记一次为解决Python读取PDF文件的Shell操作
一、背景
本想将 PDF 文件转换为 Word 文档,然后网上搜索了一下发现有挺多转换的软件。有的是免费的、收费,咱也不知哪个好使,还得一个个安装试用。先不说能不解决问题,就这安装试用想想就脑壳疼。便想起了"Python 大法",随即搜了几篇看起来比较完整的博客,二话不说粘贴复制,改改运行试试。使用环境(python3.6+pdfminer3k),代码这里就不放出来了。
二、问题
运气不好,这一试就报错WARNING:root:GBK-EUC-H,然后又搜了一下有同样的报错问题,但是这篇博客没啥大用,仅仅是知道缺了相关的字体文件,通过其中的链接顺藤摸瓜找到了 github 上的字体文件列表页
https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap
三、解决
下载了报错的对应文件 GBK-EUC-H.pickle.gz,然后将其文件解压把放置 Python 的安装目录下 Lib\site-packages\pdfminer\cmap 路径中,再次运行又报错 "pdfminer.converter:undefined: <PDFCIDFont: basefont='΢ÈíÑźÚ', cidcoding='Adobe-GB1'>, 3027" 。可以说明第一个问题已经解决了,接下来的报错按照这个方法来就行了。但是想想等下有报错还得下,索性全部下下来。
四、一顿分析及 Shell 操作
1.先网页 F12 打开控制台分析 Element 元素,Xpath 信息 "//td[@class='content']/span/a/@href"
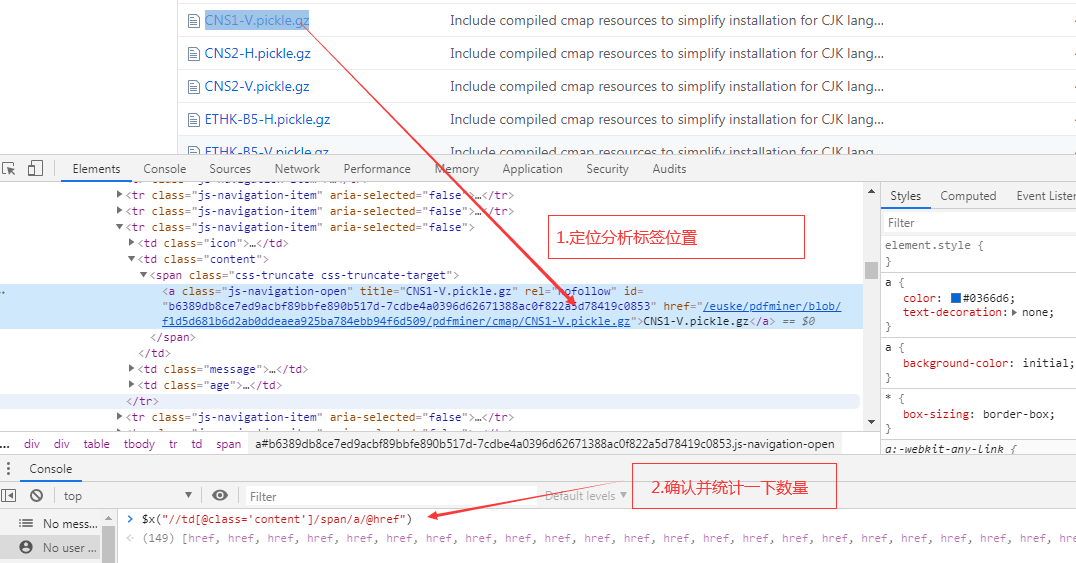
2.使用 curl 命令获取响应并处理 (通过"检查网页源码"发现 span 标签和 a 标签同行)
- 先确认是否与步骤 1 中的数量一致
# 通过获取父标签信息的之后的行
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -A1 '<td class="content">' |grep "<span" | wc -l
# 直接正则匹配到行
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -E '\s+<span.*><a.*title' |wc -l
- 确认一致,则进行下一步数据清理,进而获得所有字体文件列表
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -E '\s+<span.*><a.*title' |awk -F '"' '{print $6}'
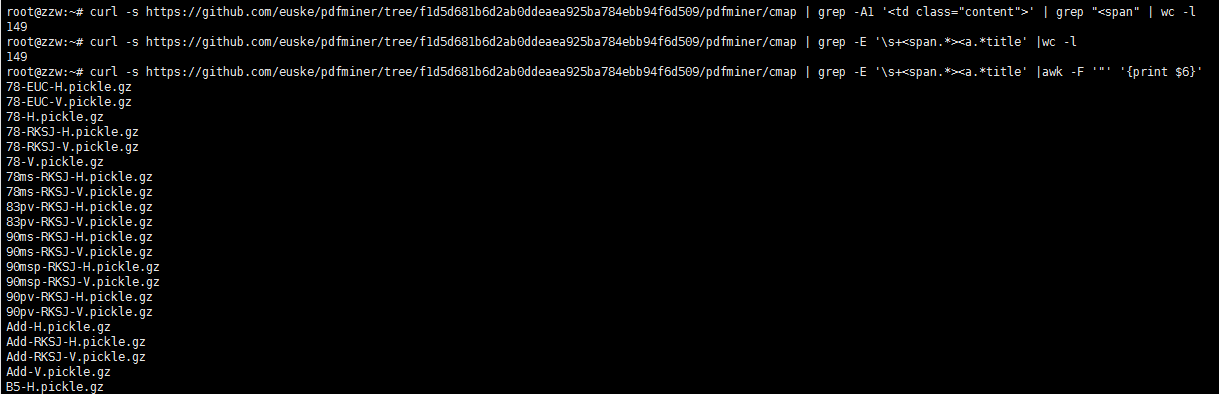
3.进入某个文件详情页,分析下载请求地址
将下面链接放入地址栏,会进入文件下载操作,所以这就是文件的真实下载地址

4.对其他两三个文件进行同样分析,发现其规律,部分固定链接地址
https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap
5.开始命令行构造下载地址
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap \
|grep -E '\s+<span.*><a.*title'|awk -F '"' '{print $6}'|while read line; do echo \
"https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/$line"; done
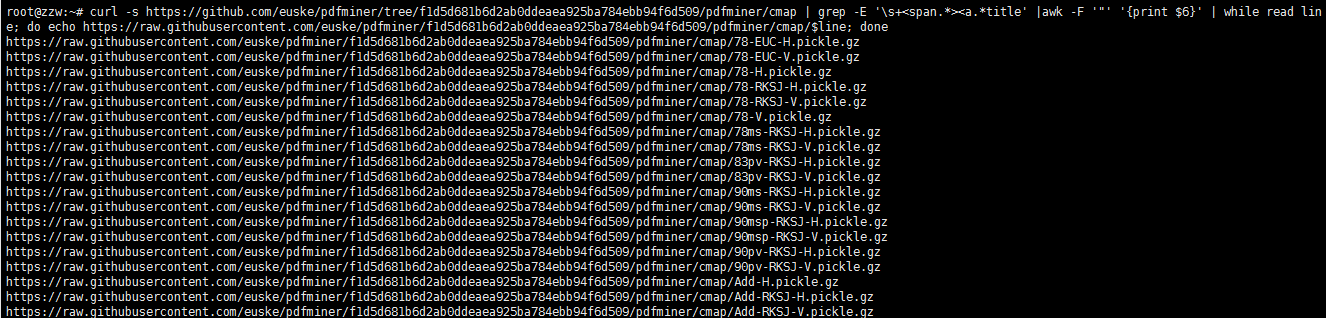
6.升级-->构造及文件下载脚本
# !/usr/bin/bash
# 参数校验
folder=$1
# 参数为空判断
[ -z $folder ] && folder="downfiles"
# 为文件且存在判断,不能重名
if [ -f $folder ]
then
echo "Error: 【$folder】 already exist! and it's file"
exit
fi
# 不存在则创建
if [ ! -e $folder ]
then
mkdir $folder
fi
echo ""
echo "文件保存路径为: $PWD/$folder"
echo ""
# github 主页列表显示地址
listPage="https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap"
# github 详情显示地址
# https://github.com/euske/pdfminer/blob/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/
# github 下载按钮地址
# https://github.com/euske/pdfminer/raw/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/
# 真实下载地址
base="https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/"
# 模拟浏览器
userAgent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
files=`curl -s -A "${userAgent}" $listPage | grep -E '\s+<span.*><a.*title' | awk -F '"' '{print $6}'`
if [ -z "$files" ]
then
echo "获取列表信息失败!!!"
exit
else
num=`echo $files| awk 'BEGIN{RS=" "}END{print NR}'`
echo "成功获取列表信息, 总共 $num"
fi
echo ""
for name in $files
do
# infos="curl -s -A \"${userAgent}\" -w %{http_code} \"$base$name\" -o $folder/$name"
sleep 1
res=`curl -s -A "${userAgent}" -w %{http_code} "$base$name" -o $folder/$name`
if [ "$res" = "200" ]
then
echo "SUCCESS: 【$name】 下载成功"
else
# echo $infos
echo "ERROR: 【$name】 下载失败--$res"
sleep 0.5
fi
done
五、后续
文件下载失败返回码为 000 ----待分析解决


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律