HBase单机安装及Phoenix JDBC连接
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库,它是横向扩展的。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
HBase提供对数据的随机实时读/写访问,可以直接HBase存储HDFS数据。
1、准备
-
必须
JDK1.8+ -
下载
hbase前,检查本机的Hadoop版本(HBase文档搜索Hadoop version查找):
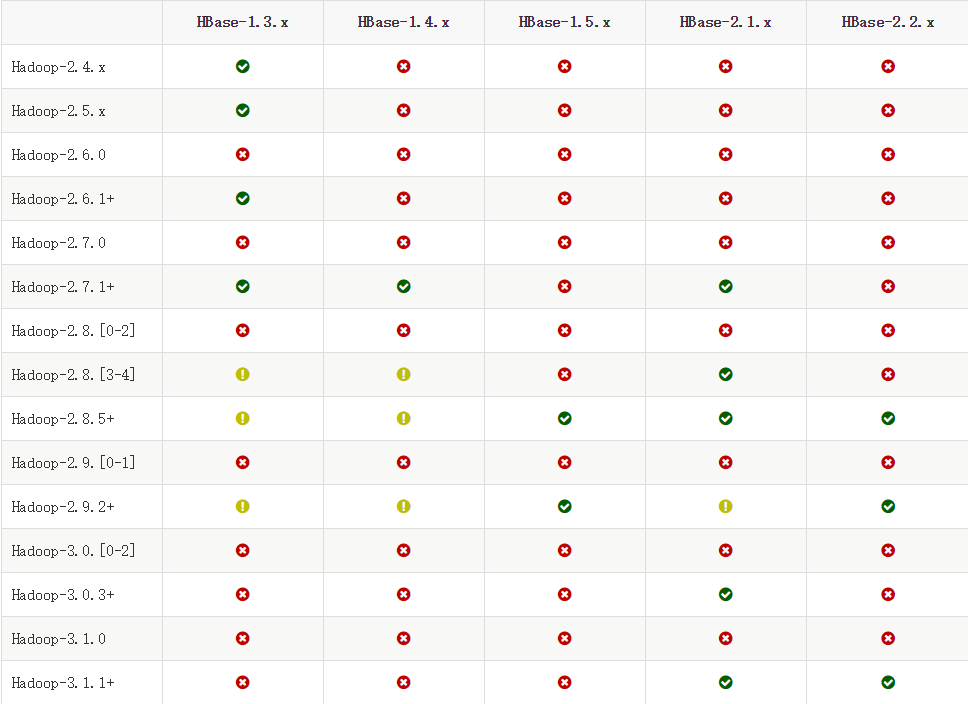
我这里本地安装的Hadoop版本为2.6,所以使用的HBase版本为HBase-1.3.6。
-
下载解压:
$ tar -xvf hbase-1.3.6.tar $ pwd /root/hbase-1.3.6 -
修改
conf/hbase-env.sh文件,设置JAVA_HOME变量export JAVA_HOME=/usr/local/jdk1.8.0_172如果不使用自带的
zookeeper,还需要设置:-
conf/hbase-env.sh:export HBASE_MANAGES_ZK=false -
conf/hbase-site.xml:<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>避免
HBase管理自己的ZooKeeper。
-
2、单机模式
单机运行模式提供了一种最简单运行方式来方便开发人员在单机模式下开发调试。使用起来也非常简单。
2.1、修改 conf/hbase-site.xml 文件
- 使用
hbase.rootdir参数来设置hbase保存数据的路径。这里使用file://表明是使用的本地目录。也可以使用Hadoop的hdfs://来使用分布式文件系统。 - 设置
zookeeper数据保存路径。
完整文件内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///root/hbase-1.3.6/data/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/root/hbase-1.3.6/data/zookeeper</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
2.2、运行 hbase
使用下面的命令启动 hbase:
$ bin/start-hbase.sh
启动完成后,可以浏览器访问下面的地址来查看集群的详细信息:
http://192.168.0.192:16010/
3、测试
HBase是一个面向列的数据库,在表中它由行组成。表模式只定义列族,也就是键值对。一个表有多个列族,每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
集群启动后,我们可以使用hbase自带的shell来做一些数据库操作,如下:
# 启动 shell
$ bin/hbase shell
# 创建 user 表,其中包括两个族列 base 和 address
# base 列族用来保存用户基本信息,username 和 password
# address 列族用来保存家庭和办公地址
> create 'user', 'base', 'address'
Created table user
Took 1.2228 seconds
=> Hbase::Table - user
# 查看 user 表
> list 'user'
TABLE
user
1 row(s)
Took 0.0339 seconds
=> ["user"]
# 向 user 表添加数据
> put 'user', 'row1', 'base:username', 'user1'
> put 'user', 'row1', 'base:password', 'user1'
> put 'user', 'row1', 'address:home', 'user1 home'
> put 'user', 'row1', 'address:office', 'user1 office'
> put 'user', 'row2', 'base:username', 'user2'
> put 'user', 'row2', 'base:password', 'user2'
> put 'user', 'row2', 'address:home', 'user2 home'
> put 'user', 'row2', 'address:office', 'user2 office'
# 查询 user 表数据
0> scan 'user'
ROW COLUMN+CELL
row1 column=address:home, timestamp=1571706809228, value=user1 home
row1 column=address:office, timestamp=1571706829480, value=user1 office
row1 column=base:password, timestamp=1571706785474, value=user1
row1 column=base:username, timestamp=1571706769356, value=user1
row2 column=address:home, timestamp=1571706885491, value=user2 home
row2 column=address:office, timestamp=1571706904663, value=user2 office
row2 column=base:password, timestamp=1571706868152, value=user2
row2 column=base:username, timestamp=1571706851546, value=user2
# 查询 user 表的一行数据
> get 'user', 'row1'
COLUMN CELL
address:home timestamp=1571706809228, value=user1 home
address:office timestamp=1571706829480, value=user1 office
base:password timestamp=1571706785474, value=user1
base:username timestamp=1571706769356, value=user1
# 删除 user 表的一行数据
> delete 'user', 'row2'
# 删除 user 表, 需要先disable user 表,然后才能删除
> disable 'user'
> drop 'user'
4、phoenix使用
Apache Phoenix 是 HBase 的 SQL 驱动。Phoenix 使得 HBase 支持通过 JDBC 的方式进行访问,并将你的 SQL 查询转成 HBase 的扫描和相应的动作。
Phoenix版本与HBase版本兼容:
Phoenix 4.x与HBase 0.98、1.1、1.2、1.3和1.4兼容。Phoenix 5.x与HBase2.x兼容
4.1、phoenix安装连接
HBase-1.3.6则使用Phoenix 4.x版本,所以下载最新的Phoenix-4.14,解压后,复制目录下phoenix-4.14.3-HBase-1.3-server.jar 到hbase-1.3.6/lib目录下:
$ pwd
/root/phoenix-4.14
$ cp phoenix-4.14.3-HBase-1.3-server.jar ../hbase-1.3.6/lib
重新启动HBase:
$ cd hbase-1.3.6/bin
$ ./stop-hbase.sh
$ ./start-hbase.sh
启动Phoenix并连接:
$ cd phoenix-4.14/bin
$ ./sqlline.py localhost
./sqlline.py localhost指定连接localhost的zookeeper,默认端口为2181。
连接成功后:
Connected to: Phoenix (version 4.14)
Driver: PhoenixEmbeddedDriver (version 4.14)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
133/133 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:localhost>
查询所有表:

4.2、映射HBase已有表
本地安装好 Phoenix连接后,使用!talblse 命令列出所有表,发现 HBase 原有的表没有被列出来。而使用 Phoenix sql 的 CREATE 语句创建的一张新表,则可以通过 !tables 命令展示出来。
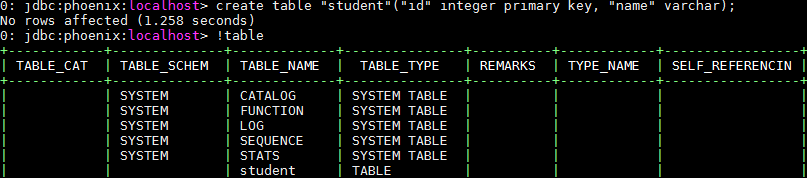
这是因为 Phoenix 无法自动识别 HBase 中原有的表,所以需要将 HBase 中已有的做映射,才能够被 Phoenix 识别并操作。说白了就是要需要告诉 Phoenix 一声 xx 表的 xx 列是主键,xx 列的数据类型。
而Phoenix要映射到HBase表有两种方法:
- 表映射
- 视图映射
以我们使用之前在HBase创建的user表:
hbase(main):028:0> scan 'user'
ROW COLUMN+CELL
row1 column=address:_0, timestamp=1571878635787, value=
row1 column=address:home, timestamp=1571878630632, value=user1 home
row1 column=address:office, timestamp=1571878635787, value=user1 office
row1 column=base:password, timestamp=1571878623205, value=user1
row1 column=base:username, timestamp=1571878615653, value=user1
row2 column=address:_0, timestamp=1571878659503, value=
row2 column=address:home, timestamp=1571878653783, value=user2 home
row2 column=address:office, timestamp=1571878659503, value=user2 office
row2 column=base:password, timestamp=1571878648083, value=user2
row2 column=base:username, timestamp=1571878641095, value=user2
进行映射:
-
表映射:
create table "user" ("ROW" varchar primary key, "address"."home" varchar, "address"."office" varchar, "base"."username" varchar, "base"."password" varchar) column_encoded_bytes=0;注意:
-
Phoneix对表名和列名区分大小写,如果不加双引号,则默认大写 -
表名要和
HBase的建立的表名要一致。 -
创建表时指定了属性(不让
Phoenix对column family进行编码)column_encoded_bytes=0。这是因为Phoneix版本在4.10之后,Phoenix对列的编码方式有所改变(官方文档地址),如果不指定,查不出列数据。根据官方文档的内容,“One can set the column mapping property only at the time of creating the table. ”,也就是说只有在创建表的时候才能够设置属性。如果在创建的时候没有设置,之后怎么去设置就不太清楚了,可能是无法改变,至少目前还没有找到相关方法。
-
删除该表时,同时也会删除
HBase中的表。
-
-
视图映射:
create view "user" ("ROW" varchar primary key, "address"."home" varchar, "address"."office" varchar, "base"."username" varchar, "base"."password" varchar);如果只做查询操作的话,建议大家使用视图映射的方式,而非表映射。因为:
- 上面提到的,在创建映射表时如果忘记设置属性(4.10版之后),那么想要删除映射表的话,
HBase中该表也会被删除,导致数据的丢失。 - 如果是用视图映射,则删除视图不会影响原有表的数据。
- 上面提到的,在创建映射表时如果忘记设置属性(4.10版之后),那么想要删除映射表的话,
4.3、客户端SQuirrel连接
使用客户端GUI与Phoenix进行交互,请下载并安装SQuirrel。由于Phoenix是JDBC驱动程序,因此与此类工具的集成是无缝的。
-
下载SQuirrel安装
-
把
Phoenix的phoenix-4.14.3-HBase-1.3-client.jar或phoenix-4.14.3-HBase-1.3-thin-client.jar包复制到SQuirrel的lib目录下后,点击squirrel-sql.bat启动:
-
连接配置:
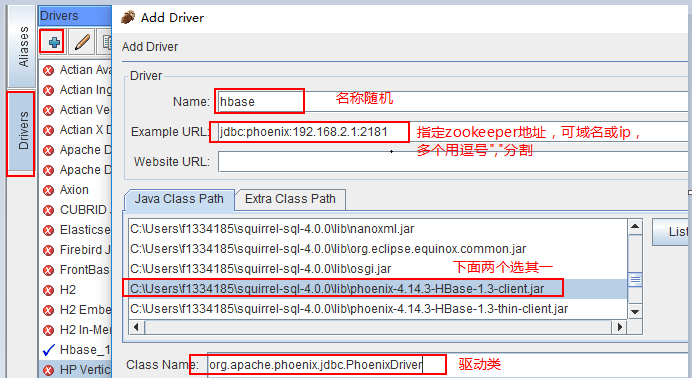
点击
OK保存 -
连接查询:

有用户名或密码时,需填。点击
test测试连接是否成功,直接OK保存如果提示报错连接不上,可能是没有在
C:\Windows\System32\drivers\etc中的hosts文件中配置路由表,例如:zookeeper的主机为名hbase-host,则在hosts中配置:192.168.2.1 hbase-host如果有多个
zookeeper主机,都需要配置。 -
查询:
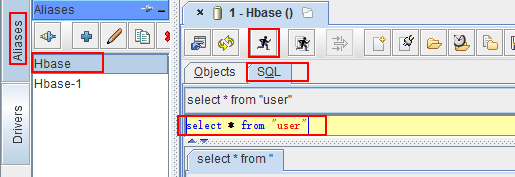
4.4、Java JDBC连接
客户端SQuirrel也是通过JDBC连接的,所以Java通过JDBC连接也需要Phoenix的phoenix-4.14.3-HBase-1.3-client.jar或phoenix-4.14.3-HBase-1.3-thin-client.jar包,这里推荐使用第二个,包比较小。
复制phoenix-4.14.3-HBase-1.3-thin-client.jar到项目下的lib目录下。

在pom.xml中配置引入:
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-thin-client</artifactId>
<version>4.14.3</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/phoenix-4.14.3-HBase-1.3-thin-client.jar</systemPath>
</dependency>
代码实现连接:
public static void main(String[] args) {
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
Connection conn = DriverManager.getConnection("jdbc:phoenix:192.168.48.221:2181");
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery("select * from \"user\"");
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
for (int i = 0; i < columnCount; i++) {
String columnName = metaData.getColumnName(i + 1);
Object object = resultSet.getObject(columnName);
System.out.println(columnName + " = " + object);
}
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
}

