
hadoop伪分布式安装
hadoop有三种运行模式:
1,本地运行模式:hadoop的默认模式,没有守护进程,所有的程序都在同一个jvm里运行,在该模式下调试MR程序非常方便。
2,伪分布式模式,所有进程运行在一台服务器,效果跟分布式模式一样。
3,分布式模式:进程运行在多台服务器上。
一、本地运行模式:
这是hadoop的默认工作模式,不需要进行其它配置,例如运行单词统计例子,直接运行命令:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount /root/test/input/ /root/test/output
注意:/root/test目录不要创建,运行前确保Java已安装。
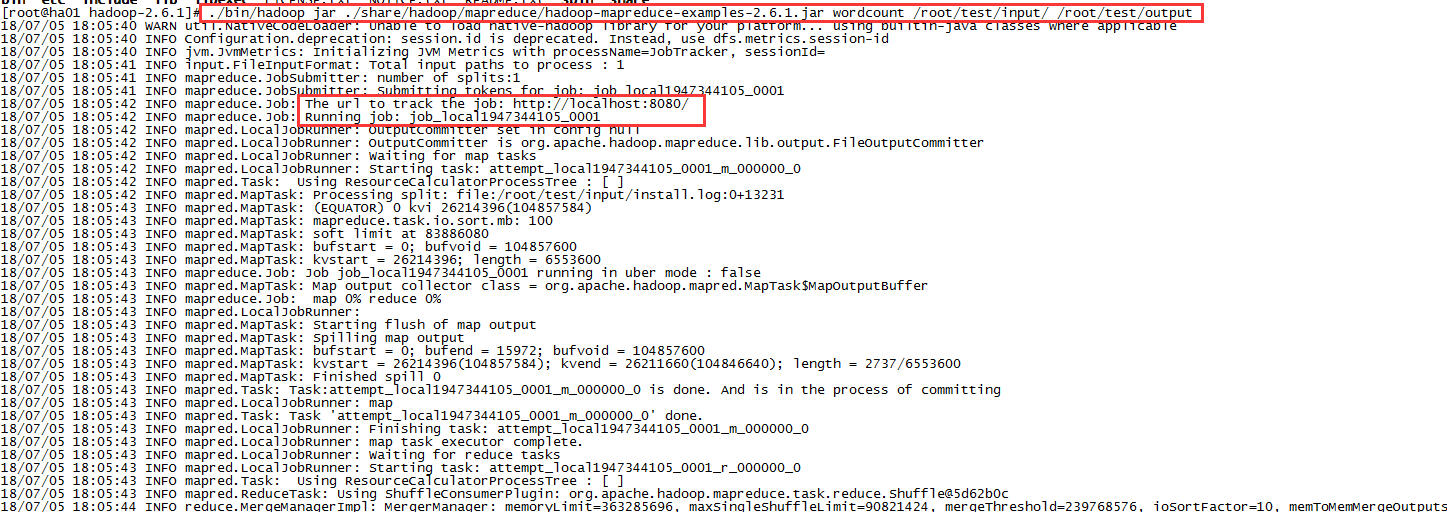

运行完后在/root/test/output可看到输出文件
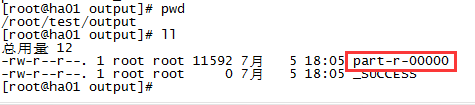
输出的内容在part-r-00000文件里,_SUCCESS文件为空,只是成功标识,查看part-r-00000文件内容:cat part-r-00000
二、伪分布式模式:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
1,安装ssh,如果已经安装过则跳过。
yum install openssh-clients
2,上传解压
window环境下在官网下载hadoop压缩包hadoop-2.6.1.tar.gz,上传到centos服务器,把文件解压到/usr/local/下。


3,配置环境变量
修改家目录下的.bashrc文件,添加hadoop环境变量:
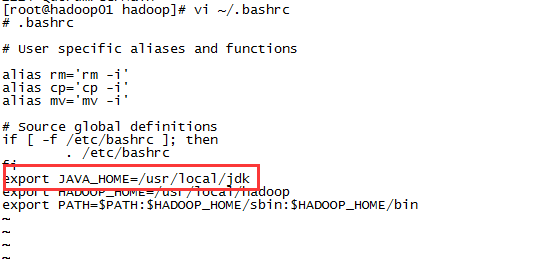
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
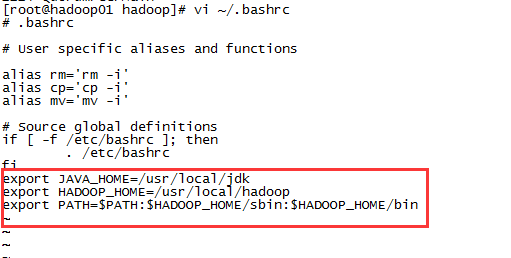
然后加载环境变量:source ~/.bashrc
4,修改配置文件
伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml,配置文件在/usr/local/hadoop/etc/hadoop/中。
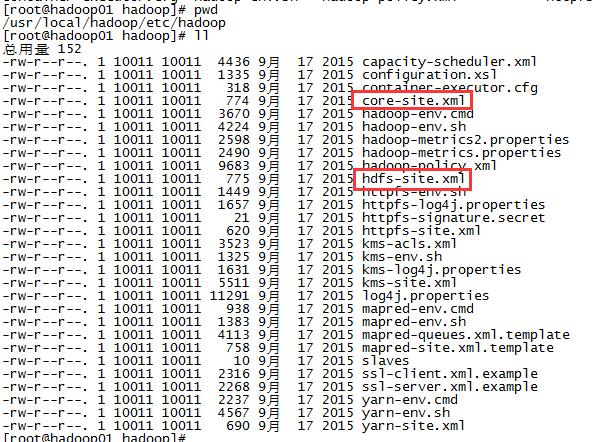
修改配置文件 core-site.xml,修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改配置文件 hdfs-site.xml,修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
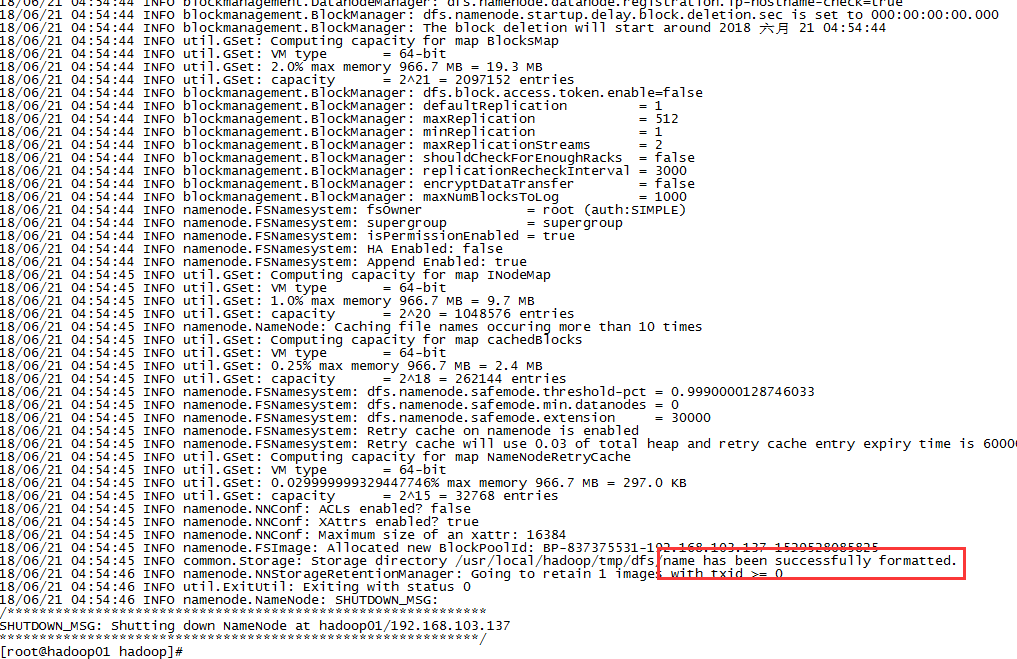
5,格式化,配置完后要格式化才能启动。
./bin/hdfs namenode -format
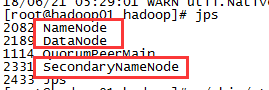
6,启动hdfs
./sbin/start-dfs.sh

用jps查看进程
在window下通过浏览器访问:http://192.168.103.137:50070
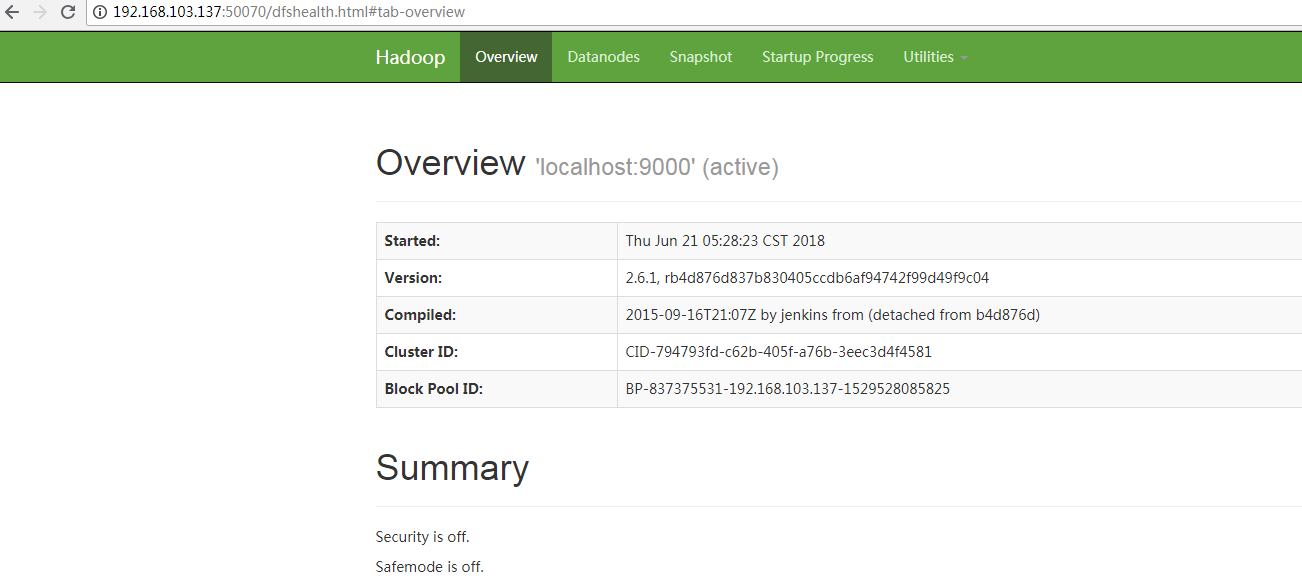
至此hadoop启动成功!
问题1:没有安装ssh

提示ssh: command not found,需要安装ssh客户端:
yum install openssh-clients
问题2:JAVA_HOME没有配置
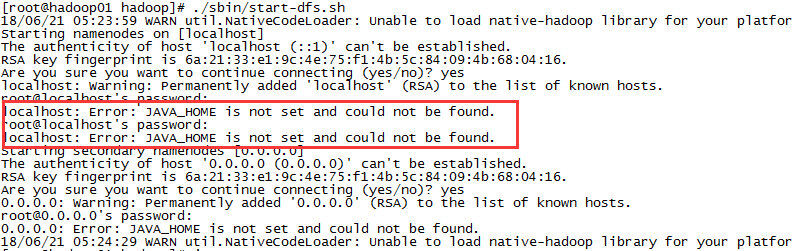
要添加JAVA_HOME变量,vi ~/.bashrc ,添加export JAVA_HOME=/usr/local/jdk
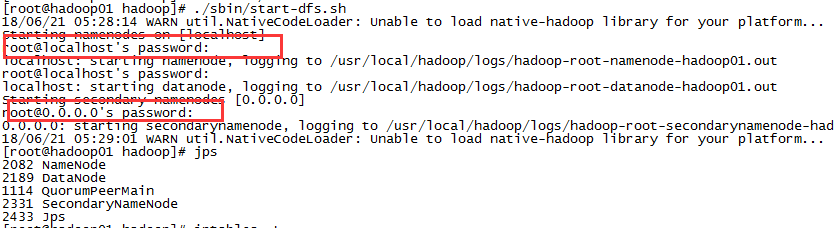
问题3:SSH免密登入
在上面启动hdfs中需要手动输入密码,可配置SSH免密登入,这样启动过程中就不需要输入密码了。
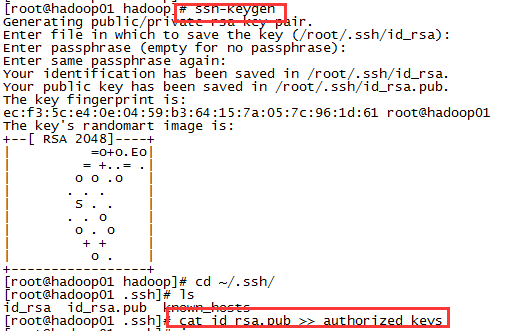
1)ssh-keygen,然后一直回车
2),将生成的公匙加入到授权列表中
cat id_rsa.pub >> authorized_keys


 浙公网安备 33010602011771号
浙公网安备 33010602011771号