如何用 Python 实现一个 “系统声音” 的实时律动挂件
2024-01-08 11:27 北桥苏 阅读(589) 评论(0) 收藏 举报前言
应该是三年前,我用 Esp8266 和 ws2812 实现了一个音乐律动灯带。就是电脑播放音乐时,灯带会随着系统内部音乐播放的频率而闪动不同色彩的灯珠。而当时用来监听系统声音的工具是一个博主提供的,除了实时采集声音外还通过 UDP 传递数据到 Esp8266 上。
而这次,我就自己用 Python 实现一下,不过不传数据,就采集后直接实时地在电脑上绘制波形动画,主要是用来作为 FL Studio 播放时的一个桌面小挂件。

环境
python3.8
pyaudio0.2.14
matplotlib

pyaudio 简介
pyaudio 是一个跨平台地音频 I/O 库,使用他可以在 Python 程序中进行播放,录音和生成 wav 文件等。需要注意的是,如果要使用 pyaudio 时,python 的版本最好在 3.7 以上,不然 pip 安装会报错。因为以下例子是获取系统内部声音,而 pyaudio 读取的音频流默认是麦克风,所以接下来介绍一下关于获取的设备列表信息。
代码获取设备列表
# pyaudio实例 audio = pyaudio.PyAudio() # 获取设备总数 device_count = audio.get_device_count() # 根据设备索引获取设备详细信息 for i in range(p.get_device_count()): devInfo = p.get_device_info_by_index(i) print(devInfo)

设备信息参数介绍
- index: 设备的索引号,通常用于标识系统中的设备顺序。
- structVersion: 结构版本号,用于表示这个数据结构的版本。
- name: 设备的名称,这里是 “Microsoft 声音映射器 - Input”。
- hostApi: 主 API 的标识符,通常用于表示该设备属于哪个 API 或系统。
- maxInputChannels: 设备支持的最大输入通道数,这里是 2,表示设备支持 2 个输入通道。
- maxOutputChannels: 设备支持的最大输出通道数,这里为 0,表示该设备没有输出通道。
- defaultLowInputLatency: 默认的低输入延迟,以秒为单位,这里是 0.09 秒。
- defaultLowOutputLatency: 默认的低输出延迟,这里是 0.09 秒。
- defaultHighInputLatency: 默认的高输入延迟,这里是 0.18 秒。
- defaultHighOutputLatency: 默认的高输出延迟,这里是 0.18 秒。
- defaultSampleRate: 默认的采样率,这里是 44100.0 赫兹,这是 CD 质量的音频标准采样率。

开始操作
开启立体声混音权限
打开电脑设置 - 系统 - 声音 - 管理声音设备 - 立体声混响,点击启用。
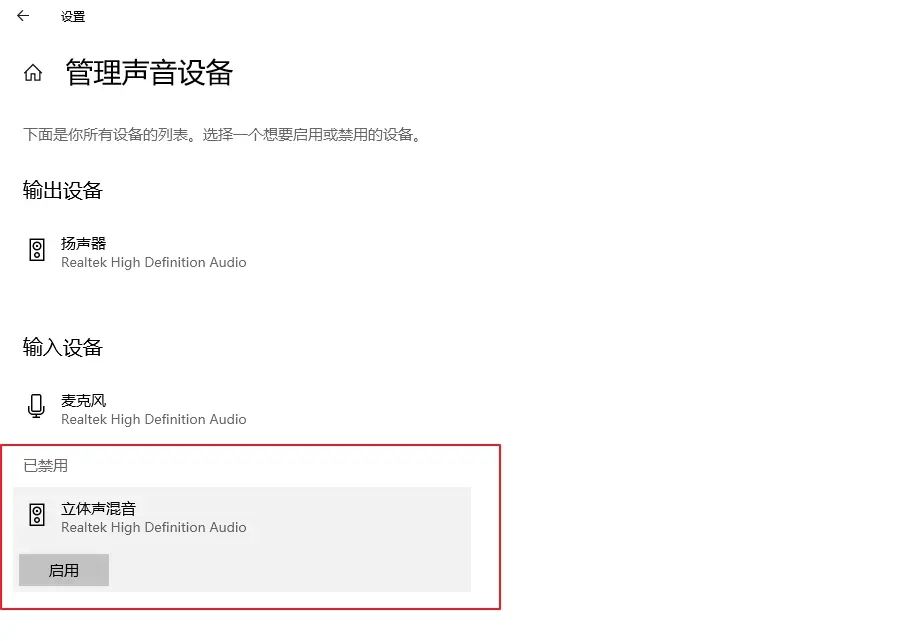
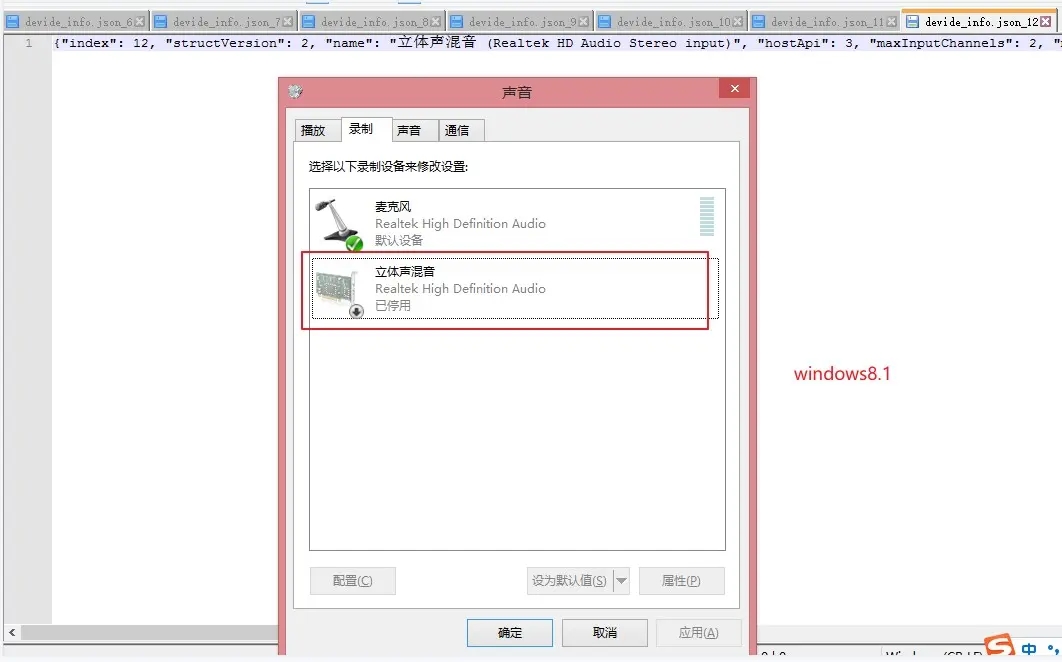
设置设备索引号
打开立体声混音后,通过 pyaudio 获取设备列表,找到带有 “立体声混音” 的名称,和 hostApi 为 0 的,hostAPI = 0 表明是 MME 设备。然后拿到该设备索引号,打开音频流时指定该内录设备序号。
def findInternalRecordingDevice(p):
# 要找查的设备名称中的关键字
target = '立体声混音'
# 逐一查找声音设备
for i in range(p.get_device_count()):
devInfo = p.get_device_info_by_index(i)
print(devInfo)
if devInfo['name'].find(target) >= 0 and devInfo['hostApi'] == 0:
# print('已找到内录设备,序号是 ',i)
return i
print('无法找到内录设备!')
return -1
全部代码
import pyaudio
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import wave
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 4096
# CHUNK = 1024
WAVE_OUTPUT_FILENAME = 'audio_output.wav'
# 获取内录设备序号,在windows操作系统上测试通过,hostAPI = 0 表明是MME设备
def findInternalRecordingDevice(p):
# 要找查的设备名称中的关键字
target = '立体声混音'
# 逐一查找声音设备
for i in range(p.get_device_count()):
devInfo = p.get_device_info_by_index(i)
print(devInfo)
if devInfo['name'].find(target) >= 0 and devInfo['hostApi'] == 0:
# print('已找到内录设备,序号是 ',i)
return i
print('无法找到内录设备!')
return -1
# Initialize PyAudio
audio = pyaudio.PyAudio()
# 这里input_device_index的2就是系统内录设备索引
stream = audio.open(input_device_index=2,
format=FORMAT,
channels=1,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
plt.ion()
fig, ax = plt.subplots()
x = np.arange(0, CHUNK)
line, = ax.plot(x, np.zeros(CHUNK))
ax.set_xlim(0, CHUNK)
ax.set_ylim(-32768, 32767)
wave_output_file = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wave_output_file.setnchannels(CHANNELS)
wave_output_file.setsampwidth(audio.get_sample_size(FORMAT))
wave_output_file.setframerate(RATE)
def update_plot(data):
print(data)
line.set_ydata(data)
fig.canvas.draw()
fig.canvas.flush_events()
def display_audio_waveform():
while True:
try:
audio_data = np.frombuffer(stream.read(CHUNK), dtype=np.int16)
# update_plot(audio_data*500)
update_plot(audio_data)
# wave_output_file.writeframes(audio_data)
except KeyboardInterrupt:
break
display_audio_waveform()
stream.stop_stream()
stream.close()
audio.terminate()
wave_output_file.close()
print('Audio saved to', WAVE_OUTPUT_FILENAME)

个人网站:www.zerofc.cn
公众号:ZEROFC_DEV
QQ交流群:515937120
QQ:2652364582
头条号:1637769351151619
B站:286666708
大鱼号:北桥苏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号