
HDFS读文件过程
参考:
HDFS的工作流程分析:https://blog.csdn.net/z66261123/article/details/51194204
Hadoop核心-HDFS读写流程:https://yq.aliyun.com/articles/325428
HDFS读数据流程概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
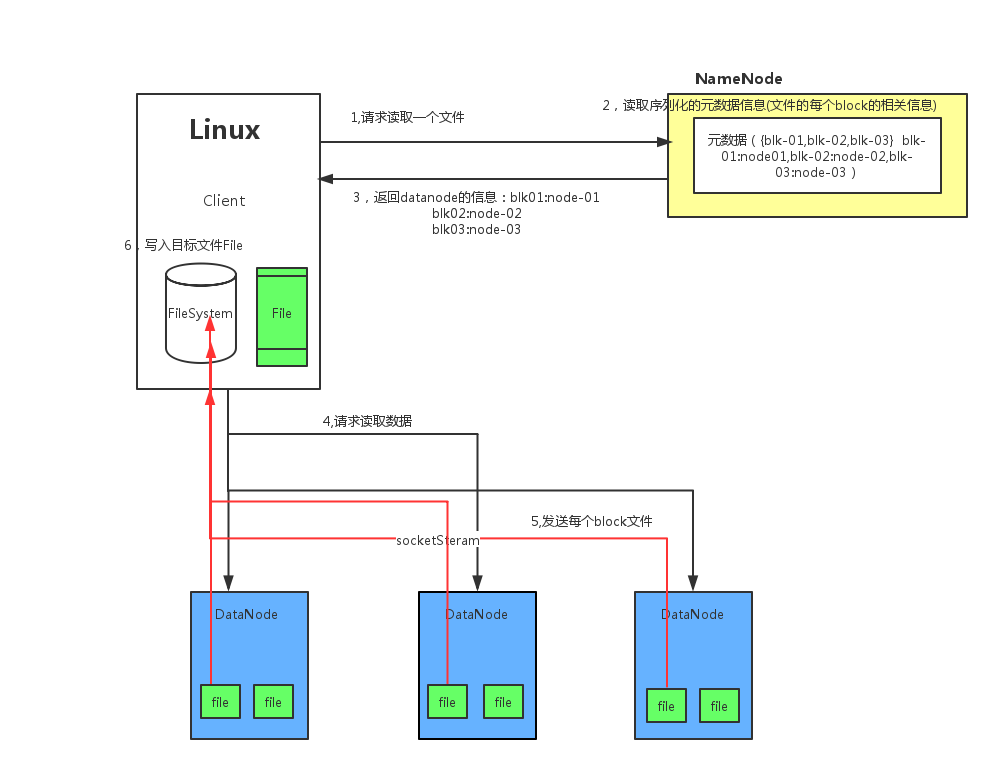
HDFS读数据步骤:
- Client向NameNode发起RPC请求,来确定请求文件block所在的位置
- NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址
- 这些返回的DN地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离Client的排在前;心跳机制中超时汇报的DN状态为STALE,这样的排在后
- Clietn选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据
- 底层本质是建立Socket Stream(FSDataInputStream) ,重复调用父类DataInputStream的read方法,知道这个块上的数据读取完毕
- 当读完列表的block后,若文件读取还没有结束,客户端会继续想NameNode获取下一批的block列表
- 读取完一个Block都会进行checksum验证,如果读取DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读取。注: 如果在读取过程中DFSInputStream检测到block错误,DFSInputStream也会检查从datanode读取来的数据的校验和,如果发现有数据损坏,它会把坏掉的block报告给namenode同时重新读取其他datanode上的其他block备份
- read方法是并行的读取block信息,不是一块一块的读取,NameNode只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据
- 最终读取哎所有的block会合并成一个完整的最终文件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号