
作业7-逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
增大数据量,正则化(L1,L2),丢弃法Dropout(把其中的一些神经元去掉只用部分神经元去构建神经网络),优化模型,一般是模型过于简单无法描述样本的特性;
如果我们要在训练数据上表现良好,最为直接的方法就是要在足够大的模型空间中挑 选模型,否则如果模型空间很小,就不存在能够拟合数据很好的模型,而正则化就是控制模型空间的一种办法。
2.用logiftic回归来进行实践操作,数据不限。
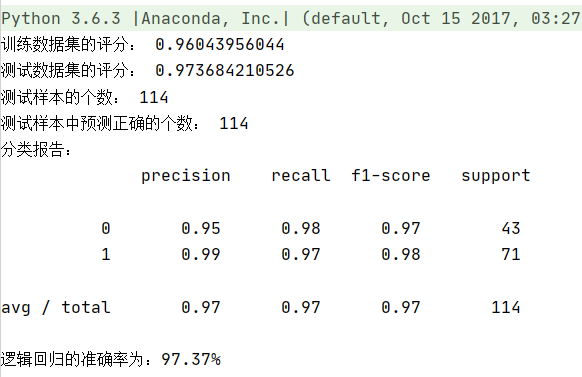
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report import numpy as np cancer = load_breast_cancer() # 载入数据 X = cancer.data # 数据 y = cancer.target # 是否患病 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 划分训练集和测试集 model = LogisticRegression() # 模型的构建 model.fit(X_train, y_train) # 模型的训练 print('训练数据集的评分:', model.score(X_train, y_train)) print('测试数据集的评分:', model.score(X_test, y_test)) # 样本预测 y_pre = model.predict(X_test) print('测试样本的个数:', y_test.shape[0]) print('测试样本预测正确的个数:', np.equal(y_pre, y_test).shape[0]) print('分类报告:\n', classification_report(y_test, y_pre)) print('逻辑回归准确率为:{0:.2f}%'.format(model.score(X_test, y_test)*100))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号