
kubeadm部署单master多node集群
一 基础环境
系统版本:centos7.6
内核版本:3.10.0-957
podSubnet(pod网段) 10.244.0.0/16
serviceSubnet(service网段): 10.10.0.0/16
配置: 2Gib内存/2vCPU/100G硬盘
网络:NAT
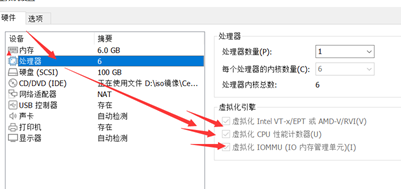
开启虚拟机的虚拟化:
集群ip
| 192.168.64.120 | master |
| 192.168.64.121 | node01 |
| 192.168.64.122 | node02 |
二 初始化集群
关闭防火墙:
systemctl stop firewalld ; systemctl disable firewalld
关闭selinux:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config #重启生效 reboot getenforce Disabled
关闭swap:
#临时关闭 [root@master ~]# swapoff -a #永久关闭:注释swap挂载,给swap这行开头加一下注释 [root@master ~]# vi /etc/fstab #/dev/mapper/centos-swap swap swap defaults 0 0 #如果是克隆的虚拟机,需要删除UUID
修改内核参数:
[root@master ~]# modprobe br_netfilter [root@master ~]# echo "modprobe br_netfilter" >> /etc/profile [root@master ~]# cat > /etc/sysctl.d/k8s.conf <<EOF > net.bridge.bridge-nf-call-ip6tables = 1 > net.bridge.bridge-nf-call-iptables = 1 > net.ipv4.ip_forward = 1 > EOF [root@master ~]# sysctl -p /etc/sysctl.d/k8s.conf
开启ipvs:
[root@master yum.repos.d]# cd /etc/sysconfig/modules/ [root@master modules]# cat ipvs.modules #!/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ 0 -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done [root@master modules]# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ip_vs_ftp 13079 0 nf_nat 26787 1 ip_vs_ftp ip_vs_sed 12519 0 ip_vs_nq 12516 0 ip_vs_sh 12688 0 ip_vs_dh 12688 0 ip_vs_lblcr 12922 0 ip_vs_lblc 12819 0 ip_vs_wrr 12697 0 ip_vs_rr 12600 0 ip_vs_wlc 12519 0 ip_vs_lc 12516 0 ip_vs 145497 22 ip_vs_dh,ip_vs_lc,ip_vs_nq,ip_vs_rr,ip_vs_sh,ip_vs_ftp,ip_vs_sed,ip_vs_wlc,ip_vs_wrr,ip_vs_lblcr,ip_vs_lblc nf_conntrack 133095 2 ip_vs,nf_nat libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrackscp
配置静态ip:
[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=eth0 UUID=561f7d9f-ebca-401a-9ac5-06f9c91df4ae DEVICE=eth0 ONBOOT=yes IPADDR=192.168.64.120 PREFIX=24 GATEWAY=192.168.64.2 DNS1=192.168.64.2 IPV6_PRIVACY=no
[root@master ~]# systemctl restart network
修改主机名称:
[root@master ~]# hostnamectl set-hostname master && bash [root@node01 ~]# hostnamectl set-hostname node01 && bash [root@node02 ~]# hostnamectl set-hostname node02 && bash
配置hosts:
[root@master ~]# cat >> /etc/hosts << EOF > 192.168.64.120 master > 192.168.64.121 node01 > 192.168.64.122 node02 > EOF
配置免密连接:
[root@master ~]# ssh-keygen 一路回车 [root@master ~]# ssh-copy-id master [root@master ~]# ssh-copy-id node01 [root@master ~]# ssh-copy-id node02
配置时间同步:
[root@master yum.repos.d]# yum install ntpdate -y [root@master yum.repos.d]# ntpdate ntp1.aliyun.com [root@node01 yum.repos.d]# crontab -e * */5 * * * /usr/sbin/ntpdate ntp1.aliyun.com >/dev/null 2>&1
安装基础工具:
[root@master ~]# yum install -y yum-utils device-mapper-persistent-data bash-completion lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate telnet ipvsadm
#GPG key retrieval failed: [Errno 14] curl#37 - "Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7"
#将epel源文件中的gpgcheck=1改为0即可
安装iptables:
[root@master ~]# yum install iptables-services -y [root@master ~]# systemctl stop iptables && systemctl disable iptables [root@master ~]# iptables -F
配置阿里云yum源:
#安装传输工具lrzsz和scp [root@master ~]# yum install lrzsz openssh-clients -y #备份原有yum源 [root@master ~]# cd /etc/yum.repos.d/ [root@master yum.repos.d]# mkdir bak [root@master yum.repos.d]# mv * bak/ #配置阿里云yum源 [root@master yum.repos.d]# cat CentOS-Base.repo # CentOS-Base.repo # # The mirror system uses the connecting IP address of the client and the # update status of each mirror to pick mirrors that are updated to and # geographically close to the client. You should use this for CentOS updates # unless you are manually picking other mirrors. # # If the mirrorlist= does not work for you, as a fall back you can try the # remarked out baseurl= line instead. # # [base] name=CentOS-$releasever - Base - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/ http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/ http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 #released updates [updates] name=CentOS-$releasever - Updates - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/ http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/ http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 #additional packages that may be useful [extras] name=CentOS-$releasever - Extras - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/ http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/ http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 #additional packages that extend functionality of existing packages [centosplus] name=CentOS-$releasever - Plus - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos/$releasever/centosplus/$basearch/ http://mirrors.aliyuncs.com/centos/$releasever/centosplus/$basearch/ http://mirrors.cloud.aliyuncs.com/centos/$releasever/centosplus/$basearch/ gpgcheck=1 enabled=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 #contrib - packages by Centos Users [contrib] name=CentOS-$releasever - Contrib - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos/$releasever/contrib/$basearch/ http://mirrors.aliyuncs.com/centos/$releasever/contrib/$basearch/ http://mirrors.cloud.aliyuncs.com/centos/$releasever/contrib/$basearch/ gpgcheck=1 enabled=0 gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7 #传输配置到node节点 [root@master yum.repos.d]# scp CentOS-Base.repo node01:/etc/yum.repos.d/ [root@master yum.repos.d]# scp CentOS-Base.repo node02:/etc/yum.repos.d/ #更新yum缓存 [root@master yum.repos.d]# yum clean all [root@master yum.repos.d]# yum makecache fast
三 安装docker
配置国内阿里云docker的repo源
#配置repo源 [root@master yum.repos.d]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -bash: yum-config-manager: command not found 这个是因为系统默认没有安装这个命令,yum -y install yum-utils 安装就可以了。 #配置epel源 [root@master yum.repos.d]# cat epel.repo [epel] name=Extra Packages for Enterprise Linux 7 - $basearch #baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch&infra=$infra&content=$contentdir failovermethod=priority enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 [epel-debuginfo] name=Extra Packages for Enterprise Linux 7 - $basearch - Debug #baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch/debug metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-debug-7&arch=$basearch&infra=$infra&content=$contentdir failovermethod=priority enabled=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 gpgcheck=1 [epel-source] name=Extra Packages for Enterprise Linux 7 - $basearch - Source #baseurl=http://download.fedoraproject.org/pub/epel/7/SRPMS metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-source-7&arch=$basearch&infra=$infra&content=$contentdir failovermethod=priority enabled=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 gpgcheck=1
安装docker指定版本
yum install docker-ce-20.10.6 docker-ce-cli-20.10.6 containerd.io -y
systemctl start docker && systemctl enable docker.service
配置镜像加速器
[root@master ~]# cat /etc/docker/daemon.json { "registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com", "https://rncxm540.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } [root@master ~]# systemctl daemon-reload && systemctl restart docker && systemctl status docker
四 部署k8s集群
配置安装k8s组件需要的阿里云的repo源
[root@master yum.repos.d]# vi kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 [root@master yum.repos.d]# scp kubernetes.repo node01:/etc/yum.repos.d/ [root@master yum.repos.d]# scp kubernetes.repo node02:/etc/yum.repos.d/
导入镜像(镜像包自备)
[root@master ~]# ll total 1058244 -rw-r--r-- 1 root root 1083635200 Nov 11 17:23 k8simage-1-20-6.tar.gz [root@master ~]# scp k8simage-1-20-6.tar.gz node01:/root/ [root@master ~]# scp k8simage-1-20-6.tar.gz node02:/root/ [root@master ~]# docker load -i k8simage-1-20-6.tar.gz
[root@master ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.aliyuncs.com/google_containers/kube-proxy v1.20.6 9a1ebfd8124d 7 months ago 118MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.20.6 b05d611c1af9 7 months ago 122MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.20.6 b93ab2ec4475 7 months ago 47.3MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.20.6 560dd11d4550 7 months ago 116MB
calico/pod2daemon-flexvol v3.18.0 2a22066e9588 9 months ago 21.7MB
calico/node v3.18.0 5a7c4970fbc2 9 months ago 172MB
calico/cni v3.18.0 727de170e4ce 9 months ago 131MB
calico/kube-controllers v3.18.0 9a154323fbf7 9 months ago 53.4MB
registry.aliyuncs.com/google_containers/etcd 3.4.13-0 0369cf4303ff 15 months ago 253MB
registry.aliyuncs.com/google_containers/coredns 1.7.0 bfe3a36ebd25 17 months ago 45.2MB
registry.aliyuncs.com/google_containers/pause 3.2 80d28bedfe5d 21 months ago 683kB
安装kubeadm kubelet kubectl
[root@master ~]# yum install -y kubelet-1.20.6 kubeadm-1.20.6 kubectl-1.20.6 [root@master ~]# systemctl enable kubelet && systemctl start kubelet
初始化节点
[root@master ~]# kubeadm init --kubernetes-version=1.20.6 --apiserver-advertise-address=192.168.64.120 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=SystemVerification2 注:--image-repository registry.aliyuncs.com/google_containers:手动指定仓库地址为registry.aliyuncs.com/google_containers。kubeadm默认从k8s.grc.io拉取镜像,但是k8s.gcr.io访问不到,所以需要指定从registry.aliyuncs.com/google_containers仓库拉取镜像

如图说明安装完成,按提示配置lubectl命令
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config kubeadm join 192.168.64.120:6443 --token raiypz.csl012prk39f39n4 \ --discovery-token-ca-cert-hash sha256:21eaf08d5c1673bfa2a83c40b4a2c3b6e2c003cc5b8444bea3448f7bbc95ec7c
#记录安装完成后的token,或者手动创建新的token
[root@master ~]# kubeadm token create --print-join-command
kubeadm join 192.168.64.120:6443 --token 2aofpj.siy2eclzvewe0kjq --discovery-token-ca-cert-hash sha256:21eaf08d5c1673bfa2a83c40b4a2c3b6e2c003cc5b8444bea3448f7bbc95ec7c
添加node节点
kubeadm join 192.168.64.120:6443 --token 2aofpj.siy2eclzvewe0kjq --discovery-token-ca-cert-hash sha256:21eaf08d5c1673bfa2a83c40b4a2c3b6e2c003cc5b8444bea3448f7bbc95ec7c
#添加节点报错:
[ERROR SystemVerification]: failed to parse kernel config: unable to load kernel module: "configs", output: "modprobe: FATAL: Module configs not found.\n", err: exit status 1
方法一、忽略该错误
添加 --ignore-preflight-errors=SystemVerification选项来忽略该错误,暂时无法判断使用该选项,后续会不会出现其他问题。
方法二、升级内核版本
将内核升级到5.13.7后未出现该问题,也不确定是不是内核版本的问题。
------------------------------------------------------------------------------------------------------
#[root@node01 ~]# kubectl get ndoe
The connection to the server localhost:8080 was refused - did you specify the right host or port?
#将kubectl命令添加环境变量即可
[root@node01 ~]# mkdir -p $HOME/.kube
[root@master ~]# scp /etc/kubernetes/admin.conf node01:$HOME/.kube/config
[root@node01 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
#查看集群状态notready,需要部署网络插件
[root@node02 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master NotReady control-plane,master 70m v1.20.6
node01 NotReady <none> 4m59s v1.20.6
node02 NotReady <none> 21s v1.20.6
安装网络插件calico
wget https://docs.projectcalico.org/manifests/calico.yaml kubectl apply -f calico.yaml
查看集群状态
kubectl get pod -n kube-system #待所有pod处于running后再次查看集群状态 [root@master ~]# kubectl get node NAME STATUS ROLES AGE VERSION master Ready control-plane,master 75m v1.20.6 node01 Ready <none> 9m47s v1.20.6 node02 Ready <none> 5m9s v1.20.6
五 测试集群
创建pod是否正常访问网络
#上传busybox-1-28.tar.gz至工作节点,导入镜像 [root@node01 ~]# docker load -i busybox-1-28.tar.gz [root@node02 ~]# docker load -i busybox-1-28.tar.gz [root@master ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh If you don't see a command prompt, try pressing enter. / # ping baidu.com PING baidu.com (220.181.38.148): 56 data bytes 64 bytes from 220.181.38.148: seq=0 ttl=127 time=28.326 ms #可以访问网络,说明calico安装正常了
部署tomcat服务
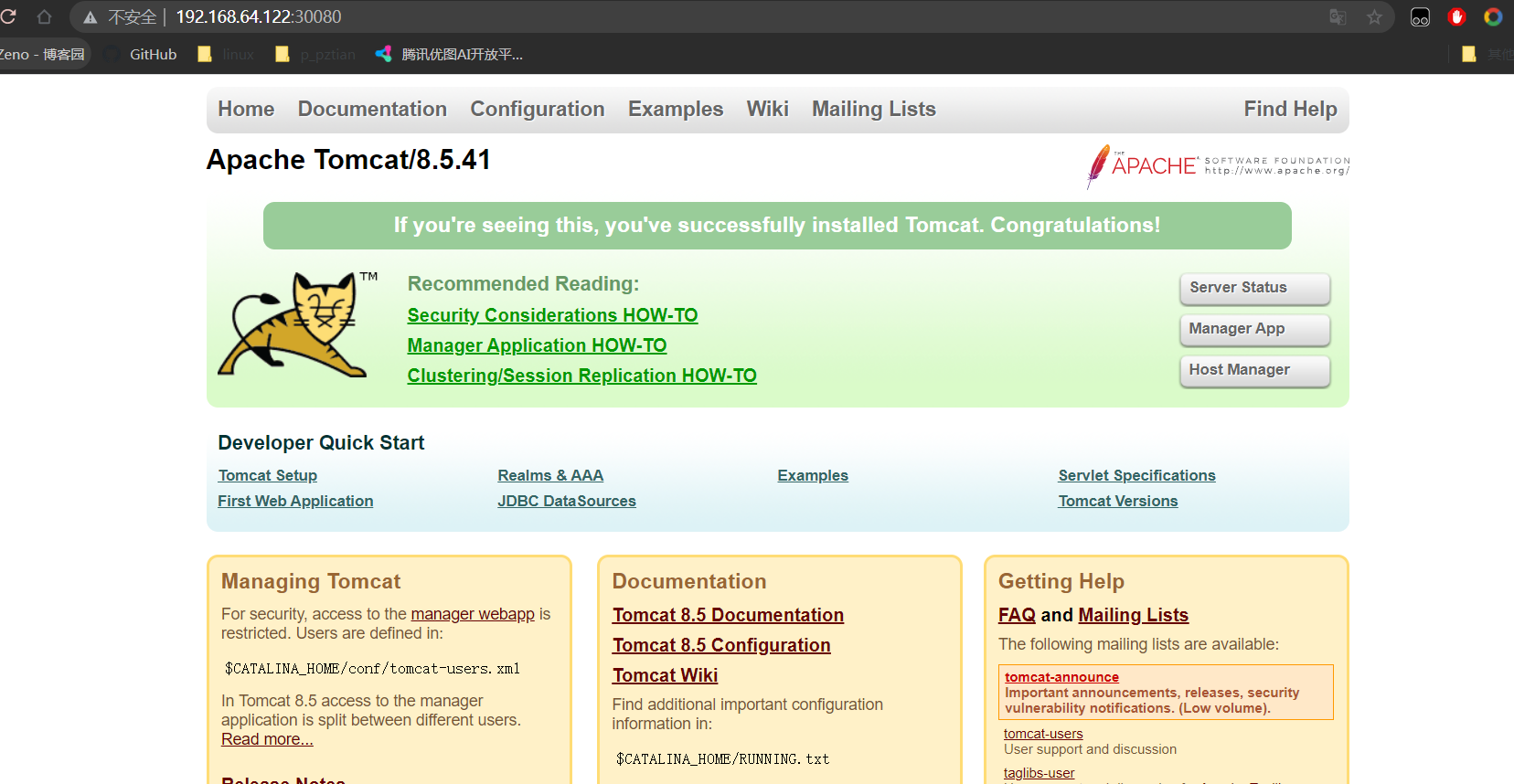
#在工作节点导入镜像 [root@node01 ~]# docker load -i tomcat.tar.gz [root@node02 ~]# docker load -i tomcat.tar.gz #在master节点上传tomcat.yaml,tomcat-service.yaml [root@master ~]# kubectl apply -f tomcat.yaml pod/demo-pod created [root@master ~]# kubectl get pod NAME READY STATUS RESTARTS AGE demo-pod 1/1 Running 0 5s [root@master ~]# kubectl apply -f tomcat-service.yaml service/tomcat created [root@master ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 87m tomcat NodePort 10.99.162.152 <none> 8080:30080/TCP 5s #浏览器访问任意节点的30080端口即可访问服务
测试coredns是否正常
[root@master ~]# kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh If you don't see a command prompt, try pressing enter. / # nslookup kubernetes.default.svc.cluster.local Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: kubernetes.default.svc.cluster.local Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local 10.96.0.10 就是我们coreDNS的clusterIP,说明coreDNS配置好了。 解析内部Service的名称,是通过coreDNS去解析的。 #注意: busybox要用指定的1.28版本,不能用最新版本,最新版本,nslookup会解析不到dns和ip
安装k8s可视化UI界面dashboard
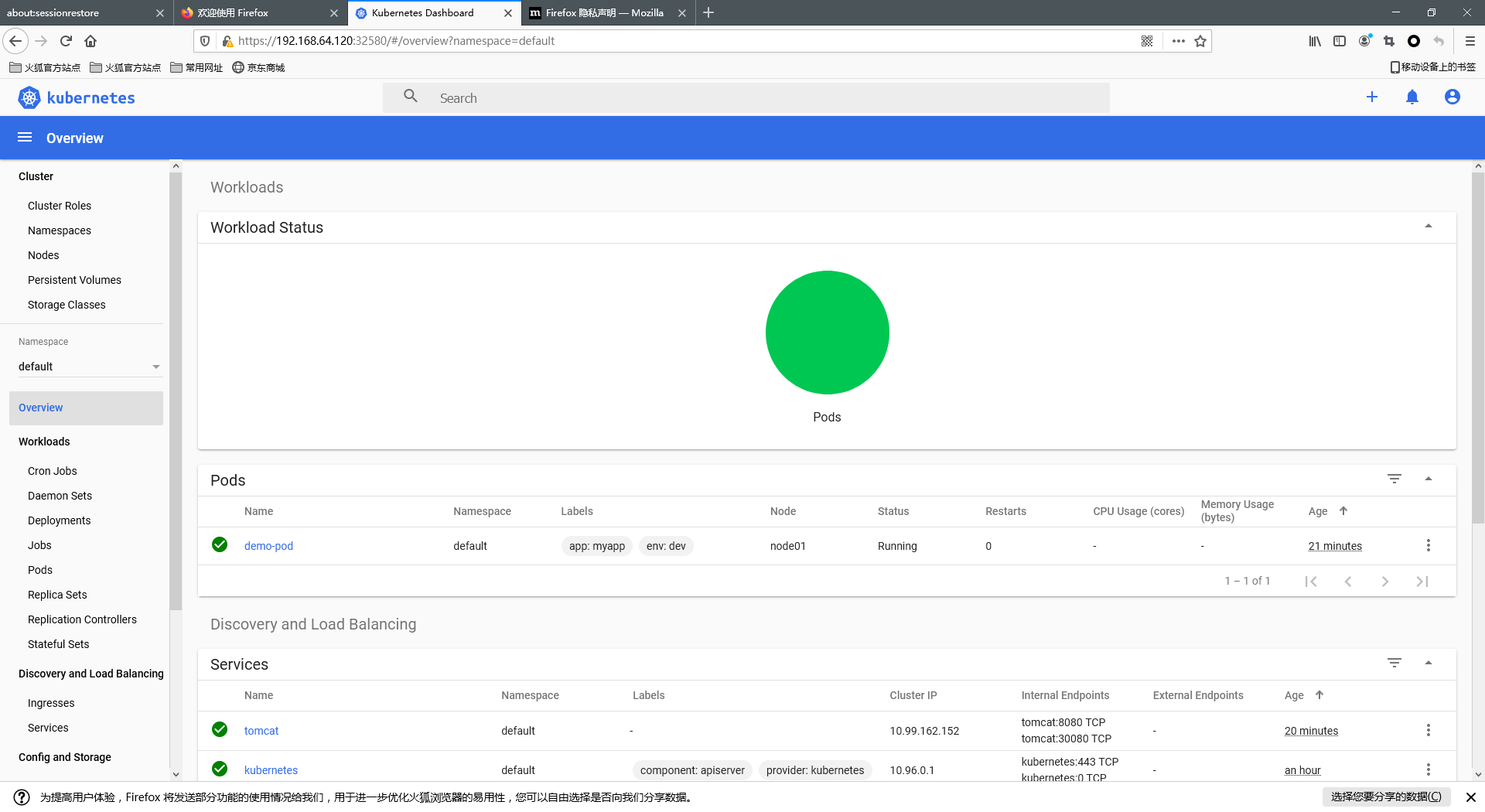
#工作节点导入镜相包dashboard_2_0_0.tar.gz 、 metrics-scrapter-1-0-1.tar.gz [root@node01 ~]# docker load -i dashboard_2_0_0.tar.gz [root@node01 ~]# docker load -i metrics-scrapter-1-0-1.tar.gz [root@node02 ~]# docker load -i dashboard_2_0_0.tar.gz [root@node02 ~]# docker load -i metrics-scrapter-1-0-1.tar.gz #上传kubernetes-dashboard.yaml至master节点创建服务 [root@master ~]# kubectl apply -f kubernetes-dashboard.yaml #查看dashboard的状态 [root@master ~]# kubectl get pods -n kubernetes-dashboard 显示如下,说明dashboard安装成功了 NAME READY STATUS RESTARTS AGE dashboard-metrics-scraper-7445d59dfd-s87gg 1/1 Running 0 68s kubernetes-dashboard-54f5b6dc4b-qjxzj 1/1 Running 0 68s #查看dashboard前端的service [root@master ~]# kubectl get svc -n kubernetes-dashboard 显示如下: NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.110.231.41 <none> 8000/TCP 81s kubernetes-dashboard ClusterIP 10.97.51.53 <none> 443/TCP 81s #修改service type类型变成NodePort [root@master ~]# kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard 把type: ClusterIP变成 type: NodePort,保存退出即可。 [root@xianchaomaster1 ~]# kubectl get svc -n kubernetes-dashboard NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.110.231.41 <none> 8000/TCP 2m9s kubernetes-dashboard NodePort 10.97.51.53 <none> 443:32580/TCP 2m9s 可看到service类型是NodePort,访问任何一个工作节点ip: 32728端口即可访问kubernetes dashboard,需要使用火狐浏览器访问如下地址: https://192.168.64.120:32580/

使用token令牌访问dashboard
#创建管理员token,具有查看任何空间的权限,可以管理所有资源对象 [root@master ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard clusterrolebinding.rbac.authorization.k8s.io/dashboard-cluster-admin created #查看名称中带有token的secret [root@master ~]# kubectl get secret -n kubernetes-dashboard NAME TYPE DATA AGE default-token-gnb58 kubernetes.io/service-account-token 3 8m29s kubernetes-dashboard-certs Opaque 0 8m29s kubernetes-dashboard-csrf Opaque 1 8m29s kubernetes-dashboard-key-holder Opaque 2 8m29s kubernetes-dashboard-token-8g9ks kubernetes.io/service-account-token 3 8m29s #获取token [root@master ~]# kubectl describe secret kubernetes-dashboard-token-8g9ks -n kubernetes-dashboard Name: kubernetes-dashboard-token-8g9ks Namespace: kubernetes-dashboard Labels: <none> Annotations: kubernetes.io/service-account.name: kubernetes-dashboard kubernetes.io/service-account.uid: 1bc35065-aacd-4a86-afea-12ebdd4d299a Type: kubernetes.io/service-account-token Data ==== token: eyJhbGciOiJSUzI1NiIsImtpZCI6Il9aOUgzbEttRFNzMDNTUTAtY3RJVExWcnN1X2F4WVBlVmpQV3E5S0p3UW8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC10b2tlbi04ZzlrcyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjFiYzM1MDY1LWFhY2QtNGE4Ni1hZmVhLTEyZWJkZDRkMjk5YSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.qvMCAhFWtRuGkBVXA41zFOGsHvStxuhgdyIzib1dxTdf5NUjhV8Ek8HQl4nct4-VSrLWL1MpqVNxAhaQbUa-01Z1usc4WKpDRBebux6xVdAPIaMXsqlm1LN1s1y9x4B5NtsvPhHLhOpwQgXFwX7EbAf0a8auTKeqR-nu8lzRxi0COQaLCzXSe93AqVwiCa7xvs4pb2ARpXZmGs_qxzQ_H2t3C5_auwLNdPGJxJsLATawY2wJGJr62qPXG_f2CZQB4QVo3kQ2WG2t1NFo5hZaYKRYwQqcYlKVLl50GyJ1xNdIvg3RP3zUWbs0W4zG0AUicFhFZVPv2Ia2N0gqgy50dw ca.crt: 1066 bytes namespace: 20 bytes #在浏览器中选择token登录,jiangtoken粘贴,点击sign in即登录
通过kubeconfig文件访问dashboard
[root@xianchaomaster1 ~]# cd /etc/kubernetes/pki 1、创建cluster集群 [root@xianchaomaster1 pki]# kubectl config set-cluster kubernetes --certificate-authority=./ca.crt --server="https://192.168.64.120:6443" --embed-certs=true --kubeconfig=/root/dashboard-admin.conf 2、创建credentials 创建credentials需要使用上面的kubernetes-dashboard-token-8g9ks对应的token信息 [root@xianchaomaster1 pki]# DEF_NS_ADMIN_TOKEN=$(kubectl get secret kubernetes-dashboard-token-8g9ks -n kubernetes-dashboard -o jsonpath={.data.token}|base64 -d) [root@xianchaomaster1 pki]# kubectl config set-credentials dashboard-admin --token=$DEF_NS_ADMIN_TOKEN --kubeconfig=/root/dashboard-admin.conf 3、创建context [root@xianchaomaster1 pki]# kubectl config set-context dashboard-admin@kubernetes --cluster=kubernetes --user=dashboard-admin --kubeconfig=/root/dashboard-admin.conf 4、切换context的current-context是dashboard-admin@kubernetes [root@xianchaomaster1 pki]# kubectl config use-context dashboard-admin@kubernetes --kubeconfig=/root/dashboard-admin.conf 5、把kubeconfig文件/root/dashboard-admin.conf复制到桌面浏览器访问时使用kubeconfig认证,把刚才的dashboard-admin.conf导入到web界面,那么就可以登陆了
通过kubernetes-dashboard创建容器
#镜相包传至node节点,导入镜像 [root@node01 ~]# docker load -i nginx.tar.gz [root@node02 ~]# docker load -i nginx.tar.gz
打开kubernetes的dashboard界面(https://192.168.64.120:32580/
),点开右上角红色箭头标注的 “+”,如下图所示

选择Create from form
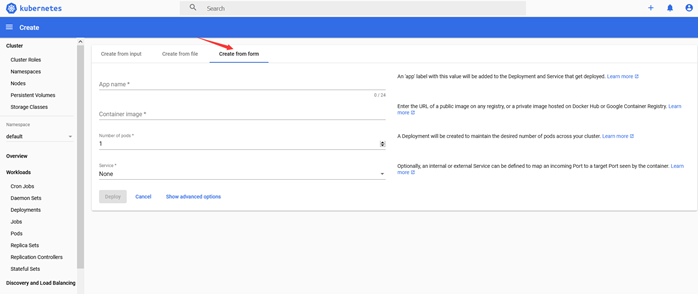
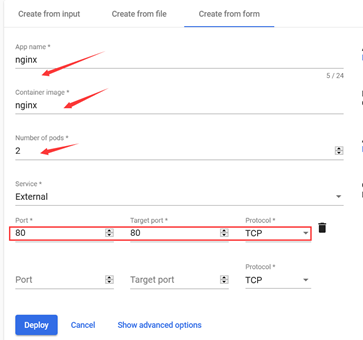
填写之后点击Deploy即可完成Pod的创建,在dashboard的左侧选择Services

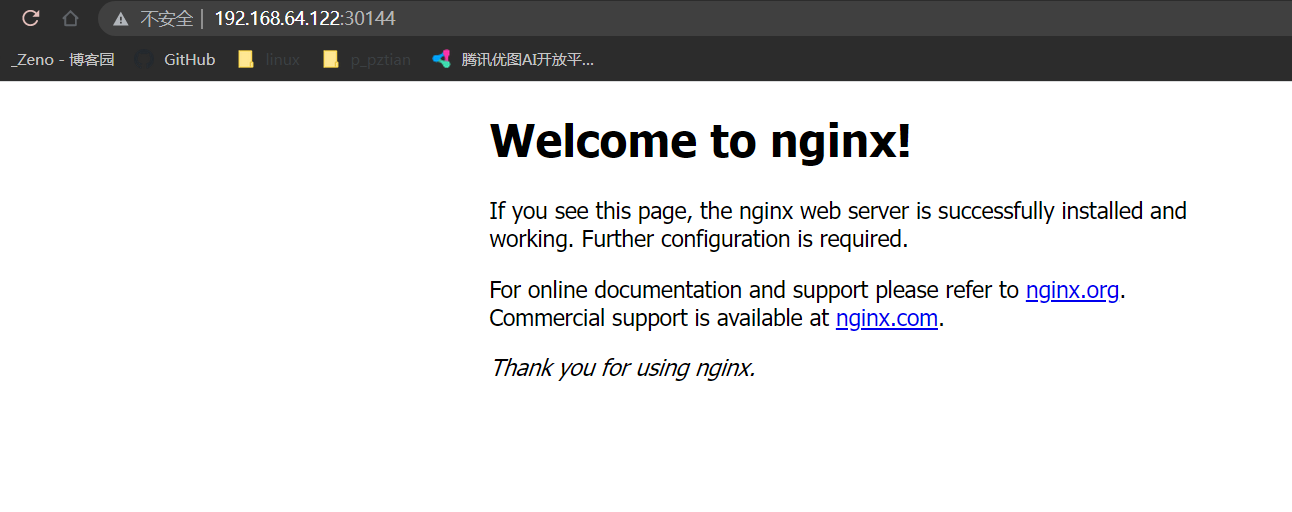
可看到刚才创建的nginx的service在宿主机映射的端口是31135,在浏览器访问:192.168.64.120:30144
注:
应用名称:nginx
容器镜像:nginx
pod数量:2
service: external 外部网络
port:8-
targetport:80
注:表单中创建pod时没有创建nodeport的选项,会自动创建在30000+以上的端口。
关于port、targetport、nodeport的说明:
nodeport是集群外流量访问集群内服务的端口,比如客户访问nginx,apache,
port是集群内的pod互相通信用的端口类型,比如nginx访问mysql,而mysql是不需要让客户访问到的,port是service的的端口
targetport目标端口,也就是最终端口,也就是pod的端口。
安装metrics-server组件
metrics-server是一个集群范围内的资源数据集和工具,同样的,metrics-server也只是显示数据,并不提供数据存储服务,主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标,metric-server收集数据给k8s集群内使用,如kubectl,hpa,scheduler等 #部署metrics-server组件 #把离线镜像压缩包上传到k8s的各个节点,按如下方法手动解压 [root@master ~]# docker load -i addon.tar.gz [root@master ~]# docker load -i metrics-server-amd64-0-3-6.tar.gz #部署metrics-server服务 #在/etc/kubernetes/manifests里面改一下apiserver的配置 注意:这个是k8s在1.17的新特性,如果是1.16版本的可以不用添加,1.17以后要添加。这个参数的作用是Aggregation允许在不修改Kubernetes核心代码的同时扩展Kubernetes API。 vim /etc/kubernetes/manifests/kube-apiserver.yaml 增加如下内容: - command xxxxxx - --enable-aggregator-routing=true xxxxxx #重新更新apiserver配置 [root@master ~]# kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml [root@master ~]# kubectl get pods -n kube-system #删除状态异常的api [root@master ~]# kubectl delete pod -n kube-system kube-apiserver #创建服务 [root@master ~]# kubectl apply -f metrics.yaml [root@master ~]# kubectl get pod -n kube-system |grep metrics metrics-server-6595f875d6-fzbzt 2/2 Running 0 18s
测试kubectl top命令
[root@master ~]# kubectl top pods -n kube-system NAME CPU(cores) MEMORY(bytes) calico-kube-controllers-6949477b58-9dmfm 2m 14Mi calico-node-c7sn5 33m 89Mi calico-node-pz9ds 38m 71Mi calico-node-trrcx 39m 74Mi coredns-7f89b7bc75-lgp5q 3m 18Mi coredns-7f89b7bc75-r69tf 3m 8Mi etcd-master 14m 58Mi kube-apiserver-master 54m 394Mi kube-controller-manager-master 20m 50Mi kube-proxy-56bpr 1m 13Mi kube-proxy-b87kn 1m 16Mi kube-proxy-bc2gj 1m 16Mi kube-scheduler-master 3m 16Mi metrics-server-6595f875d6-fzbzt 2m 17Mi [root@master ~]# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% master 166m 8% 1283Mi 68% node01 88m 4% 974Mi 51% node02 97m 4% 933Mi 49%
把scheduler、controller-manager端口变成物理机可以监听的端口
[root@master]# kubectl get cs NAME STATUS MESSAGE ERROR controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused etcd-0 Healthy {"health":"true"} 默认在1.19之后10252和10251都是绑定在127的,如果想要通过prometheus监控,会采集不到数据,所以可以把端口绑定到物理机 可按如下方法处理: vim /etc/kubernetes/manifests/kube-scheduler.yaml 修改如下内容: 把--bind-address=127.0.0.1变成--bind-address=192.168.64.120 把httpGet:字段下的hosts由127.0.0.1变成192.168.64.120 把—port=0删除 #注意:192.168.64.120是k8s的控制节点master的ip vim /etc/kubernetes/manifests/kube-controller-manager.yaml 把--bind-address=127.0.0.1变成--bind-address=192.168.64.120 把httpGet:字段下的hosts由127.0.0.1变成192.168.64.120 把—port=0删除 修改之后在k8s各个节点重启下kubelet systemctl restart kubelet [root@xianchaomaster1 prometheus]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} ss -antulp | grep :10251 ss -antulp | grep :10252


