Zeppelin0.5.6使用spark解释器
Zeppelin为0.5.6
Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用。
使用其他的spark集群在yarn模式下。
配置:
vi zeppelin-env.sh

添加:
export SPARK_HOME=/usr/crh/current/spark-client export SPARK_SUBMIT_OPTIONS="--driver-memory 512M --executor-memory 1G" export HADOOP_CONF_DIR=/etc/hadoop/conf
Zeppelin Interpreter配置

注意:设置完重启解释器。
Properties的master属性如下:

新建Notebook
Tips:几个月前zeppelin还是0.5.6,现在最新0.6.2,zeppelin 0.5.6写notebook时前面必须加%spark,而0.6.2若什么也不加就默认是scala语言。
zeppelin 0.5.6不加就报如下错:
Connect to 'databank:4300' failed
%spark.sql select count(*) from tc.gjl_test0
报错:
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
at [Source: {"id":"2","name":"ConvertToSafe"}; line: 1, column: 1]
at com.fasterxml.jackson.databind.JsonMappingException.from(JsonMappingException.java:148)
at com.fasterxml.jackson.databind.DeserializationContext.mappingException(DeserializationContext.java:843)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.addBeanProps(BeanDeserializerFactory.java:533)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.buildBeanDeserializer(BeanDeserializerFactory.java:220)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.createBeanDeserializer(BeanDeserializerFactory.java:143)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer2(DeserializerCache.java:409)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer(DeserializerCache.java:358)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCache2(DeserializerCache.java:265)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCacheValueDeserializer(DeserializerCache.java:245)
at com.fasterxml.jackson.databind.deser.DeserializerCache.findValueDeserializer(DeserializerCache.java:143)
at com.fasterxml.jackson.databind.DeserializationContext.findRootValueDeserializer(DeserializationContext.java:439)
at com.fasterxml.jackson.databind.ObjectMapper._findRootDeserializer(ObjectMapper.java:3666)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3558)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2578)
at org.apache.spark.rdd.RDDOperationScope$.fromJson(RDDOperationScope.scala:85)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:136)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.ConvertToSafe.doExecute(rowFormatConverters.scala:56)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:130)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:187)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.ZeppelinContext.showDF(ZeppelinContext.java:297)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:144)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
进入/opt/zeppelin-0.5.6-incubating-bin-all目录下:
# ls lib |grep jackson jackson-annotations-2.5.0.jar jackson-core-2.5.3.jar jackson-databind-2.5.3.jar
将里面的版本换成如下版本:
# ls lib |grep jackson jackson-annotations-2.4.4.jar jackson-core-2.4.4.jar jackson-databind-2.4.4.jar
测试成功!
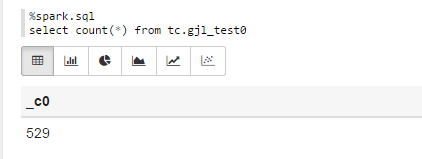
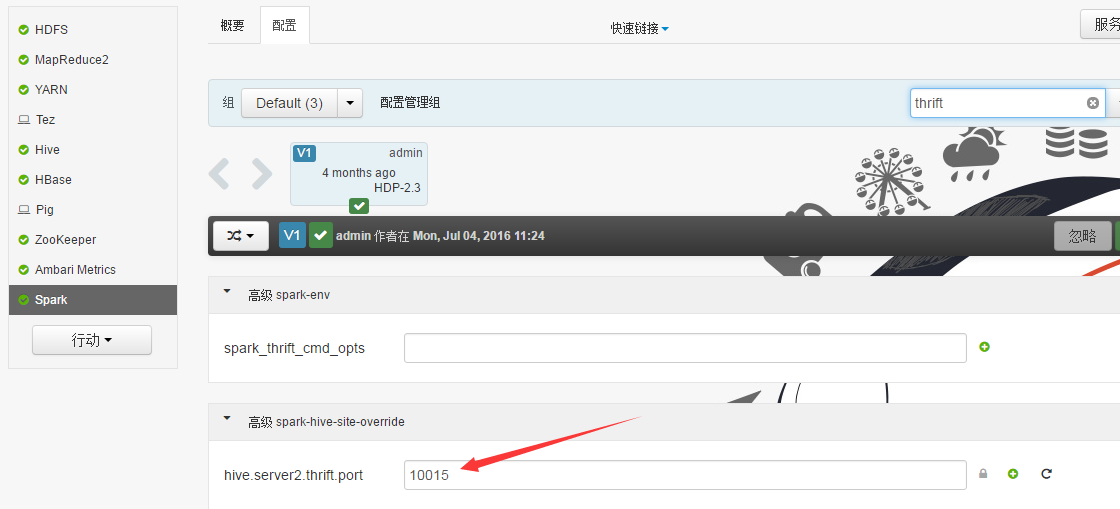
Sparksql也可直接通过hive jdbc连接,只需换端口,如下图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号