堆排序
先介绍下堆这种结构,堆就是一颗完全二叉树,除了树的最底层,该树是完全充满的。堆这种结构用数组来实现,二叉树中的每一个节点,都对应数组中的一个元素,一个父节点可以根据自身节点在数组中的索引,直接算出子节点在数组中的索引,要注意在访问子节点的时候要判断子节点的索引是否越界。
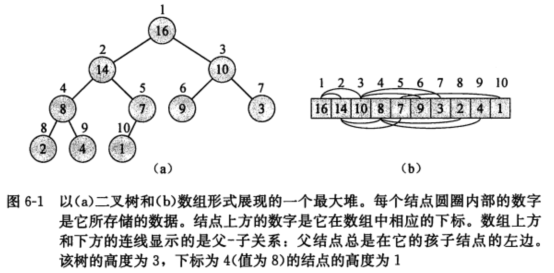
(图片截取自《算法导论》)
堆分两种,最大堆和最小堆,最大堆就是父节点的值总比子节点的值大,最小堆则是父节点值比子节点值要小。如果父节点在数组的索引为i,则左子节点的索引为i * 2,右子节点索引为i *2 + 1,一个节点总数为N的完全二叉树,其高度为lgN。
堆排序即然用到堆,那就要先构建最大堆或最小堆,最后排序。最大堆和最小堆都能排序,但是只有最大堆可以原址排序,最小堆则必须使用额外的空间来存储排序结果,所以堆排序一般都是使用最大堆排序。
完全二叉树有一个重要性质,那就是如果二叉树有N个节点,那此树的叶节点的数据索引为N/2,N/2+2,N/2+3,... ...., N - 1,一共N/2个。比如上图的树中一共有10个节点,那它的树节点在数组中的索引为 5,6,7,8,9,一共5个。如果N为偶数,那叶子节点的个数为N/2个,如果N为奇数,那叶子节点的个数就为(N+1)/2个,可以统一写为(N+1)/2个。
先讨论对某数组索引为i的节点维护最大堆性质,因为父节点必须大于子节点,所以把父节点的值分别与两个子节点进行比较,在子节点中选择最大的节点,如果此节点比父节点要大,则把此节点与父节点的值交换,交换后,子节点之下可能又不满足最大堆的性质,所以需要一直往下进行此过程,直到叶子节点,这是一个逐级下降处理过程。
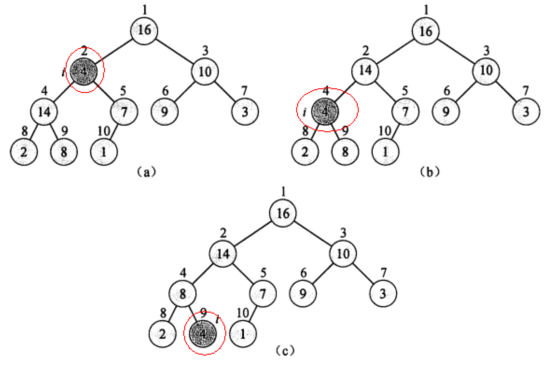
(图片截取自《算法导论》)
如上图a,对索引为1,值为4的节点进行最大堆性质处理,它比子节点14的值小,则交换值,如图b,交换后,其值又比新的子节点8要小,继续交换,直到到达叶子节点。以上就是一个逐级下降处理过程。代码如下:
1 void MaxHeapfy(int* pArr, int i, int size) { 2 int l = i << 1; 3 int r = l + 1; 4 int max = i; 5 6 if (l < size && pArr[l] > pArr[max]) 7 max = l; 8 if (r < size && pArr[r] > pArr[max]) 9 max = r; 10 if (max != i) { 11 Swap(pArr + i, pArr + max); 12 MaxHeapfy(pArr, max, size); 13 } 14 }
建堆则是一个自底向上的过程,每个叶节点就是以自身为根节点的子树,它们没有叶节点,所以本身就满足最大堆性质,无需对它们进行处理,所以从N/2-1个节点,也就是非叶子节点开始处理。对每个非叶子节点进行最大化堆处理,一直执行到根节点,就完成了最大堆的够建,代码很简单。
1 void MakeMaxHeap(int* pArr, int size) { 2 int h = size / 2; 3 for (int i = h - 1; i >= 0;--i) 4 { 5 MaxHeapfy(pArr, i, size); 6 } 7 }
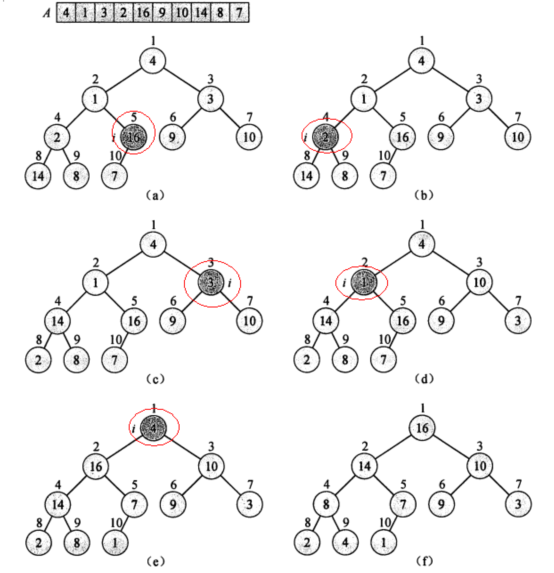
(图片截取自《算法导论》)
上图显示了将数组A够建为最大堆的过程.
堆排序就简单了,只需要在最大堆的基础上,把第一个元素拷贝到数组末尾,然后数组的size-1,然后对根节点进行最大堆性质维护,维护完成后,根节点又是新的子堆的最大值,这样反复进行,直到子堆大小为1则结束,数组就是从小到大排序的了.
1 void HeapSort(int* pArr, int size) { 2 Swap(pArr + size - 1, pArr); 3 int size = size - 1; 4 for (int i = size - 2; i >= 0; --i) { 5 MaxHeapfy(pArr, 0, size); 6 Swap(pArr + i, pArr); 7 size = size - 1; 8 } 9 }
了解了最大堆,最小堆就简单了,可以思考下为什么最小堆不能原址排序,而需要额外空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号