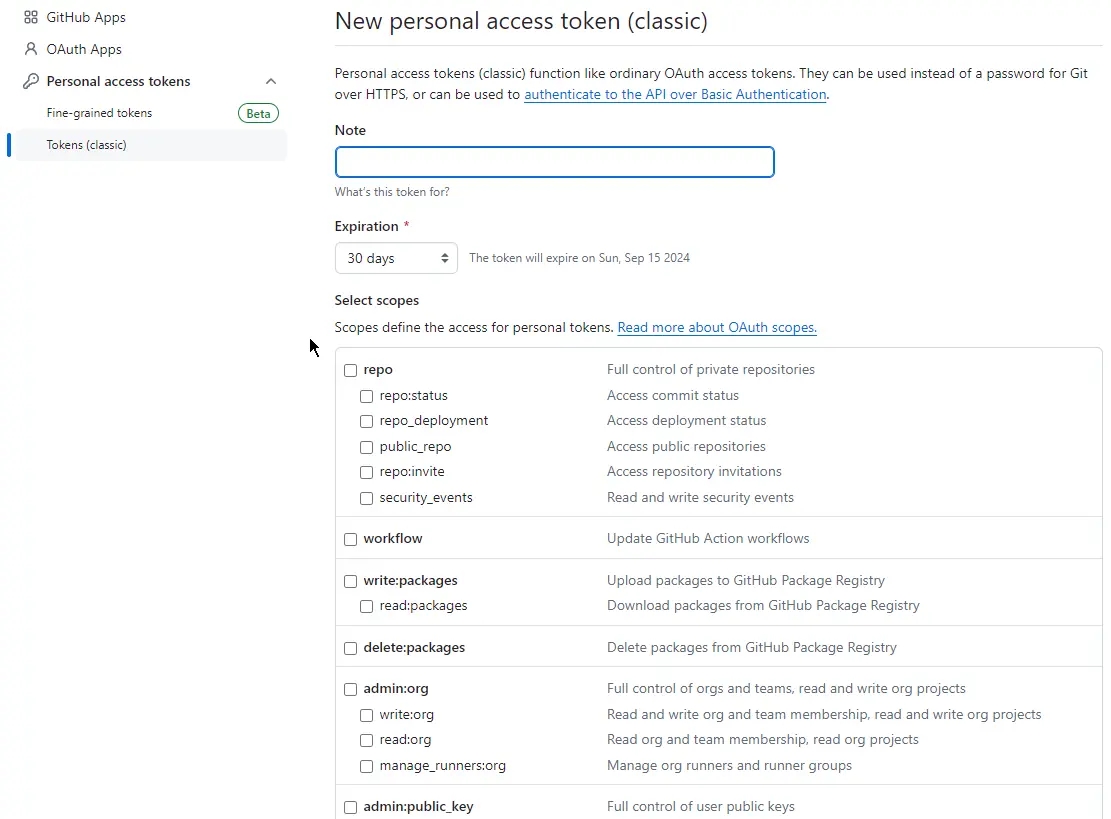
因为生成了 json 文件需要自动推送到仓库,为了不用输入账号密码并使用 PAT,这个和之前 Hexo 搭建时获取的一样。settings->developer settings->github apps->personal access tokens->tokens (classic),然后选择 “Generate new token (classic)”。
TOKEN 权限设置
设置名称,有效时间,勾选权限,主要的把 repo、workflow、user、write:discussion 以及 admin 开头的全勾上,如果不想选都选上也可以。最后创建后就会显示 token 值,记得把那个 ghp 开头的字符串复制下来,不然后面就看不到了。这里再说一下 PAT 下的 Fine-grained tokens 和 Tokens (classic) 的区别,上面比 Tokens (classic) 权限控制更精细,安全性更高,而且无法设置不能失效的 Token。
测试 TOKEN 是否可用
用 git 命令运行,换成自己的 token 和仓库报错了则说明该 TOKEN 无效
git push https://x-access-token:换成你的TOKEN@github.com/z11r00/你的仓库.git HEAD创建工作流
打开仓库后,点击 Actions,然后点击 New workflow,set up a workflow yourself 后提交。git 拉取后会在项目中生成一个.github 文件夹,依次点进去是刚才创建的工作流 yml 文件。
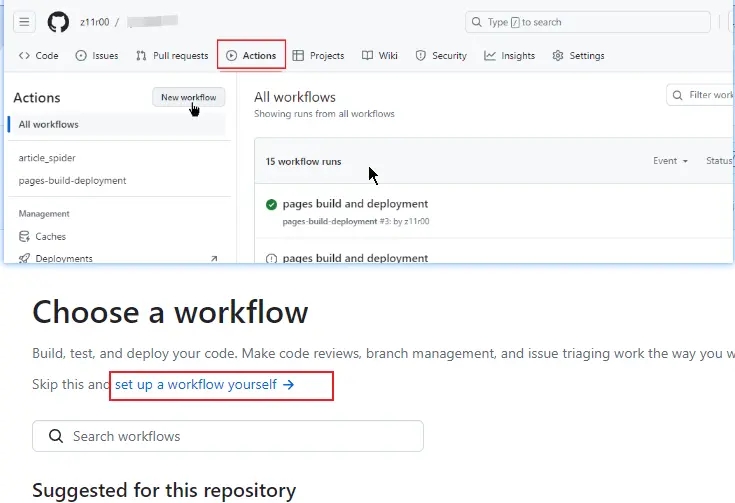
Yml 配置说明
name:工作流名称,展示在用于表示工作流。
on:触发事件,schedule 定时 | push 推送 | pull_request pr 请求,定时任务下有一个 cron 的五个 * 分别是分 时 日 月 星期(, 分割字段多值 - 定义范围 / 指定间隔频率)。
workflow_dispatch: 是否允许在 github actions 操作选项卡中手动操作,默认是可以。
jobs:任务执行的定义。
runs-on: 用于任务执行的运行器,可以说是操作系统,其他的还有 windows 等,具体参考文档,下面会贴出。
steps: 步骤,工作流依次执行的步骤,每个都有一个名字和具体的运行指令,可以使用 actions 包 (github 提供的集成程序,比如用于检出仓库代码的,python 环境的等等)。
爬虫工作流
以下定义一个每天八点十分(不一定准时),先是用 TOKEN 检出仓库中的所有代码,然后设置 python 环境后安装指定依赖,运行 script 目录下的 ArticleSpider.py 脚本,最后将脚本里生成的 json 文件提交并推送到仓库。
# 工作流名称
name: article_spider
# 事件:schedule 定时 | push 推送 | pull_request pr请求
on:
schedule:
# 分 时 日 月 星期 (*每次都 ,分割字段多值 -定义范围 /指定间隔频率)
- cron: '10 0 * * *' # 每日8:10,时间点执行任务,注意时区(UTC, 0+8)
# 是否可在github操作选项卡手动运行
workflow_dispatch:
# 定义任务
jobs:
build:
# 任务运行器(切换可参考文档)
runs-on: ubuntu-latest
# 步骤
steps:
# 使用到的actions包(用于克隆当前仓库的所有代码)
- name: Checkout repository
uses: actions/checkout@v3
with:
ref: main
token: ${{ secrets.PUSH_TOKEN }} # 自定义的个人推送TOKEN
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install requests
pip install lxml
- name: execute py script
env:
FM_USERNAME: ${{ secrets.USERNAME }}
run: |
python script/ArticleSpider.py
- name: 列出所有文件
run: |
ls -l
- name: Commit changes
run: |
git config --local user.email "2652364582@qq.com"
git config --local user.name "bqs"
git add .
git commit -m "Add changes" || echo "No changes to commit"
git push origin main
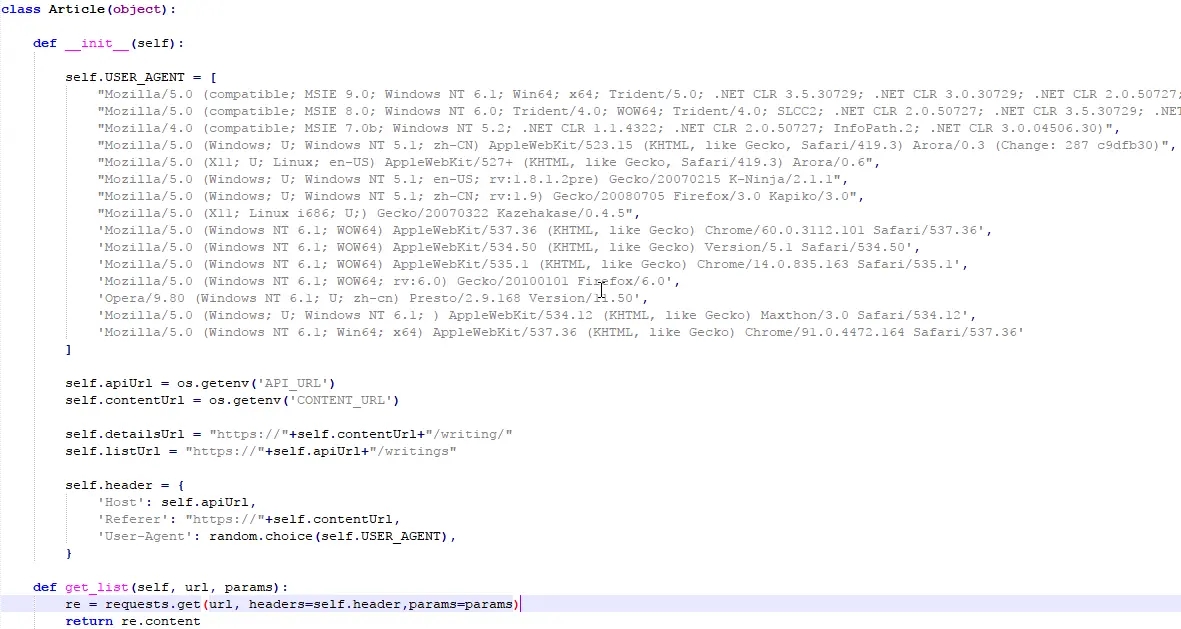
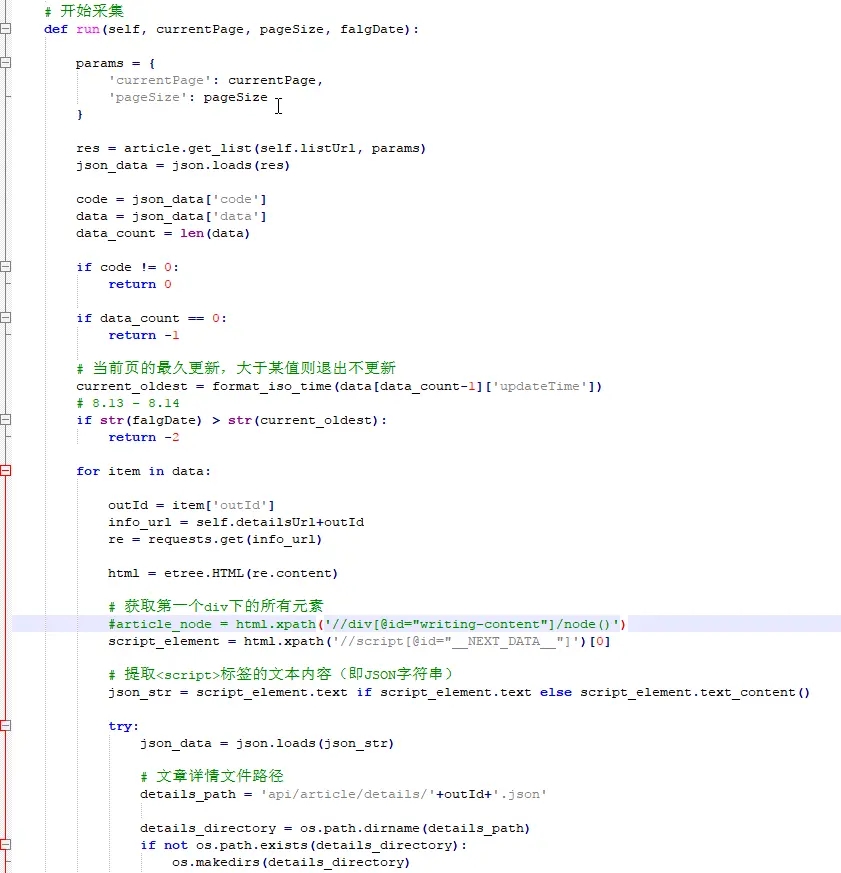
ArticleSpider.py 脚本
因为对方站点是一个前后端分离的项目,页面的列表和详情都是用异步请求的方式。所以这种抓取就比较好办,写一个 while 循环,页码不断累加的请求接口,判断有超过某时间点的文章则跳出循环。在循环中将数据保存到指定的目录下的 json 文件中,当然也可以自己调整数据,如果要分页就按固定条数分文件。

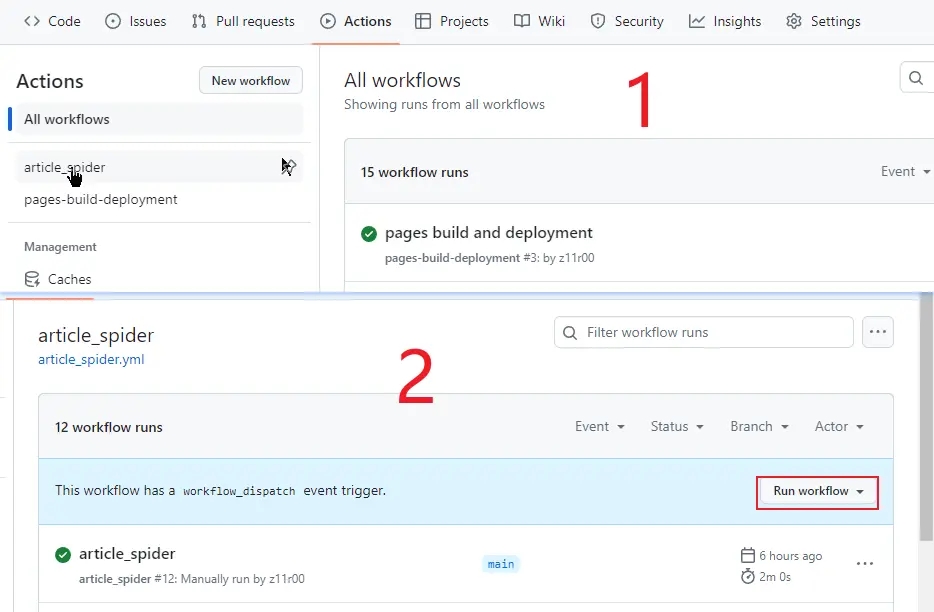
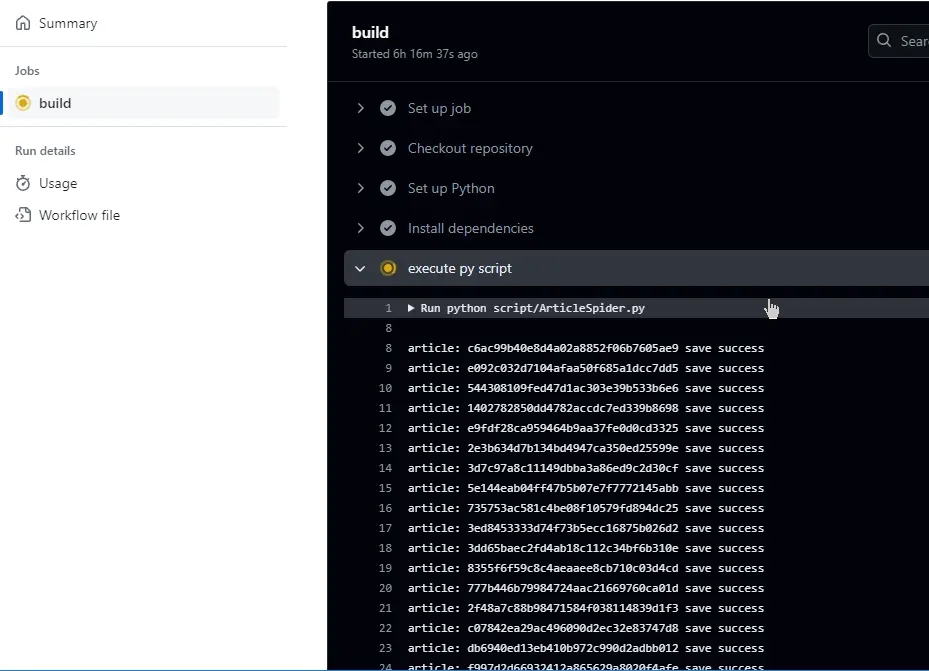
运行效果
虽然是定时的,但也可以去 GitHub 控制台手动运行。打开 Actions,选择工作流名字进去,最后 Run workflow 就等待执行了。详细也可以看到脚本里打印出的日志,执行完毕再回到仓库查看是否有 json 文件生成。
写在后面
以上只是演示,如果真要弄自己的 API 还是得对爬取的数据做一下处理,拓展一下是不是还可以用这种方式,实现一个带后台管理的资源 “动态网站”。但是应用也不光只有展示,还有提交部分,所以要想零成本实现将用户数据存储下来就要用到另一些方法了,最后 GitHub Actions 用法也远不止于此……


 浙公网安备 33010602011771号
浙公网安备 33010602011771号