
Hadoop NameNode元数据管理
参考:
https://blog.csdn.net/u011414200/article/details/50358603
HDFS的工作流程分析:https://blog.csdn.net/z66261123/article/details/51194204
NameNode 元数据相关文件目录架构
在第一次部署好 Hadoop 集群的时候,我们需要在 NameNode(NN)节点上格式化磁盘:
$HADOOP_HOME/bin/hdfs namenode -format
格式化完成之后,将会在 $dfs.namenode.name.dir/current 目录下如下的文件结构:

其中的 dfs.namenode.name.dir 是在 hdfs-site.xml 文件中配置的,默认值如下:
<property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property>
hadoop.tmp.dir 是在 core-site.xml 中配置的,默认值如下
<property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value> <description>A base for other temporary directories.</description> </property>
dfs.namenode.name.dir 属性可以配置多个目录,如 /data1/dfs/name,/data2/dfs/name ,/data3/dfs/name 等。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到 Hadoop 的元数据,特别是当其中一个目录是 NFS(网络文件系统 Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
元数据相关文件解析
下面对 $dfs.namenode.name.dir/current/ 目录下的文件进行解释。
VERSION 文件
VERSION 文件是 Java 属性文件,内容大致如下:
#Sun Dec 20 03:37:06 CST 2015 namespaceID=555938486 clusterID=CID-6d9c34e0-9d84-45be-8442-be73a03ddea8 cTime=0 storageType=NAME_NODE blockpoolID=BP-391569129-10.6.3.43-1450226754562 layoutVersion=-59
其中
namespaceID :是文件系统的唯一标识符,在文件系统首次格式化之后生成的
cTime :表示 NameNode 存储时间的创建时间,由于笔者我的 NameNode 没有更新过,所以这里的记录值为 0,以后对 NameNode 升级之后,cTime 将会记录更新时间戳
storageType :说明这个文件存储的是什么进程的数据结构信息(如果是 DataNode,storageType=DATA_NODE)
blockpoolID:是针对每一个 Namespace 所对应的 blockpool 的 ID,上面的这个 BP-391569129-10.6.3.43-1450226754562 就是在我的 nameserver1 的 namespace下的存储块池的 ID,这个 ID 包括了其对应的 NameNode 节点的 ip 地址
layoutVersion :表示 HDFS 永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的 HDFS 也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的 NameNode 无法使用
clusterID :是系统生成或手动指定的集群 ID,在 -clusterid 选项中可以使用它
seen_txid 文件
$dfs.namenode.name.dir/current/seen_txid 这个文件非常重要,是存放 transactionId 的文件,format 之后是 0,它代表的是 namenode 里面的 edits_*文件的尾数,namenode 重启的时候,会按照 seen_txid 的数字,循序从头跑 edits_0000001~ 到 seen_txid 的数字。所以当你的 hdfs 发生异常重启的时候,一定要比对 seen_txid 内的数字是不是你 edits 最后的尾数,不然会发生建置 namenode 时 metaData 的资料有缺少,导致误删 Datanode 上多余 Block 的资讯。
fsimage 和 edits 及 md5 校验文件
$dfs.namenode.name.dir/current 目录下在 format 的同时也会生成 fsimage 和 edits 文件,及其对应的 md5 校验文件。fsimage 和 edits 是 Hadoop 元数据相关的重要文件。接下来将重点讲解。
fsimage 和 edits 的工作原理
fsimage 文件其实是 Hadoop 文件系统元数据的一个永久性的检查点,其中包含 Hadoop 文件系统中的所有目录和文件 idnode 的序列化信息;
edits存放的是 Hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所以写操作首先会被记录到 edits文件中。
fsimage 和 edits 文件都是经过序列化的,在 NameNode 启动的时候,它会将 fsimage 文件中的内容加载到内存中,之后再执行 edits 文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
NameNode 起来之后,HDFS 中的更新操作会重新写到 edits 文件中,因为 fsimage 文件一般都很大(GB 级别的很常见),如果所有的更新操作都往 fsimage 文件中添加,这样会导致系统运行的十分缓慢,但是如果往 edits 文件里面写就不会这样,每次执行写操作之后,且在向客户端发送成功代码之前,edits 文件都需要同步更新。如果一个文件比较大,使得写操作需要向多台机器进行操作,只有当所有的写操作都执行完成之后,写操作才会返回成功,这样的好处是任何的操作都不会因为机器的故障而导致元数据的不同步。
fsimage 并不包含 DataNode 的信息,而是包含 DataNode 上块的映射信息,并存放到内存中,当一个新的 DataNode 加入到集群中,DataNode 都会向 NameNode 提供块的信息,而 NameNode 会定期的“索取”块的信息,以使得 NameNode 拥有最新的块映射。因为 fsimage 包含 Hadoop 文件系统中的所有目录和文件 idnode 的序列化信息,所以如果 fsimage 丢失或者损坏了,那么即使 DataNode 上有块的数据,但是我们没有文件到块的映射关系,我们也无法用 DataNode 上的数据!所以定期及时的备份 fsimage 和 edits 文件非常重要!
备用 NameNode,secondary namenode
备用NameNode周期性地合并fsimage和edits文件,将edits限制在一个范围内,备用NameNode与主NameNode通常运行在不同的机器上,因为备用NameNode与主NameNode有同样的内存要求。
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
checkpoint的详细过程
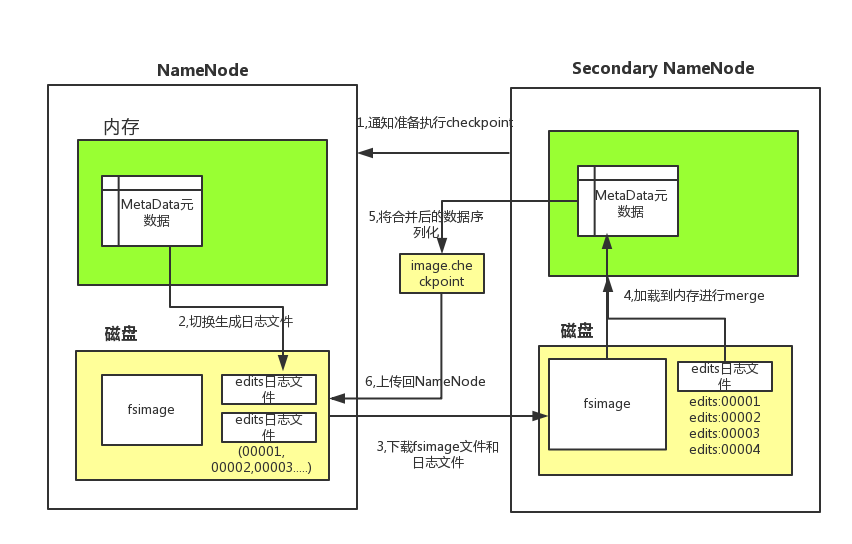
过程解析:
- 从SecondaryNameNode节点通知NameNode进行CheckPoint
- NameNode切换出新的日志文件,以后的日志都写到新的日志文件中。
- 从SecondaryNameNode节点从节点下载fsimage文件及旧的日志文件,fsimage文件只有第一次下载,以后只需要传输edits日志文件
- SecondaryNameNode节点将fsimage文件加载到内存中,并将日志文件与fsimage的合并,然后生成新的fsimage文件。
- 从SecondaryNameNode节点将新的fsimage文件用传回NameNode节点
- NameNode节点可以将旧的fsimage文件及旧的日志文件切换为新的fsimage和edit日志文件并更新fstime文件,写入此次checkpoint的时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号