

SQL语句调优 - 统计信息的含义与作用及维护计算
统计信息的含义与作用
对于同一句话,SQL SERVER 有很多种方法来完成它。有些方法适合于数据量比较小的时候,有些方法适合于数据量比较大的时候。同一种方法,在数据量不同的时候,复杂度会有非常大的差别。索引只能帮助SQL SERVER找到符合条件的记录。SQL SERVRE 还需要知道每一种操作所要处理的数据量有多少,从而估算出复杂度,选取一个代价最小的执行计划。说得通俗一点,SQL SERVR要能够知道数据是“长得什么样”的,才能用最快的方法完成指令。怎么能够让SQL SERVER知道数据的分布信息呢?在数据库管理系统里有个常用的技术,就是数据的“统计信息”(STATISTICS)。SQL SERVER 是通过它了解数据的分布情况的。
我们可以看一下上次2张表在SalesOrderID这个字段上的统计信息,以便对于直观认识。
先手动更新一下:SalesOrderHeader_TEST 这个表的统计信息,在统计信息的维护上面说明为什么这里要手机更新:
UPDATE STATISTICS dbo.SalesOrderHeader_TEST GO -- 再运用脚本: DBCC SHOW_STATISTICS(SalesOrderHeader_TEST , SalesOrderHeader_TEST_CL) GO
结果如下图:
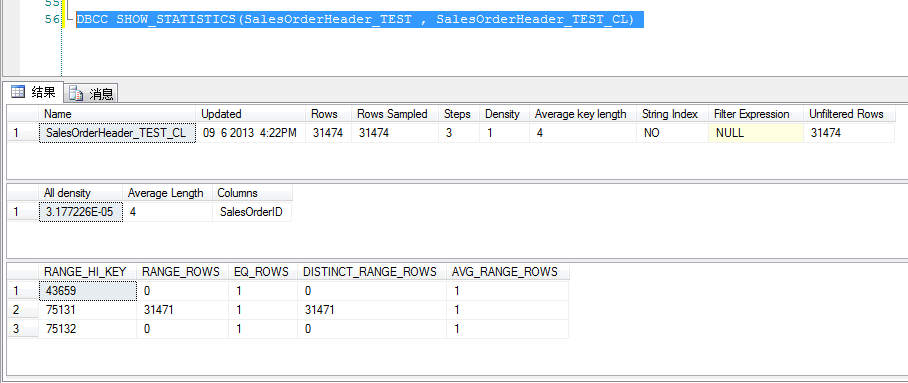
保存的是每个订单的概要信息,一张订单只会有一条记录,所以SalesOrderID是不会重复的。现在这张表里,应该有31474 条记录,SalesOrderID是一个int型的字段,所以字段长度是4。运用DBCC SHOW_STATISTICS(<table_name> , <index_name>) 命令可以得到统计信息内容。
统计信息内容分3部分
- 统计信息头信息
|
列名 |
说明 |
|
|
Name |
统计信息名称。这里就是索引的名字: SalesOrderHeader_test_CL |
|
|
Updated |
上一次更新统计信息的日期和时间。这里是09 6 2013 4:22PM这个时间非常重要,根据它能够判断统计信息是什么时候更新的,是不是数据量发生变化以后,是不是存在统计信息不能反映当前数据分布特点的问题。 |
|
|
Rows |
表中的行数。这里是31474行,完全正确反映了当前表的数据量 |
|
|
Rows Sampled |
统计信息的抽样行数。这里也是31474,说明上次SQL SERVER更新统计信息的时候,对整个表里所有记录的SalesOrderID字段,都扫了一遍,这样做出来的统计信息一般都都是很精确的。 |
|
|
Steps |
在统计信息的第3部分,会把数据分成几组。这里是3组 |
|
|
Density |
第一个列前缀的选择性(不包括 EQ_ROWS) |
|
|
Average key length |
如果列的平均长度,因为SalesOrderHeader_test_cl索引只有一列,数据类型是int ,所以长度就是4 |
|
|
String Index |
如果为“是”,则统计信息中包含字符串摘要索引,以支持为like条件估算结果算大小、nvarchar(max)、text 以及 ntext 数据类型的关导列,这里是int ,所以这个是为”no” |
|
2. 数据字段的选择性
|
列名 |
说明 |
|
|
All density |
反映索引列的选择性(select ivity)“选择性”反映数据集里重复的数据量多少,或者反过来说,值唯一的数据量有多少,如果一个字段的灵气很少有重复,那么它的可选择性就比较高。比如身份证号,是不可重复的。哪怕对整个中国的身份记录做调查,代入一个身份证号码,最多只会有一条记录返回。在这样字段上的过滤条件,能够有效地过滤掉大量数据,返回的结果集会比较小。举一个相反的例子,性别。非男即女,这个字段上的重复性就很高,选择性就很低,一个过滤条件,最多只能过滤掉一半的记录。 SQL SERVER通过计算“选择性”,使得自己能够预测一个过滤条件做完后,大概能有多少记录返回。 Density的定义是:desity = 1/Cardinality of index keys 如果这个值小于0.1,一般讲这个索引的选择性比较高。如果大于0.1,它的选择就不高了。
|
|
|
Average length |
索引列的平均长度,这里还是4 |
|
|
Columns |
索引列的名称, 这里是字段 SalesOrderID |
|
从这一部分的信息,可以推断出统计所关心的字段的长度,以及它有多少条唯一值。但是这些信息对SQL SERVER预测结果集复杂度还不够。比如我现在要查一个SalesOrderID = 60000的订单,还是不知道会有多少记录返回。这里需要第3部分信息
3. 直方图(histogram)
|
列名 |
说明 |
|
|
Range_hi_key |
直方图里第一组(step)数据的最大值。订单号的最小号码在表里是43659。这里是sql server选择它作为第一个step的最大值。3组数据分别是:.. ~~43659 , 43660 ~~75131 ,75132~~75132 |
|
|
Range_rows |
每组数据区间行数据,上限值除外。第一组只有一个数:43659,第三组也只有一个数: 75132. 其它数据都在第二个组里,区别里有31471个数。 |
|
|
Eq_Rows |
表中与直方图每组数据上限值相等的行数目。 这里都是1 |
|
|
District_range_rows |
走方图里每组数据区间非重复值的数目,上限值除外。由于这个字段没有重复的值,所以这里distinct_reange_rows的值就等于range_rows的值 |
|
|
Avg_range_rows |
直方图里每组数据区间内重复值的平均数目,上限值除外。 计算公式 = (Range_rows/district_range_Rows for distinct_range_rows>0)这里district_range_Rows的值就等于 Range_rows的值,所以avg_range_rows = 1 |
|
有这么一个直方图,就能够很好地知道表格里的数据分布了。在SalesOrderID这个字段里,最小值是43659,最大75132,在这个区间里有31473个值,且没有重复值,所以要吧推算出表格里的值就是从43658 到 75132结束的每个int值、 SQ L SERVER 没有必要存储很多step的信息,只要这3个step,就能够完全表达数据分布。假设查询条件是在43659 – 75132之间的值,那么SQL SERVER知道会返回一行。如果不在这个区别,就不会有行返回。而返回的每一行长度,都是4. 通过这些统计信息,SQL SERVER能够比较好地预测返回的结果集的行数和长度。
注:1. 如果一个统计信息是为一组字段建立的,例如,一个复合索引建立在两个以上的字段上,SQL SERVER维护所有字段的选择性信息,但是只会维护第一个字段的直方图。
2. 当表格比较大的时候,SQL SERVER 在更新统计信息的时候为了降低消耗,只会取表格的一部分数据做抽样(Rows Sampled),这时候统计信息里面的数据都是根据这些抽样数据估算出来的值,可能和真实值会有些差异。
统计信息越细,就越准确,但是维护统计信息要付出的额外开销也会很大,有可能提高统计信息精确度所带来的执行性能的提升,还抵不了维护统计信息成本的增加。SQL SERVER做这样的设计,不是因为其能力有限,而是为了谋求一个对大多数情况都合适的平衡。
刚才看的索引 SalesOrderHeader_test_CL数据分布比较简单。下面来说一个稍微复杂一点的索引。SalesOrderDetail_TEST_NCL
SalesOrderDetail_TEST这张表造数据的时候,做的比较特别,它的前10%的数据,属于编号43659 – 75132这3万多条订单,而后90%的数据,平均属于43659 – 75132这9张订单。来看一下统计信息是如何表示的。
DBCC SHOW_STATISTICS(SalesOrderDetail_test, SalesOrderDetail_TEST_NCL)

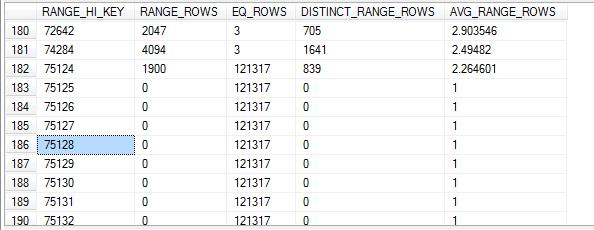
这个统计信息和SalesOrderHeader_test_CL有很多不同
1、 这里的数据分组(step)/有190个,要详细很多。
2、 在第2部分Density,不但有索引列(SalessOrderID)的选择值,还有SalesOrderID + SalesOrderDetailID 合并起来的选择值。可以看出如果同时使用2个字段进行过滤,其选择性8.242868E-07 会比只使用 SalesOrderID (3.177226E-05) 还要高
3、 走廊图只有SalesOrderID的信息,没有 SalesOrderDetailID 的信息。从直方图的各项值分布情况,可以清楚地看出 SalesOrderHeader_test 这张表的数据分布特点。SQL SERVER能够根据供稿的 SalesOrderID值,推断出是只有几条、几十条记录返回(当SalesOrderID 在43659到75123之间),还是会有12万条数据返回(当SalesOrderID 在75124到75132之间)。
下面两段代码虽然结构一模一样,但是因为参数值不同,SQL SERVER选择了不同的执行计划,下图,这是因为SQL SERVER知道一个只会返回3行(EstimateRows), 而后一个会返回 121317行,这里SQL SERVER 猜得是完全正确的。
SET STATISTICS PROFILE ON SELECT B.SalesOrderID , B.OrderDate , A.* FROM dbo.SalesOrderDetail_TEST A INNER JOIN dbo.SalesOrderHeader_TEST B ON A.SalesOrderID = B.SalesOrderID WHERE B.SalesOrderID = 72642 SET STATISTICS PROFILE OFF

SET STATISTICS PROFILE ON SELECT B.SalesOrderID , B.OrderDate , A.* FROM dbo.SalesOrderDetail_TEST A INNER JOIN dbo.SalesOrderHeader_TEST B ON A.SalesOrderID = B.SalesOrderID WHERE B.SalesOrderID = 75127 SET STATISTICS PROFILE OFF

统计信息的维护与计算
在SQL SERVER数据库属性里,有两个默认打开的设置AUTO_CREATE_STATISTICS 和 AUTO_UPDATE_STATISTICS 他们能够让SQL SERVER在需要的时候,自动建立要用到的统计信息,也能在发现统计信息过时的时候,自动去更新它。 什么时候会创建统计信息呢?主要有3种情况:
1、 在索引创建时,SQL SERVER会自动地在索引所在列上创建统计信息。
所以从某种角度讲,索引的作用是双重的。它自己能够帮助SQL SERVRE快速找到数据。而它上面的统计信息,也能够告诉SQL SERVER 数据的分布情况
2、 管理员也可以通过 CREATE STATISTICS 之类的语句手动创建他认为需要的统计信息
如果打开 AUTO_CREATE_STATISTICS,一般来讲很少需要手动创建。
3、 当SQL SERVER想要使用某些列上的统计信息,发现没有的时候, "auto create statistics" 会让 sql server自动创建统计信息
例如: 当语句要在某个(或者某几个)字段上做过滤,或者要拿它(们)和另外一张表联接(JOIN), SQL SERVER 要估算最后从这个表会返回多少条记录。这个时间就需要一个统计信息的支持。如果没有,SQL SERVER会自动创建一个。
USE AdventureWorks2008 GO -- 返回指定表中列和索引的统计信息。(索引上的除外) sp_helpstats @objname = 'dbo.SalesOrderHeader_TEST' go -- 结果显示:此对象没有任何统计信息。 SELECT COUNT(*) FROM dbo.SalesOrderHeader_TEST where OrderDate = '2004-06-11 00:00:00.000' go sp_helpstats @objname = 'dbo.SalesOrderHeader_TEST' go -- 显示结果 /* statistics_name statistics_keys _WA_Sys_00000003_7F80E8EA OrderDate */
由上面的例子可以看出,在打开 AUTO_CREATE_STATISTICS 的数据库上,不用担心 SQL SERVER没有足够的统计信息来选择执行计划。
SQL SERVER不仅要建立合适的统计信息,还要及时更新它们,使他们能够反映表里数据的变化。数据的插入、删除、修改都可能会引起统计信息的更新。但是,更新统计信息本身是一件消耗资源的事情,尤其是对比较大的表。如果有一点点小的修改SQL SERVER都要去更新统计信息,可能 SQL SERVER就光忙活这个,来不及做其它事了。 SQL SERVER 还是要在统计信息的准确度和资源合理消耗之间做一个平衡。在SQL SERVER 2005/08,触发统计信息自动更新的条件是:
1、如果统计信息是定义在变通表格上的,那么当发生下面变化之一后,统计信息就被认为是过时的,下次使用时,会自动触发一个更新动作。
(1)表格从没有数据变成有大于等于1条数据
(2)对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化大于500以后。
(3)对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化量大于500 + (20%)
2、临时表(temp table) 上可以有统计信息。其维护策略基本和普通表格一致。但是表变量(table variable) 上不能建统计信息。
这样的维护策略能够保证花费比较小的代价,确保统计信息基本正确。后面会有安例,反映这个维护策略在数据分布特殊的表上,也有可能造成一些负面的影响。
在SQL SERVER2005以后,数据库属性多了一个‘Auto Update Statistics Asynchronously’。当SQL SERVER发现某个统计信息过时时,它会用老的统计信息继续现在的查询编译,但是会在后台启动一个任何,更新这个统计信息。这样下一次统计信息被使用时,就已经是一个更新过的版本。这样做的缺点,是不能保证当前这句查询的执行计划准确性。凡事有利有弊,数据库管理员可以根据实际情况做选择。 当然,的确有一些例外情况。由于数据特殊性,会使得 SQL SERVER 这种 auto update statistics 的算法不能满足确保执行计划确实性的需求。在实际使用中,有时候数据库的性能会突然之间慢下来。有经验的管理员会安排一次索引重建的任务,常常对性能会有所帮助。通常人们会解释为,因为索引重建消除了数据碎片,因而提高了性能。其实索引重建还做了另外一件很重要的工作,它使用full scan 的方式,重新更新了表上的统计信息,使得统计信息非常精确。这对性能帮助作用也会很大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号