

Linux进程的创建函数fork()及其fork内核实现解析
进程的创建之fork()
Linux系统下,进程可以调用fork函数来创建新的进程。调用进程为父进程,被创建的进程为子进程。
fork函数的接口定义如下:
#include <unistd.h>
pid_t fork(void);
与普通函数不同,fork函数会返回两次。一般说来,创建两个完全相同的进程并没有太多的价值。大部分情况下,父子进程会执行不同的代码分支。fork函数的返回值就成了区分父子进程的关键。fork函数向子进程返回0,并将子进程的进程ID返给父进程。当然了,如果fork失败,该函数则返回-1,并设置errno。
从2.6.24起,Linux采用完全公平调度(Completely Fair Scheduler,CFS)。用户创建的普通进程,都采用CFS调度策略。对于CFS调度策略,procfs提供了如下控制选项:
/proc/sys/kernel/sched_child_runs_first
该值默认是0,表示父进程优先获得调度。如果将该值改成1,那么子进程会优先获得调度。
fork之后父子进程的内存关系
fork之后的子进程完全拷贝了父进程的地址空间,包括栈、堆、代码段等。通过下面的示例代码,我们一起来查看父子进程的内存关系:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
#include <sys/types.h>
#include <wait.h>
int g_int = 1;//数据段的全局变量
int main()
{
int local_int = 1;//栈上的局部变量
int *malloc_int = malloc(sizeof(int));//通过malloc动态分配在堆上的变量
*malloc_int = 1;
pid_t pid = fork();
if(pid == 0) /*子进程*/
{
local_int = 0;
g_int = 0;
*malloc_int = 0;
fprintf(stderr,"[CHILD ] child change local global malloc value to 0\n");
free(malloc_int);
sleep(10);
fprintf(stderr,"[CHILD ] child exit\n");
exit(0);
}
else if(pid < 0)
{
printf("fork failed (%s)",strerror(errno));
return 1;
}
fprintf(stderr,"[PARENT] wait child exit\n");
waitpid(pid,NULL,0);
fprintf(stderr,"[PARENT] child have exit\n");
printf("[PARENT] g_int = %d\n",g_int);
printf("[PARENT] local_int = %d\n",local_int);
printf("[PARENT] malloc_int = %d\n",local_int);
free(malloc_int);
return 0;
}
这里刻意定义了三个变量,一个是位于数据段的全局变量,一个是位于栈上的局部变量,还有一个是通过malloc动态分配位于堆上的变量,三者的初始值都是1。然后调用fork创建子进程,子进程将三个变量的值都改成了0。
按照fork的语义,子进程完全拷贝了父进程的数据段、栈和堆上的内存,如果父子进程对相应的数据进行修改,那么两个进程是并行不悖、互不影响的。因此,在上面示例代码中,尽管子进程将三个变量的值都改成了0,对父进程而言这三个值都没有变化,仍然是1,代码的输出也证实了这一点。
[PARENT] wait child exit
[CHILD ] child change local global malloc value to 0
[CHILD ] child exit
[PARENT] child have exit
[PARENT] g_int = 1
[PARENT] local_int = 1
[PARENT] malloc_int = 1
前文提到过,子进程和父进程执行一模一样的代码的情形比较少见。Linux提供了execve系统调用,构建在该系统调用之上,glibc提供了exec系列函数。这个系列函数会丢弃现存的程序代码段,并构建新的数据段、栈及堆。调用fork之后,子进程几乎总是通过调用exec系列函数,来执行新的程序。
在这种背景下,fork时子进程完全拷贝父进程的数据段、栈和堆的做法是不明智的,因为接下来的exec系列函数会毫不留情地抛弃刚刚辛苦拷贝的内存。为了解决这个问题,Linux引入了写时拷贝(copy-on-write)的技术。
写时拷贝是指子进程的页表项指向与父进程相同的物理内存页,这样只拷贝父进程的页表项就可以了,当然要把这些页面标记成只读(如图4-4所示)。如果父子进程都不修改内存的内容,大家便相安无事,共用一份物理内存页。但是一旦父子进程中有任何一方尝试修改,就会引发缺页异常(page fault)。此时,内核会尝试为该页面创建一个新的物理页面,并将内容真正地复制到新的物理页面中,让父子进程真正地各自拥有自己的物理内存页,然后将页表中相应的表项标记为可写。
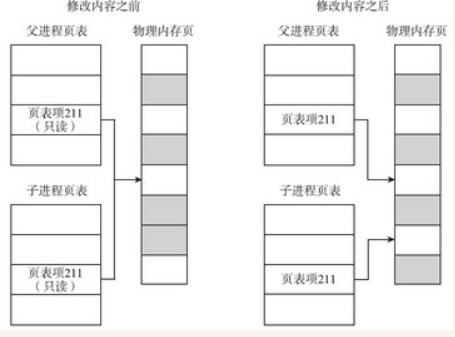
从上面的描述可以看出,对于没有修改的页面,内核并没有真正地复制物理内存页,仅仅是复制了父进程的页表。这种机制的引入提升了fork的性能,从而使内核可以快速地创建一个新的进程。
查看下copy_one_pte函数中有如下代码:
/*如果是写时拷贝, 那么无论是初始页表, 还是拷贝的页表, 都设置了写保护
*后面无论父子进程, 修改页表对应位置的内存时, 都会触发page fault
*/
if (is_cow_mapping(vm_flags)) {
ptep_set_wrprotect(src_mm, addr, src_pte);//设置为写保护
pte = pte_wrprotect(pte);
}
该代码将页表设置成写保护,父子进程中任意一个进程尝试修改写保护的页面时,都会引发缺页中断,内核会走向do_wp_page函数,该函数会负责创建副本,即真正的拷贝。
写时拷贝技术极大地提升了fork的性能,在一定程度上让vfork成为了鸡肋。
父子进程共用了一套文件偏移量
文件描述符还有一个文件描述符标志(file descriptor flag)。目前只定义了一个标志位:FD_CLOSEXEC,这是close_on_exec标志位。细心阅读open函数手册也会发现,open函数也有一个类似的标志位,即O_CLOSEXEC,该标志位也是用于设置文件描述符标志的。
那么这个标志位到底有什么作用呢?如果文件描述符中将这个标志位置位,那么调用exec时会自动关闭对应的文件。
可是为什么需要这个标志位呢?主要是出于安全的考虑。
对于fork之后子进程执行exec这种场景,如果子进程可以操作父进程打开的文件,就会带来严重的安全隐患。一般来讲,调用exec的子进程时,因为它.会另起炉灶,因此父进程打开的文件描述符也应该一并关闭,但事实上内核并没有主动这样做。试想如下场景,Webserver首先以root权限启动,打开只有拥有root权限才能打开的端口和日志等文件,再降到普通用户,fork出一些worker进程,在进程中进行解析脚本、写日志、输出结果等操作。由于子进程完全可以操作父进程打开的文件,因此子进程中的脚本只要继续操作这些文件描述符,就能越权操作root用户才能操作的文件。
为了解决这个问题,Linux引入了close on exec机制。设置了FD_CLOSEXEC标志位的文件,在子进程调用exec家族函数时会将相应的文件关闭。而设置该标志位的方法有两种:
·open时,带上O_CLOSEXEC标志位。
·open时如果未设置,那就在后面调用fcntl函数的F_SETFD操作来设置。
建议使用第一种方法。原因是第二种方法在某些时序条件下并不那么绝对的安全。考虑图4-7的场景:Thread 1还没来得及将FD_CLOSEXEC置位,由于Thread 2已经执行过fork,这时候fork出来的子进程就不会关闭相应的文件。尽管Thread1后来调用了fcntl的F_SETFD操作,但是为时已晚,文件已经泄露了。
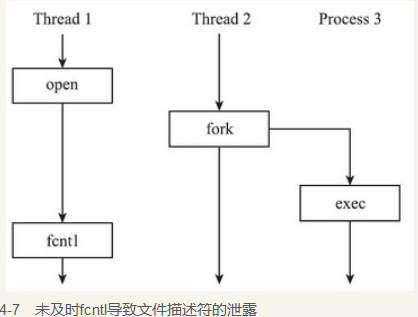
注意 图4-7中,多线程程序执行了fork,仅仅是为了示意,实际中并不鼓励这种做法。正相反,这种做法是十分危险的。多线程程序不应该调用fork来创建子进程,第8章会分析具体原因。
前面提到,执行fork时,子进程会获取父进程所有文件描述符的副本,但是测试结果表明,父子进程共享了文件的很多属性。这到底是怎么回事?让我们深入内核一探究竟。
在内核的进程描述符task_struct结构体中,与打开文件相关的变量如下所示:
struct task_struct {
...struct files_struct *files;...
}
调用fork时,内核会在copy_files函数中处理拷贝父进程打开的文件的相关事宜:
static int copy_files(unsigned long clone_flags,
struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
oldf = current->files;//获取父进程的文件结构体
if (!oldf)
goto out;
/*创建线程和vfork, 都不用复制父进程的文件描述符, 增加引用计数即可*/
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
/*对于fork而言, 需要复制父进程的文件描述符*/
newf = dup_fd(oldf, &error); //复制一份文件描述符
if (!newf)
goto out;
tsk->files = newf;
error = 0;
out:
return error;
}
CLONE_FILES标志位用来控制是否共享父进程的文件描述符。如果该标志位置位,则表示不必费劲复制一份父进程的文件描述符了,增加引用计数,直接共用一份就可以了。对于vfork函数和创建线程的pthread_create函数来说都是如此。但是fork函数却不同,调用fork函数时,该标志位为0,表示需要为子进程拷贝一份父进程的文件描述符。文件描述符的拷贝是通过内核的dup_fd函数来完成的。
struct files_struct *dup_fd(struct files_struct *oldf,
int *errorp)
{
struct files_struct *newf;
struct file **old_fds, **new_fds;
int open_files, size, i;
struct fdtable *old_fdt, *new_fdt;
*errorp = -ENOMEM;
newf = kmem_cache_alloc(files_cachep, GFP_KERNEL);
if (!newf)
goto out;
dup_fd函数首先会给子进程分配一个file_struct结构体,然后做一些赋值操作。这个结构体是进程描述符中与打开文件相关的数据结构,每一个打开的文件都会记录在该结构体中。其定义代码如下:
struct files_struct {
atomic_t count;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct fdtable //文件描述符表
{
unsigned int max_fds;
struct file __rcu **fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
struct rcu_head rcu;
struct fdtable *next;
};
struct embedded_fd_set {
unsigned long fds_bits[1];
};
初看之下struct fdtable的内容与struct files_struct的内容有颇多重复之处,包括close_on_exec文件描述符位图、打开文件描述符位图及file指针数组等,但事实上并非如此。struct files_struct中的成员是相应数据结构的实例,而struct fdtable中的成员是相应的指针。
Linux系统假设大多数的进程打开的文件不会太多。于是Linux选择了一个long类型的位数(32位系统下为32位,64位系统下为64位)作为经验值。
以64位系统为例,file_struct结构体自带了可以容纳64个struct file类型指针的数组fd_array,也自带了两个大小为64的位图,其中open_fds_init位图用于记录文件的打开情况,close_on_exec_init位图用于记录文件描述符的FD_CLOSEXCE标志位是否置位。只要进程打开的文件个数小于64,file_struct结构体自带的指针数组和两个位图就足以满足需要。因此在分配了file_struct结构体后,内核会初始化file_struct自带的fdtable,代码如下所示:
atomic_set(&newf->count, 1);
spin_lock_init(&newf->file_lock);
newf->next_fd = 0;
new_fdt = &newf->fdtab;
new_fdt->max_fds = NR_OPEN_DEFAULT;
new_fdt->close_on_exec = (fd_set *)&newf->close_on_exec_init;
new_fdt->open_fds = (fd_set *)&newf->open_fds_init;
new_fdt->fd = &newf->fd_array[0];
new_fdt->next = NULL;
初始化之后,子进程的file_struct的情况如图4-8所示。注意,此时file_struct结构体中的fdt指针并未指向file_struct自带的struct fdtable类型的fdtab变量。原因很简单,因为此时内核还没有检查父进程打开文件的个数,因此并不确定自带的结构体能否满足需要。

接下来,内核会检查父进程打开文件的个数。如果父进程打开的文件超过了64个,struct files_struct中自带的数组和位图就不能满足需要了。这种情况下内核会分配一个新的struct fdtable,代妈如下:
spin_lock(&oldf->file_lock);
old_fdt = files_fdtable(oldf);
open_files = count_open_files(old_fdt);
/*如果父进程打开文件的个数超过NR_OPEN_DEFAULT*/
while (unlikely(open_files > new_fdt->max_fds)) {
spin_unlock(&oldf->file_lock); /* 如果不是自带的fdtable而是曾经分配的fdtable, 则需要先释放*/
if (new_fdt != &newf->fdtab)
__free_fdtable(new_fdt);
/*创建新的fdtable*/
new_fdt = alloc_fdtable(open_files - 1);
if (!new_fdt) {
*errorp = -ENOMEM;
goto out_release;
}
/*如果超出了系统限制, 则返回EMFILE*/
if (unlikely(new_fdt->max_fds < open_files)) {
__free_fdtable(new_fdt);
*errorp = -EMFILE;
goto out_release;
}
spin_lock(&oldf->file_lock);
old_fdt = files_fdtable(oldf);
open_files = count_open_files(old_fdt);
}
alloc_fdtable所做的事情,不过是分配fdtable结构体本身,以及分配一个指针数组和两个位图。分配之前会根据父进程打开文件的数目,计算出一个合理的值nr,以确保分配的数组和位图能够满足需要。
无论是使用file_struct结构体自带的fdtable,还是使用alloc_fdtable分配的fdtable,接下来要做的事情都一样,即将父进程的两个位图信息和打开文件的struct file类型指针拷贝到子进程的对应数据结构中,代码如下:
old_fds = old_fdt->fd;
memset(&new_fdt->open_fds->fds_bits[start], 0, left);
memset(&new_fdt->close_on_exec->fds_bits[start], 0, left);
}
rcu_assign_pointer(newf->fdt, new_fdt);
return newf;
out_release:
kmem_cache_free(files_cachep, newf);
out:
return NULL;
}
通过对上述流程的梳理,不难看出,父子进程之间拷贝的是struct file的指针,而不是struct file的实例,父子进程的struct file类型指针,都指向同一个struct file实例。fork之后,父子进程的文件描述符关系如图4-10所示。
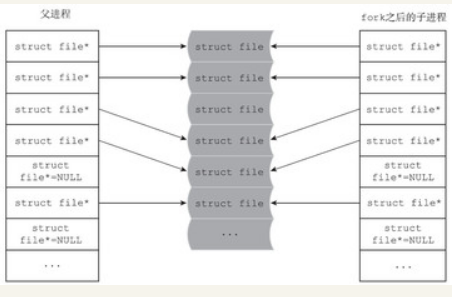
进程的创建之vfork()
在早期的实现中,fork没有实现写时拷贝机制,而是直接对父进程的数据段、堆和栈进行完全拷贝,效率十分低下。很多程序在fork一个子进程后,会紧接着执行exec家族函数,这更是一种浪费。所以BSD引入了vfork。既然fork之后会执行exec函数,拷贝父进程的内存数据就变成了一种无意义的行为,所以引入的vfork压根就不会拷贝父进程的内存数据,而是直接共享。再后来Linux引入了写时拷贝的机制,其效率提高了很多,这样一来,vfork其实就可以退出历史舞台了。除了一些需要将性能优化到极致的场景,大部分情况下不需要再使用vfork函数了。
vfork会创建一个子进程,该子进程会共享父进程的内存数据,而且系统将保证子进程先于父进程获得调度。子进程也会共享父进程的地址空间,而父进程将被一直挂起,直到子进程退出或执行exec。
注意,vfork之后,子进程如果返回,则不要调用return,而应该使用_exit函数。如果使用return,就会出现诡异的错误。请看下面的示例代码:
#include<stdio.h>
#include <stdlib.h>
#include <unistd.h>
int glob = 88 ;
int main(void) {
int var;
var = 88;
pid_t pid;
if ((pid = vfork()) < 0) {
printf("vfork error");
exit(-1);
} else if (pid == 0) { /* 子进程 */
var++;
glob++;
return 0;
}printf("pid=%d, glob=%d, var=%d\n",getpid(), glob, var);
return 0;
}
调用子进程,如果使用return返回,就意味着main函数返回了,因为栈是父子进程共享的,所以程序的函数栈发生了变化。main函数return之后,通常会调用exit系的函数,父进程收到子进程的exit之后,就会开始从vfork返回,但是这时整个main函数的栈都已经不复存在了,所以父进程压根无法执行。于是会返回一个诡异的栈地址,对于在某些内核版本中,进程会直接报栈错误然后退出,但是在某些内核版本中,有可能就会再次进出main,于是进入一个无限循环,直到vfork返回错误。笔者的Ubuntu版本就是后者。返回。一般来说,vfork创建的子进程会执行exec,执行完exec后应该调用_exit,注意是_exit而不是exit。因为exit会导致父进程stdio缓冲区的冲刷和关闭。我们会在后面讲述exit和_exit的区别。
标签:
Linux环境应用到内核



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现