
BUAA_OO_第一单元作业总结
第一单元作业总结
BUAA OO 2021面向对象作业
一、分析架构
(一)第一次作业
1.方法分析
第一次作业我的代码分成了三部分:表达式输入、表达式求导和表达式输出。
在表达式输入部分,我采用了大正则表达式的方式进行了匹配处理。根据指导书上给的每一部分的形式化定义,递归生成每一部分要匹配的正则表达式,之后使用java中的matcher和pattern类进行匹配。
在表达式求导部分,我首先对表达式进行了合并同类型,因为只含有\(x^i\),因此可以使用一个容器Map将幂函数插入进来。求导时我是使用迭代器遍历所有Key值,直接对多项式进行求导,把求导后的二元组\((Coe,Deg)\)存储到ArrayList。
在表达式输出部分,我对ArrayList按照\(Coe\)为第一关键字从大到小,\(Deg\)为第二关键字从大到小排列。这样可以保证正项能尽可能靠前,最终输出少一个正号。之后分别实现了每一项输出的toString()函数和表达式输出的toString()函数。
2.度量分析
| Method | CogC | CONTROL | ev(G) | iv(G) | LOC | v(G) |
| BlankCharacter.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| BlankItem.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| ConstantFactor.ConstantFactor() | 0 | 0 | 1 | 1 | 2 | 1 |
| ConstantFactor.ConstantFactor(String) | 0 | 0 | 1 | 1 | 5 | 1 |
| ConstantFactor.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| Exponent.Exponent() | 0 | 0 | 1 | 1 | 2 | 1 |
| Exponent.Exponent(String) | 0 | 0 | 1 | 1 | 6 | 1 |
| Exponent.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| Expression.Expression() | 0 | 0 | 1 | 1 | 2 | 1 |
| Expression.Expression(String) | 6 | 3 | 1 | 5 | 22 | 5 |
| Expression.derive() | 4 | 2 | 1 | 4 | 14 | 4 |
| Expression.insert(Item) | 2 | 1 | 1 | 2 | 10 | 2 |
| Expression.toString() | 12 | 6 | 3 | 6 | 38 | 7 |
| Factor.Factor() | 0 | 0 | 1 | 1 | 2 | 1 |
| Factor.Factor(String) | 2 | 1 | 1 | 2 | 15 | 2 |
| Factor.getCoefficient() | 0 | 0 | 1 | 1 | 3 | 1 |
| Factor.getDegree() | 0 | 0 | 1 | 1 | 3 | 1 |
| Factor.getregex() | 0 | 0 | 1 | 1 | 4 | 1 |
| Factor.setCoefficient(BigInteger) | 0 | 0 | 1 | 1 | 3 | 1 |
| Factor.setDegree(BigInteger) | 0 | 0 | 1 | 1 | 3 | 1 |
| HasZeroInteger.HasZeroInteger() | 0 | 0 | 1 | 1 | 2 | 1 |
| HasZeroInteger.HasZeroInteger(String) | 0 | 0 | 1 | 1 | 3 | 1 |
| HasZeroInteger.getInteger() | 0 | 0 | 1 | 1 | 3 | 1 |
| HasZeroInteger.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| HasZeroInteger.setInteger(BigInteger) | 0 | 0 | 1 | 1 | 3 | 1 |
| Item.Item() | 0 | 0 | 1 | 1 | 2 | 1 |
| Item.Item(BigInteger,BigInteger) | 0 | 0 | 1 | 1 | 4 | 1 |
| Item.Item(String) | 4 | 2 | 1 | 4 | 20 | 4 |
| Item.getregex() | 0 | 0 | 1 | 1 | 6 | 1 |
| Item.toString() | 12 | 7 | 8 | 12 | 30 | 12 |
| Mainclass.main(String[]) | 0 | 0 | 1 | 1 | 6 | 1 |
| PowerFunction.PowerFunction() | 0 | 0 | 1 | 1 | 2 | 1 |
| PowerFunction.PowerFunction(String) | 2 | 1 | 1 | 2 | 12 | 2 |
| PowerFunction.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| SignHasZeroInteger.SignHasZeroInteger() | 0 | 0 | 1 | 1 | 2 | 1 |
| SignHasZeroInteger.SignHasZeroInteger(String) | 2 | 1 | 1 | 3 | 8 | 3 |
| SignHasZeroInteger.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| Signal.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| VariableFactor.VariableFactor() | 0 | 0 | 1 | 1 | 2 | 1 |
| VariableFactor.VariableFactor(String) | 0 | 0 | 1 | 1 | 5 | 1 |
| VariableFactor.getregex() | 0 | 0 | 1 | 1 | 3 | 1 |
| Class | LOC | NAAC | NOAC | OCavg | OCmax | WMC |
| BlankCharacter | 5 | 0 | 1 | 1 | 1 | 1 |
| BlankItem | 5 | 0 | 1 | 1 | 1 | 1 |
| ConstantFactor | 12 | 0 | 1 | 1 | 1 | 3 |
| Exponent | 13 | 0 | 1 | 1 | 1 | 3 |
| Expression | 91 | 2 | 2 | 3.4 | 7 | 17 |
| Factor | 37 | 2 | 5 | 1.14 | 2 | 8 |
| HasZeroInteger | 17 | 1 | 3 | 1 | 1 | 5 |
| Item | 64 | 0 | 1 | 2.8 | 8 | 14 |
| Mainclass | 8 | 0 | 1 | 1 | 1 | 1 |
| PowerFunction | 19 | 0 | 1 | 1.33 | 2 | 4 |
| SignHasZeroInteger | 15 | 0 | 1 | 1.67 | 3 | 5 |
| Signal | 5 | 0 | 1 | 1 | 1 | 1 |
| VariableFactor | 12 | 0 | 1 | 1 | 1 | 3 |
| Package | LOC | v(G)avg | v(G)tot | |||
| 328 | 1.78 | 73 | ||||
| Module | LOC | v(G)avg | v(G)tot | |||
| HW1 | 330 | 1.78 | 73 | |||
| Project | LOC | v(G)avg | v(G)tot | |||
| project | 330 | 1.78 | 73 |
度量分析发现Item.toString()函数圈复杂度比较高,这是因为该函数是仿照实验课时所使用的大量的if语句。
总代码行数330行,还算可以接受的范围。
3.类图分析

第一次作业中不同的类主要是去根据识别输入串的不同结构,形成了两个继承结构:PowerFunction、Item、ConstantFactor、VariableFactor继承Factor类,SignHasZeroInteger和Exponent继承HasZeroInteger。这两者继承的主要是数据继承。
下面从各给类的角度给出设计思路:
BlankItem
仅仅包含空白项的正则表达式。
BlankCharacter
仅仅包含空白字符的正则表达式。
Signal
仅仅包含符号项的正则表达式。
Factor
因子类,用\(Coe\)存储系数,\(Deg\)存储度数,是第一次作业中最基本数据单元。该类支持转换成字符串输出,获得类中的属性和修改类的属性。
PowerFunction
幂函数类,满足\(Coe=1\),用来识别输入字符串中的幂函数。
VariableFactor
变量因子类,在本次作业中只包含了幂函数,因此相当于对幂函数的一个抽象。
ConstantFactor
常数因子类,满足\(Deg=0\),用来识别输入字符串中的常数部分。
SignHasZeroInteger
含有符号的允许有前导零的整数类,识别满足有符号前导零的整数。
HasZeroInteger
含有前导零的整数类,识别不能含有符号的整数类。
Exponent
指数类,识别指数部分。
Item
项类,因为第一单元中只有多项式因子,因此可以把多个因子合成一个因子来存储(相当于系数相乘,度数相加),项类提供了输出成字符串。
Expression
表达式类,这个部分既负责了表达式的输入识别,又负责了表达式的化简和输出。通过使用\(Map<Deg,Coe>\)来进行不同项类的合并,同时通过实现derive()函数来对表达式进行求导,最后再通过一个ArrayList把Map中所有项导出,使用sort函数使系数大的在前、系数小的在后来进行的优化表达式的输出,最后再调用每一个Item的输出并凑成整个表达式的输出。
Mainclass
整个项目的入口,统领整个项目,内容很简单。
下面进行简单的优缺点分析:
优点
- 整个项目严格按照指导书上的形式化定义产生的类,清晰明了。
- 思路简单直接。
缺点
- 形如BlankItem,BlankCharater,Signal等仅仅提供一个正则表达式的类不应该单独开类,可以把这些正则表达式的接口通过一个大类进行统一管理。
- 使用大正则表达式会带来严重的问题,有可能会导致递归爆栈(虽然匹配很快)。
- 整个项目的耦合度还是太高,比如Expression类里面的功能太多了,应该将不同的功能分散到不同的类。
- 表达式的输出优化做的不够全面,形如\(x*x\)的优化没有做到。
(二)第二次作业
1.方法分析
第二次作业在第一次作业的基础上增加了\(sin(x)\)和\(cos(x)\),还增加了可以嵌套的表达式因子。
在吸取了上一次作业的经验教训后,我放弃了使用正则表达式,转换成了递归下降的策略。
第二次作业我的代码分成了四部分:表达式输入、表达式存储、表达式求导和表达式输出。
在表达式输入部分,我采用递归下降的思路进行了匹配处理。通过文法分析将指导书上给的每一部分的形式化定义转换成右递归,之后通过Decoder类分别实现识别每一个部分的函数,将输入的表达式转换成表达式树。
在表达式存储部分,我采用了表达式树进行了统一管理。
在表达式求导部分,我通过在表达式树上建立了转换方法,把一颗表达式树转换成了Map(三元组:\(x^i sin(x)^j cos(x)^k\))并使用这个Map进行了系数合并。求导时我是使用迭代器遍历所有Key值,直接对多项式进行求导,把求导后的结果用一个新的Map来继续存储。
在表达式输出部分,我做了一个小的贪心。由于我的方法相当于对整个表达式进行了拆括号处理,可以发现有很多项其实是可以合并的,因此我就尝试做一个二元的贪心,我遍历表达式的每一个项,尝试把这个项和另一个其他项进行合并输出(提取公因式),如果发现输出后结果变的更好我就贪心取让长度变得最短的那一个,并把这两项从Map中删除。这样大概可以使表达式长度减小到原来的\(\frac{2}{3}\),因此这次作业的性能分也比较好。
第二次作业我为之后的判WrongFormat做了准备,提前把WrongFormat判好了。
2.度量分析
| Method | CogC | CONTROL | ev(G) | iv(G) | LOC | v(G) |
| Add.diff() | 0 | 0 | 1 | 1 | 7 | 1 |
| Add.simply() | 2 | 2 | 1 | 3 | 18 | 3 |
| Add.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Constant.Constant(BigInteger,BigInteger) | 0 | 0 | 1 | 1 | 4 | 1 |
| Constant.Constant(String,String) | 0 | 0 | 1 | 1 | 4 | 1 |
| Constant.diff() | 0 | 0 | 1 | 1 | 4 | 1 |
| Constant.simply() | 0 | 0 | 1 | 1 | 5 | 1 |
| Constant.toString() | 14 | 9 | 10 | 14 | 37 | 14 |
| CosFunction.diff() | 0 | 0 | 1 | 1 | 5 | 1 |
| CosFunction.simply() | 0 | 0 | 1 | 1 | 6 | 1 |
| CosFunction.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Decoder.matchAddMinus(String) | 7 | 2 | 3 | 4 | 17 | 5 |
| Decoder.matchBlank(String) | 3 | 1 | 1 | 3 | 8 | 4 |
| Decoder.matchConstantFactor(String) | 0 | 0 | 1 | 1 | 3 | 1 |
| Decoder.matchCosFuntion(String) | 2 | 1 | 2 | 2 | 16 | 2 |
| Decoder.matchExponent(String) | 1 | 1 | 2 | 1 | 9 | 2 |
| Decoder.matchExpression(String) | 5 | 3 | 4 | 2 | 27 | 4 |
| Decoder.matchExpressionFactor(String) | 10 | 8 | 8 | 3 | 27 | 8 |
| Decoder.matchFactor(String) | 3 | 3 | 4 | 1 | 15 | 4 |
| Decoder.matchInteger(String) | 2 | 1 | 2 | 2 | 9 | 2 |
| Decoder.matchItem(String,boolean) | 8 | 4 | 4 | 4 | 31 | 6 |
| Decoder.matchPowerFunction(String) | 2 | 1 | 2 | 2 | 13 | 2 |
| Decoder.matchSignInteger(String) | 2 | 1 | 2 | 2 | 11 | 2 |
| Decoder.matchSinFuntion(String) | 2 | 1 | 2 | 2 | 16 | 2 |
| Decoder.matchTriFunction(String) | 2 | 2 | 3 | 1 | 11 | 3 |
| Decoder.matchVariableFactor(String) | 2 | 2 | 3 | 1 | 11 | 3 |
| FunctionPrint.basic(ArrayList |
6 | 3 | 2 | 4 | 20 | 5 |
| FunctionPrint.coetoString(BigInteger) | 3 | 2 | 1 | 3 | 14 | 3 |
| FunctionPrint.costoString(BigInteger) | 7 | 3 | 1 | 3 | 18 | 4 |
| FunctionPrint.degtoString(BigInteger) | 8 | 4 | 1 | 4 | 21 | 5 |
| FunctionPrint.merge(Pair |
0 | 0 | 1 | 1 | 26 | 1 |
| FunctionPrint.print(ItemList) | 4 | 3 | 3 | 2 | 18 | 4 |
| FunctionPrint.sintoString(BigInteger) | 7 | 3 | 1 | 3 | 18 | 4 |
| FunctionPrint.toString(Item,BigInteger) | 2 | 1 | 2 | 4 | 12 | 4 |
| FunctionPrint.toString(Pair |
0 | 0 | 1 | 1 | 3 | 1 |
| FunctionPrint.way1(ArrayList |
25 | 12 | 7 | 10 | 43 | 14 |
| FunctionPrint.way2(ArrayList |
31 | 12 | 4 | 11 | 48 | 15 |
| Item.Item(BigInteger,BigInteger,BigInteger) | 0 | 0 | 1 | 1 | 5 | 1 |
| Item.compareTo(Item) | 2 | 2 | 3 | 3 | 9 | 3 |
| Item.equals(Object) | 4 | 2 | 3 | 4 | 12 | 6 |
| Item.getCos() | 0 | 0 | 1 | 1 | 3 | 1 |
| Item.getDeg() | 0 | 0 | 1 | 1 | 3 | 1 |
| Item.getSin() | 0 | 0 | 1 | 1 | 3 | 1 |
| Item.hashCode() | 0 | 0 | 1 | 1 | 4 | 1 |
| Item.minus(Item) | 0 | 0 | 1 | 1 | 5 | 1 |
| Item.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| ItemList.ItemList() | 0 | 0 | 1 | 1 | 5 | 1 |
| ItemList.diff() | 1 | 1 | 1 | 2 | 22 | 2 |
| ItemList.get(Object) | 0 | 0 | 1 | 1 | 3 | 1 |
| ItemList.getIterator() | 0 | 0 | 1 | 1 | 3 | 1 |
| ItemList.getall() | 1 | 1 | 1 | 2 | 10 | 2 |
| ItemList.insert(Item,BigInteger) | 3 | 2 | 2 | 2 | 13 | 3 |
| ItemList.toString() | 11 | 6 | 4 | 6 | 30 | 9 |
| Mainclass.main(String[]) | 2 | 1 | 1 | 2 | 19 | 2 |
| Minus.diff() | 0 | 0 | 1 | 1 | 7 | 1 |
| Minus.simply() | 2 | 2 | 1 | 3 | 18 | 3 |
| Minus.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Multiply.diff() | 0 | 0 | 1 | 1 | 13 | 1 |
| Multiply.simply() | 3 | 2 | 1 | 3 | 22 | 3 |
| Multiply.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Power.diff() | 0 | 0 | 1 | 1 | 16 | 1 |
| Power.simply() | 3 | 2 | 1 | 3 | 22 | 3 |
| Power.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| SinFunction.diff() | 0 | 0 | 1 | 1 | 6 | 1 |
| SinFunction.simply() | 0 | 0 | 1 | 1 | 6 | 1 |
| SinFunction.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| TreeNode.TreeNode() | 0 | 0 | 1 | 1 | 4 | 1 |
| TreeNode.getLch() | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.getRch() | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.setLch(TreeNode) | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.setRch(TreeNode) | 0 | 0 | 1 | 1 | 3 | 1 |
| Class | LOC | NAAC | NOAC | OCavg | OCmax | WMC |
| Add | 32 | 0 | 3 | 1.67 | 3 | 5 |
| Constant | 58 | 2 | 3 | 2.8 | 10 | 14 |
| CosFunction | 18 | 0 | 3 | 1 | 1 | 3 |
| Decoder | 241 | 13 | 15 | 3 | 8 | 45 |
| Function | 5 | 0 | 0 | 0 | ||
| FunctionPrint | 244 | 1 | 11 | 4.82 | 13 | 53 |
| Item | 54 | 3 | 5 | 1.44 | 3 | 13 |
| ItemList | 89 | 1 | 5 | 2.29 | 6 | 16 |
| Mainclass | 21 | 0 | 1 | 2 | 2 | 2 |
| Minus | 32 | 0 | 3 | 1.67 | 3 | 5 |
| Multiply | 42 | 0 | 3 | 1.67 | 3 | 5 |
| Power | 45 | 0 | 3 | 1.67 | 3 | 5 |
| Signal | 5 | 0 | 0 | 0 | ||
| SinFunction | 19 | 0 | 3 | 1 | 1 | 3 |
| TreeNode | 23 | 2 | 4 | 1 | 1 | 5 |
| Package | LOC | v(G)avg | v(G)tot | |||
| 961 | 2.76 | 196 | ||||
| Module | LOC | v(G)avg | v(G)tot | |||
| HW2 | 961 | 2.76 | 196 | |||
| Project | LOC | v(G)avg | v(G)tot | |||
| project | 961 | 2.76 | 196 | |||
度量分析发现:
在方法中FunctionPrint.way1和FunctionPrint.way2函数复杂度比较高,原因是这两个函数是用来进行输出优化的,可能比较面向过程。
在类中Decoder类复杂度较高,因为这个类是负责通过递归下降进行解析的整个模块,所以比较复杂。
在类中FunctionPrint类圈复杂度比较高,原因和第一条类似,因为way1和way2是其中优化的两个重要函数。
总代码行数961行,个人认为长度已经有些过长了。
3.类图分析
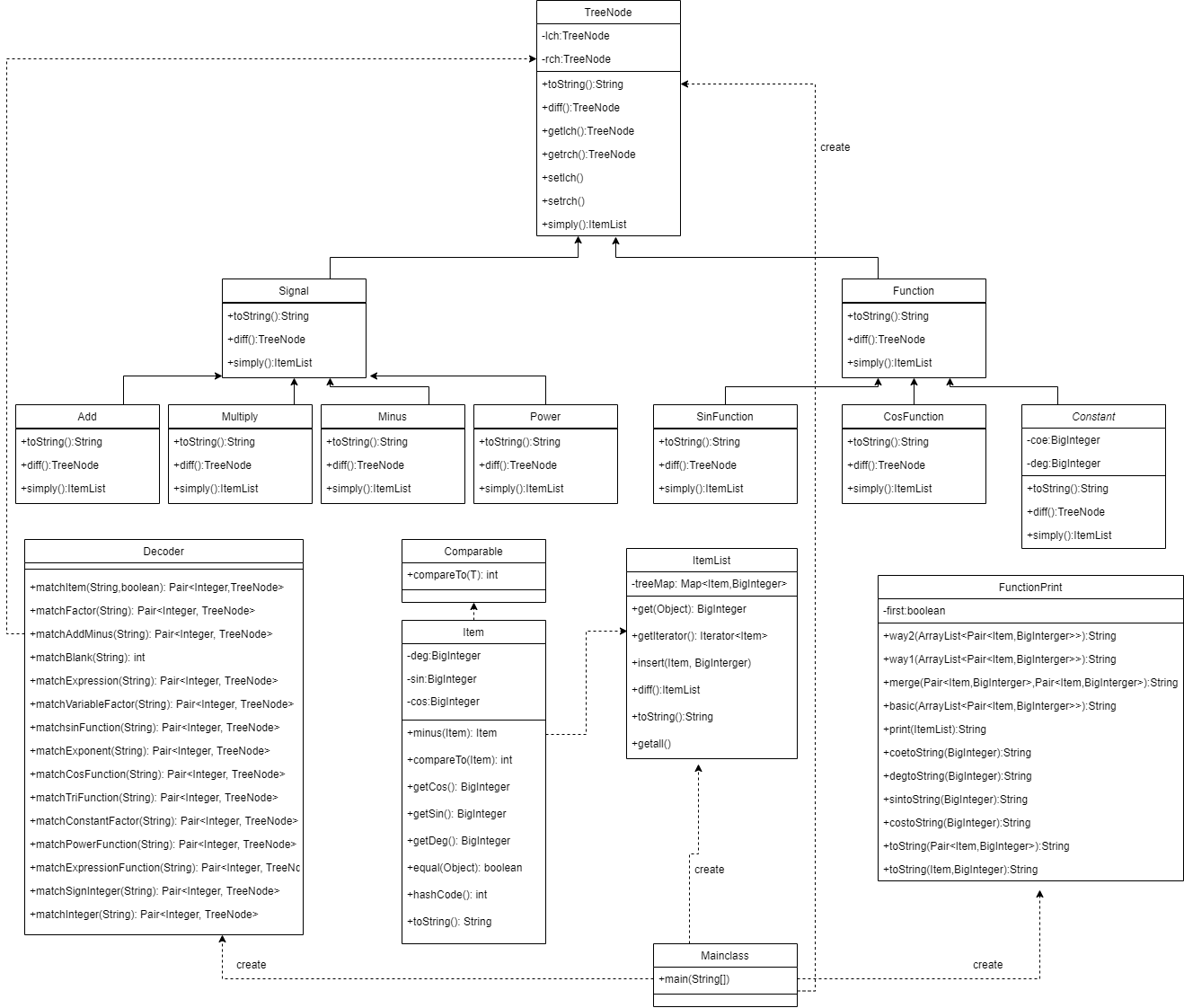
第二次作业中相比于第一次作业,结构优美了不少,形成了一个优美的树形结构:Constant、CosFunction、SinFunction继承Function类,Add、Multiply、Minus、Power继承Signal。Signal和Function继承TreeNode抽象类。这两者继承的主要是行为继承。
下面从各给类的角度给出设计思路:
Add
加法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Constant
基本幂函数类,在表达式树中处于叶子节点。包含二元组\((Coe,Deg)\)和第一次作业的幂函数效果功能一样。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
CosFunction
余弦函数类,仅包含一个子树表示嵌套的内层表达式(右子树无意义)。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Decoder
解析表达类,用于对输入的字符串进行递归下降解析,并将解析的字符串转换成表达式树类。
Function
函数抽象类,是Constant、CosFunction、SinFunction的父类,抽象构建了求导函数diff()、化简函数simply()和转换成字符串的函数toString()三个函数。
FunctionPrint
表达式化简输出类,里面实现了各种表达式的化简方法和输出方法,可以对一个ItemList类的表达式转换成字符串。其中实现了三种不同的方法basic、way1、way2.其中basic实现了最基本的按照系数从大到小排序的方法,way1实现了两项合并操作,way2实现了贪心的两项合并操作。
Item
三元组类,包含属性\((deg,sin,cos)\),分别表示幂函数的指数,sin函数的指数,cos函数的指数。相同的三元组可以在之后合并到一块。Item类实现了接口Comparable可以使得可以使用Item类建立一个Map。实现了转换成字符串函数toString()。
ItemList
基本表达式类,用一个\(Map<Item,Coe>\)存储了不同三元组对应的系数,可以用于进行合并同类项。里面实现了求导函数simply()和转换成字符串的toString()函数。
Minus
减法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Multiply
乘法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Power
幂函数类,这是一个二元运算符,它的左子树表示底数,右子树表示指数。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Signal
符号抽象类,是Add、Multiply、Minus、Power的父类,抽象构建了求导函数diff()、化简函数simply()和转换成字符串的函数toString()三个函数。
SinFunction
正弦函数类,仅包含一个子树表示嵌套的内层表达式(右子树无意义)。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
TreeNode
表达式树抽象类,这是存储结构中最基本的单元。属性包含左右两个子树lch和rch,它们都是TreeNode类型,这样通过多态的方式可以统一管理不同的表达式类型。类中抽象了三个重要函数求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Mainclass
整个项目的入口,统领整个项目,内容很简单。
下面进行简单的优缺点分析:
优点
- 整个项目严格按照指导书上的形式化定义产生的类,清晰明了。
- 通过使用表达式树统一管理,代码写的时候比较顺畅。
- 代码的耦合度有所下降,不同类管理不同的事情。
缺点
- Decoder类的递归下降写法非常冗余。
- PrintFunction表达式输出部分写的也非常冗余,优化做的其实很复杂,不够面向对象。
(三)第三次作业
1.方法分析
第三次作业在第二次作业的基础上\(sin()\)和\(cos()\)括号内部可以嵌套表达式因子,同时增加了判断WrongFormat部分。
WrongFormat的判断我继续使用递归下降的思路边建立表达式树边判断。
三角函数中嵌套表达式因子在存储中我继续使用上一次的架构,在优化部分中我进行了一点修改。
第三次作业我的代码分成了四部分:表达式输入、表达式存储、表达式求导和表达式输出。
在表达式输入部分,我采用递归下降的思路进行了匹配处理。通过文法分析将指导书上给的每一部分的形式化定义转换成右递归,之后通过Decoder类分别实现识别每一个部分的函数,将输入的表达式转换成表达式树,在判断过程中如果发现表达式不合法则会返回一棵空树,在上一级读入到空树会将非法逐级上传。
在表达式存储部分,我采用了表达式树进行了统一管理。
在表达式求导部分,我通过在表达式树上建立了转换方法,把一颗表达式树转换成了一棵Set。这棵Set由一堆Term组成,每个Term由四个部分组成\((deg,coe,cosMap,sinMap)\),分别表示幂函数的指数,系数,其余两个是两个Map。cosMap的类型是\(Map<Expression,Long>\),表示cos函数中不同的内部因子所代表的指数,这样就可以对表达式和项进行合并。求导时我是使用迭代器遍历所有Key值,直接对多项式进行求导,把求导后的结果用一棵新的Set来存储。
在表达式输出部分,我并没有做太多的优化,就是遍历每一项然后调用它们的toString()函数,因此这次作业的性能分相较于之前就比较差了。
2.度量分析
| Method | CogC | CONTROL | ev(G) | iv(G) | LOC | v(G) |
| Add.simply() | 0 | 0 | 1 | 1 | 8 | 1 |
| Add.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Constant.Constant(BigInteger,BigInteger) | 0 | 0 | 1 | 1 | 4 | 1 |
| Constant.Constant(String,String) | 0 | 0 | 1 | 1 | 4 | 1 |
| Constant.diff() | 3 | 1 | 2 | 3 | 14 | 3 |
| Constant.simply() | 0 | 0 | 1 | 1 | 6 | 1 |
| Constant.toString() | 14 | 9 | 10 | 14 | 37 | 14 |
| CosFunction.diff(Expression,long) | 0 | 0 | 1 | 1 | 10 | 1 |
| CosFunction.simply() | 0 | 0 | 1 | 1 | 8 | 1 |
| CosFunction.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| CosFunction.toString(Expression,long) | 4 | 3 | 2 | 2 | 16 | 4 |
| Decoder.init(String) | 9 | 5 | 6 | 4 | 26 | 6 |
| Decoder.matchBlank() | 5 | 3 | 3 | 2 | 11 | 4 |
| Decoder.matchCharacter(char) | 2 | 1 | 2 | 2 | 8 | 2 |
| Decoder.matchConstantFactor() | 1 | 1 | 2 | 1 | 7 | 2 |
| Decoder.matchCosFunction() | 12 | 7 | 8 | 4 | 37 | 10 |
| Decoder.matchExponent() | 8 | 3 | 4 | 4 | 20 | 6 |
| Decoder.matchExpression(boolean) | 12 | 6 | 6 | 6 | 39 | 9 |
| Decoder.matchExpressionFactor() | 6 | 3 | 4 | 2 | 17 | 4 |
| Decoder.matchFactor() | 2 | 2 | 3 | 1 | 15 | 3 |
| Decoder.matchInteger() | 1 | 1 | 2 | 2 | 9 | 2 |
| Decoder.matchItem(boolean) | 8 | 6 | 5 | 3 | 37 | 7 |
| Decoder.matchMinus() | 3 | 3 | 4 | 3 | 12 | 4 |
| Decoder.matchPowerFunction() | 5 | 4 | 5 | 2 | 20 | 5 |
| Decoder.matchSignInteger() | 2 | 2 | 3 | 2 | 11 | 3 |
| Decoder.matchSinFunction() | 13 | 7 | 8 | 4 | 40 | 10 |
| Decoder.matchVariableFactor() | 2 | 2 | 3 | 1 | 17 | 3 |
| Decoder.setExpression(String) | 0 | 0 | 1 | 1 | 3 | 1 |
| Decoder.startMatch(String) | 2 | 1 | 2 | 2 | 8 | 2 |
| Expression.Expression() | 0 | 0 | 1 | 1 | 3 | 1 |
| Expression.add(Expression) | 1 | 1 | 1 | 2 | 5 | 2 |
| Expression.add(Term) | 5 | 5 | 4 | 4 | 22 | 5 |
| Expression.compareTo(Expression) | 0 | 0 | 1 | 1 | 4 | 1 |
| Expression.contains(Term) | 0 | 0 | 1 | 1 | 3 | 1 |
| Expression.diff() | 1 | 1 | 1 | 2 | 7 | 2 |
| Expression.equals(Object) | 7 | 6 | 6 | 3 | 20 | 7 |
| Expression.getTerm() | 2 | 2 | 3 | 3 | 9 | 3 |
| Expression.getpow() | 1 | 1 | 2 | 2 | 6 | 2 |
| Expression.hashCode() | 0 | 0 | 1 | 1 | 4 | 1 |
| Expression.mul(Expression) | 3 | 2 | 1 | 3 | 10 | 3 |
| Expression.negate() | 1 | 1 | 1 | 2 | 7 | 2 |
| Expression.power(long) | 1 | 1 | 1 | 2 | 7 | 2 |
| Expression.remove(Term) | 0 | 0 | 1 | 1 | 3 | 1 |
| Expression.setTermSet(Set |
0 | 0 | 1 | 1 | 3 | 1 |
| Expression.toString() | 6 | 4 | 1 | 3 | 22 | 5 |
| Mainclass.main(String[]) | 1 | 1 | 2 | 2 | 14 | 2 |
| Minus.simply() | 0 | 0 | 1 | 1 | 8 | 1 |
| Minus.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Multiply.simply() | 0 | 0 | 1 | 1 | 6 | 1 |
| Multiply.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| Negative.simply() | 0 | 0 | 1 | 1 | 6 | 1 |
| Negative.toString() | 0 | 0 | 1 | 1 | 4 | 1 |
| Power.simply() | 1 | 1 | 2 | 2 | 12 | 2 |
| Power.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| SinFunction.diff(Expression,long) | 0 | 0 | 1 | 1 | 10 | 1 |
| SinFunction.simply() | 0 | 0 | 1 | 1 | 8 | 1 |
| SinFunction.toString() | 0 | 0 | 1 | 1 | 5 | 1 |
| SinFunction.toString(Expression,long) | 4 | 3 | 2 | 2 | 16 | 4 |
| Term.Term() | 0 | 0 | 1 | 1 | 6 | 1 |
| Term.Term(BigInteger,long) | 0 | 0 | 1 | 1 | 6 | 1 |
| Term.addcos(Expression,long) | 2 | 2 | 2 | 2 | 10 | 3 |
| Term.addsin(Expression,long) | 2 | 2 | 2 | 2 | 10 | 3 |
| Term.compareTo(Term) | 1 | 1 | 2 | 2 | 7 | 2 |
| Term.copy() | 2 | 2 | 1 | 3 | 18 | 3 |
| Term.diff() | 2 | 2 | 1 | 3 | 37 | 3 |
| Term.equals(Object) | 13 | 9 | 8 | 9 | 33 | 14 |
| Term.getCoe() | 0 | 0 | 1 | 1 | 3 | 1 |
| Term.getTerm() | 5 | 3 | 2 | 2 | 16 | 5 |
| Term.hashCode() | 0 | 0 | 1 | 1 | 4 | 1 |
| Term.merge(Term) | 2 | 2 | 1 | 3 | 18 | 3 |
| Term.negate() | 0 | 0 | 1 | 1 | 5 | 1 |
| Term.power(long) | 2 | 2 | 1 | 3 | 18 | 3 |
| Term.same(Term) | 10 | 7 | 6 | 7 | 25 | 10 |
| Term.setCoe(BigInteger) | 0 | 0 | 1 | 1 | 3 | 1 |
| Term.toString() | 31 | 18 | 6 | 9 | 59 | 18 |
| TreeNode.TreeNode() | 0 | 0 | 1 | 1 | 4 | 1 |
| TreeNode.getLch() | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.getRch() | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.setLch(TreeNode) | 0 | 0 | 1 | 1 | 3 | 1 |
| TreeNode.setRch(TreeNode) | 0 | 0 | 1 | 1 | 3 | 1 |
| Class | LOC | NAAC | NOAC | OCavg | OCmax | WMC |
| Add | 15 | 0 | 2 | 1 | 1 | 2 |
| Constant | 69 | 2 | 3 | 3 | 10 | 15 |
| CosFunction | 41 | 0 | 4 | 1.75 | 4 | 7 |
| Decoder | 352 | 13 | 18 | 4.11 | 8 | 74 |
| Expression | 138 | 1 | 12 | 2.38 | 6 | 38 |
| Function | 4 | 0 | 0 | n/a | n/a | 0 |
| Mainclass | 16 | 0 | 1 | 2 | 2 | 2 |
| Minus | 15 | 0 | 2 | 1 | 1 | 2 |
| Multiply | 13 | 0 | 2 | 1 | 1 | 2 |
| Negative | 12 | 0 | 2 | 1 | 1 | 2 |
| Power | 19 | 0 | 2 | 1.5 | 2 | 3 |
| Signal | 4 | 0 | 0 | n/a | n/a | 0 |
| SinFunction | 41 | 0 | 4 | 1.75 | 4 | 7 |
| Term | 284 | 4 | 12 | 3.59 | 17 | 61 |
| TreeNode | 22 | 2 | 4 | 1 | 1 | 5 |
| Package | LOC | v(G)avg | v(G)tot | |||
| 1,069 | 3.09 | 247 | ||||
| Module | LOC | v(G)avg | v(G)tot | |||
| HW3 | 1,069 | 3.09 | 247 | |||
| Project | LOC | v(G)avg | v(G)tot | |||
| project | 1,069 | 3.09 | 247 |
度量分析发现:
在方法中Expression.equal、Expression.add和Term.equal函数复杂度比较高,原因是在重载相等函数或者是像一个表达式中增加因子时,都需要对Map或者Set进行大量的遍历和判断(而且每个Term还有两个Map),因此确实这三个方法比较复杂。
在方法中Term.toString函数圈复杂度极高,因为在输出的时候我是把四个部分一块统一输出成字符串的,使用了大量的if判断,非常的面向过程。
在类中Decoder类复杂度较高,因为这个类是负责通过递归下降进行解析的整个模块,所以比较复杂。
在类中Expression类和Term类方法复杂度比较高,原因和前两条类似,因为其中的方法都是非常复杂的。
总代码行数1069行,个人认为长度比较长,但相比于前两次的增量这次的重构力度并没有那么大。
3.类图分析
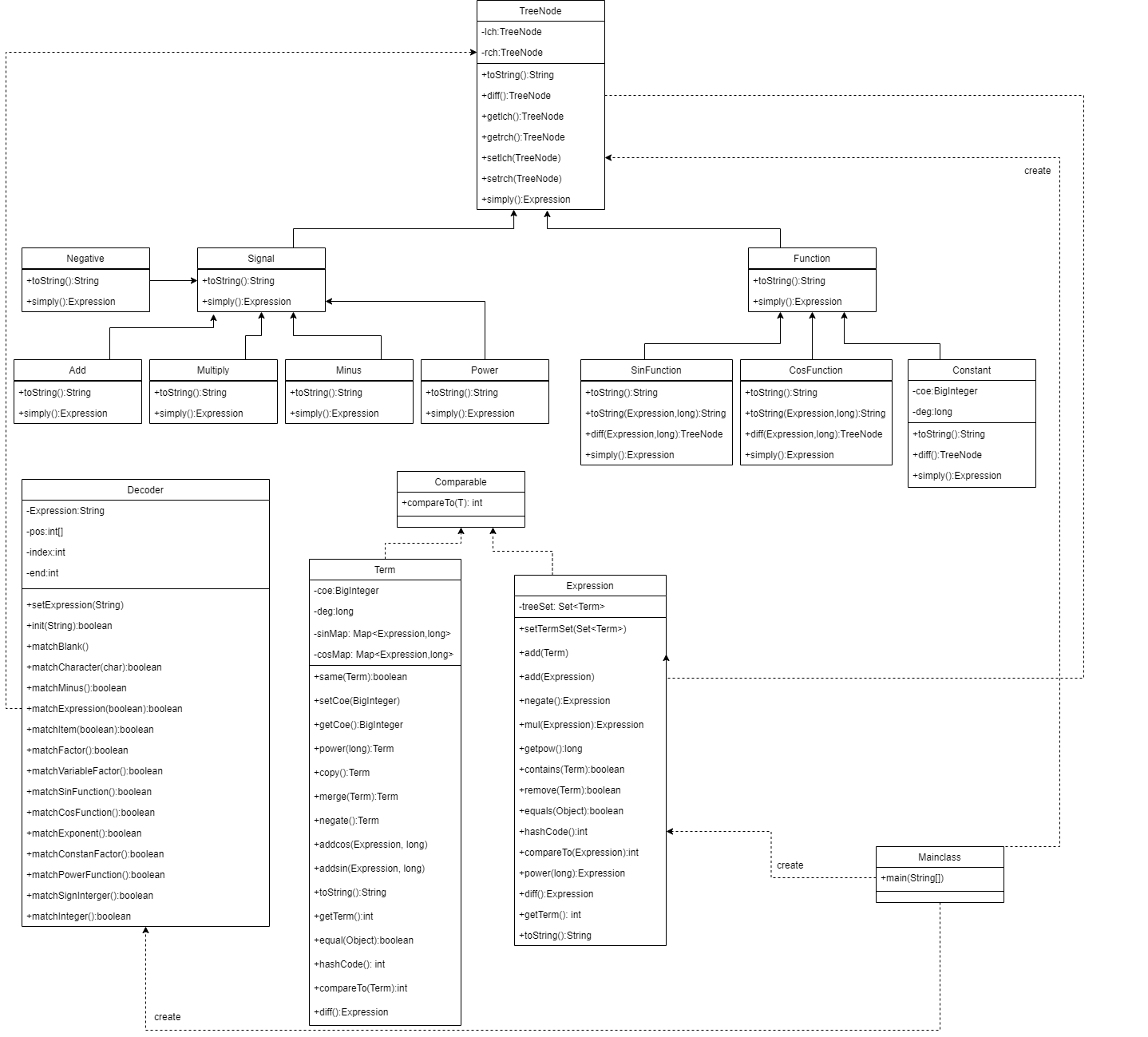
第三次作业和第二次作业的结构类似,依然是优美的树形结构:Constant、CosFunction、SinFunction继承Function类,Add、Multiply、Minus、Negative、Power继承Signal。Signal和Function继承TreeNode抽象类。这两者继承的主要是行为继承。
下面从各给类的角度给出设计思路:
Add
加法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含化简函数simply()和转换成字符串的函数toString()。
Constant
基本幂函数类,在表达式树中处于叶子节点。包含二元组\((Coe,Deg)\)和第一次作业的幂函数效果功能一样。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
CosFunction
余弦函数类,仅包含一个子树表示嵌套的内层表达式(右子树无意义)。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
Decoder
解析表达类,用于对输入的字符串进行递归下降解析,并将解析的字符串转换成表达式树类,并在构建表达式树的进程中将WrongFormat判掉。
Function
函数抽象类,是Constant、CosFunction、SinFunction的父类,抽象构建了化简函数simply()和转换成字符串的函数toString()两个函数。
Expression
表达式类,里面用一个由Term组成的Set存储一个表达式。表达式类同样可以用于维护表达式因子。表达式实现了equal和hashcode,用于在Term类中使用HashMap合并sin和cos函数。表达式类还实现了取反、合并、求导等函数用于表达式的优化和输出。
Term
项类。每一个项包含四个属性coe,deg,sinMap和cosMap。其中coe是BigInteger类型用于表示这个项的系数,deg是long类型用于存储幂函数的指数,sinMap是用Map维护了sin括号内不同表达式的表达式和指数,cosMap是用Map维护了cos括号内不同表达式的表达式和指数。Term实现了compareTo接口,用于在Expression中维护Set。同时在项类中还实现了求导、转换成字符串等函数用于表达式的优化和输出。
Negative
负数类,这是一个一元运算符,仅用左子树表示需要取反的表达式。类中包含化简函数simply()和转换成字符串的函数toString()。
Minus
减法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含化简函数simply()和转换成字符串的函数toString()。
Multiply
乘法类,这是一个二元运算符,它的左子树和右子树分别代表了两个表达式。类中包含化简函数simply()和转换成字符串的函数toString()。
Power
幂函数类,这是一个二元运算符,它的左子树表示底数,右子树表示指数。类中包含求化简函数simply()和转换成字符串的函数toString()。
Signal
符号抽象类,是Negative、Add、Multiply、Minus、Power的父类,抽象构建了化简函数simply()和转换成字符串的函数toString()三个函数。
SinFunction
正弦函数类,仅包含一个子树表示嵌套的内层表达式(右子树无意义)。类中包含求导函数diff()、化简函数simply()和转换成字符串的函数toString()。
TreeNode
表达式树抽象类,这是存储结构中最基本的单元。属性包含左右两个子树lch和rch,它们都是TreeNode类型,这样通过多态的方式可以统一管理不同的表达式类型。类中抽象了两个重要函数化简函数simply()和转换成字符串的函数toString()。
Mainclass
整个项目的入口,统领整个项目,内容很简单。
下面进行简单的优缺点分析:
优点
- 整个项目严格按照指导书上的形式化定义产生的类,清晰明了。
- 通过使用表达式树统一管理,代码写的时候比较顺畅。
- 代码的耦合度较低,不同类管理不同的事情。
- 递归下降使用全局变量,写的思路比较清晰。
缺点
-
Decoder类的递归下降在判断WrongFormat时选择像上层传递空指针,不如使用异常处理更加面向对象。
-
Expression类和Term类内容繁多,有些函数可以不属于其中。
-
未对最后输出进行优化,性能不是很好。
二、分析自己程序的bug
(一)第一次作业
在第一次作业中,所有公测数据都通过了,互测数据有两个点未通过(是1个bug)。
这个bug,很难直接定位是在代码的某一部分,因为是思路上的一个问题。
由于我在第一次作业中使用了大正则表达式匹配,所有导致在出现形如数据\(x \times x \times ...\times x\)的数据会出现段错误的情况,原因是正则表达式过长导致的递归爆栈。相比于未出现bug方法,这个方法的代码长度并不长,但是圈复杂度是很高的(正则表达式太长了)。
这次的bug提醒我,以后在使用正则表达式时,一是注意使用非获取匹配,二是注意使用更短的正则表达式。
(二)第一次作业
在第二次作业中,所有公测数据和互测数据都已通过。
(三)第一次作业
在第三次作业中,所有公测数据和互测数据都已通过。
三、分析其他同学程序的bug
(一)第一次作业
第一次作业我采用跑评测机(使用python生成随机数据)+看代码的调试方法,但是很遗憾并没有找到其他同学的bug。
(二)第二次作业
第二次作业我采用是跑评测机(使用python生成随机数据)+测试极端数据。测试极端数据一般都是比较容易出错的数据[比如数据\(((((((((x))))))))\)],再加上使用评测机测试出三名同学的bug。
(三)第三次作业
第三次作业我先采用了测试极端数据(就是我当时写代码时测试出错的数据),结果发现大家的代码都很优秀,没有很好的跑出想要的结果。之后我通过看代码的方式看出了一名同学的bug,但是由于互测时hack数据指数不能为0导致这个bug并没有办法提交。之后我就采用跑评测机的方式,首先发现两名同学的bug(TA们都是正确的表达式判成了WrongFormat),我根据它们错误的数据(这个数据很长,没办法直接提交),定位回它们的代码,发现对于乘号和\(sin\)函数之间加括号的问题,它们会判断错误,构造了一组数据hack了TA们。
四、重构经历总结
根据上面第一次作业和第二次作业的类图,可以看出我第一次结构更加面向过程,第二次结构更加面向对象。当时自己因为使用了大正则表达式导致互测被hack,只能塌下心来认真重构。第二次作业时在写递归下降和表达式树结构时是非常痛苦的,一方面自己对递归下降的理解不是很到位,不确定自己写的是不是正确的递归下降法,但是还是在ddl的推动下完成了递归下降的构建。当时自己的思路还是很清晰的,就是一部分一部分去完成,先完成递归下降部分,完成后使用大量的数据去测试我的代码直到我基本保证对于字符串的处理没有太大的问题。之后再完成表达式树的构建、求导。当确定自己的代码正确性没有太大问题之后,再去上优化,这样第二次作业也就取得了比较好的成绩。第三次作业和第二次作业的类图基本没有太大改动,但是还是重构了递归下降的方法,不过由于上一次的方法的正确性已经有了保证并且也在之前判断了WrongFormat,因此写的也还算顺利。
五、心得体会与反思
- 经过第一次作业的洗礼,对面向对象课程有了一个大致的理解,认识到写博客的重要性,相当于一次总结和反思。
- 认识到面向对象和面向过程的区别,大致感受到如何写好一个面向对象的程序
- 认识到架构设计的重要性,一个好的架构可以说是事半功倍,一定要让各个类要做到解耦合,每个类干自己的工作。
- 学习到了递归下降处理文法的方法。
- 认识到对于正则表达式使用时的一些注意事项。
- 获得了一次相当于工程开发的能力,锻炼了代码能力。
- 对java语言有了更深一步的理解,学习了其中容器的使用方法和要求。
- 对自动评测机,还需要了解如何扩展和改进。
- 还是需要学习如何更加科学的对程序进行数据测试。
- 更需要和同学们、老师们交流架构模型,从其他同学那里学习到新的思路。

