基于Kubeadm搭建单Master节点的k8s集群
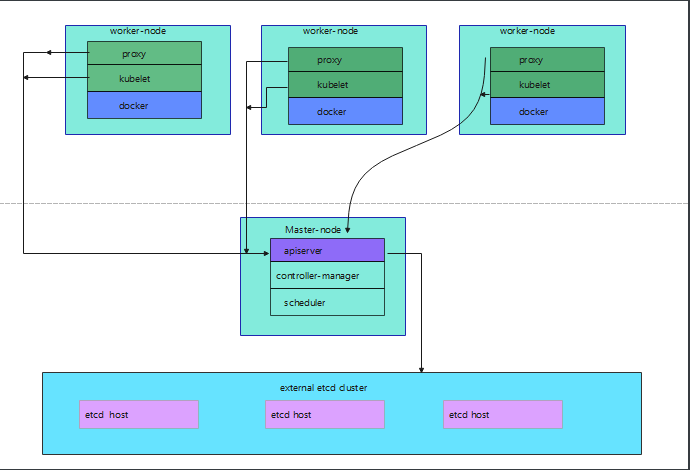
#(服务器硬件配置要求)
1.在开始部署k8s集群之前,服务器需要满足以下条件:
2.一台或多台服务器,操作系统CentOS 7.x-86_x64。(本次实验机器:centos7.9)
3.硬盘配置:内存2GB或更多,CPU2核或更多,硬盘30GB或更多。
4.集群中的所有机器之间网络互通。
5.可以访问外网,需要拉取镜像。
6.禁止swap分区。
7.关闭防火墙
8.关闭selinux#搭建k8s集群部署方式#
目前生产部署k8s集群主要有两种方式:
# kubeadm:
kubeadm是一个k8s部署工具,提供kubeadmin init和kubeadm join,用于快速部署k8s集群。
官网地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/


#修改各节点的主机名:
[16:48:11 root@Centos7 ~]#hostnamectl set-hostname K8s-Master
[16:48:22 root@Centos7 ~]#hostnamectl set-hostname K8s-node1
[16:48:25 root@Centos7 ~]#hostnamectl set-hostname K8s-node2
#系统初始化:
#关闭防火墙:
[16:58:30 root@k8s-master ~]#systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[17:00:27 root@k8s-master ~]#systemctl disable --now firewalld
#worker-node各节点设置:
[16:58:57 root@k8s-node1 ~]#systemctl stop firewalld
[17:01:05 root@k8s-node1 ~]#systemctl disable --now firewalld
[17:08:00 root@k8s-worker-node2 ~]#systemctl stop firewalld
[17:08:18 root@k8s-worker-node2 ~]#systemctl disable --now firewalld
#关闭selinux:
[17:07:52 root@k8s-master ~]#cat /etc/selinux/config
# disabled - No SELinux policy is loaded.
SELINUX=disabled #这行设置为disabled即可
# SELINUXTYPE= can take one of three values:
#同理worker-node各节点都是需要设置!
#关闭swap分区:
@#永久关闭swap分区:
# 永久
sed -ri 's/.*swap.*/#&/' /etc/fstab
@#临时关闭swap分区:
swap defaults 0 0
[17:21:14 root@k8s-master ~]#cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Tue Mar 22 09:33:48 2022
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=dce48e2c-a6fb-4ab5-bb54-70f0b6af0875 / xfs defaults 0 0
UUID=93b01793-dad0-4247-b5a0-1e98c9edac29 /boot ext4 defaults 1 2
UUID=add32c35-6598-448e-b973-950c27cc6181 /data xfs defaults 0 0
#UUID=edd46aa9-725c-4ae6-81ee-62f53091d22f swap swap defaults 0 0
#临时关闭swap分区:
swapoff -a
#在master节点上添加hosts:
[17:23:40 root@k8s-master ~]#vim /etc/hosts
#在每个节点添加hosts:
[17:28:26 root@k8s-master ~]#cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.7 K8s-Master
10.0.0.17 K8s-node1
10.0.0.27 K8s-node2
[17:32:49 root@k8s-master ~]#scp /etc/hosts 10.0.0.27:/etc/
[17:33:19 root@k8s-master ~]#scp /etc/hosts 10.0.0.17:/etc/
#将桥接的IPv4流量传递到iptables的链:
#在每个节点添加如下的命令:
[17:35:32 root@k8s-master ~]#cat > /etc/sysctl.d/k8s.conf << EOF
> net.bridge.bridge-nf-call-ip6tables = 1
> net.bridge.bridge-nf-call-iptables = 1
> net.ipv4.ip_forward = 1
> vm.swappiness = 0
> EOF
[17:36:21 root@k8s-worker-node1 ~]#cat > /etc/sysctl.d/k8s.conf << EOF
...
[17:36:24 root@k8s-worker-node2 ~]#cat > /etc/sysctl.d/k8s.conf << EOF
...
#加载br_netfilter模块:
[17:36:15 root@k8s-master ~]#modprobe br_netfilter
[17:37:35 root@k8s-worker-node1 ~]#modprobe br_netfilter
[17:37:53 root@k8s-worker-node2 ~]#modprobe br_netfilter
# 查看是否加载:
lsmod | grep br_netfilter
# 生效
sysctl --system
[17:41:38 root@k8s-master ~]#sysctl --system
[17:43:03 root@k8s-worker-node1 ~]#sysctl --system
[17:43:06 root@k8s-worker-node2 ~]#sysctl --system
#时间同步:
#在每个节点添加时间同步::
[17:44:24 root@k8s-master ~]#yum install ntpdate -y
[17:45:57 root@k8s-master ~]#ntpdate time.windows.com
[17:46:01 root@k8s-worker-node1 ~]#ntpdate time.windows.com
[17:46:04 root@k8s-worker-node2 ~]#ntpdate time.windows.com
#开启ipvs:
#在每个节点安装ipset和ipvsadm:
[17:46:36 root@k8s-worker-node2 ~]#yum -y install ipset ipvsadm
#在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
[17:54:02 root@k8s-master ~]#cat /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
#其他worker-node节点也是同样配置:
[17:49:00 root@k8s-worker-node1 ~]#cat > /etc/sysconfig/modules/ipvs.modules <<EOF
[17:49:11 root@k8s-worker-node2 ~]#cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#检查是否加载:
lsmod | grep -e ipvs -e nf_conntrack_ipv4
[17:56:01 root@k8s-master ~]#lsmod | grep -e ipvs -e nf_conntrack_ipv4
nf_conntrack_ipv4 15053 0
nf_defrag_ipv4 12729 1 nf_conntrack_ipv4
nf_conntrack 139264 2 ip_vs,nf_conntrack_ipv4
#同理其他node节点也是需要检查
#k8s默认CRI(容器运行时)为Docker,因此需要先安装Docker。
#安装Docker:
#下载docker软件镜像源仓库:
[17:58:30 root@k8s-master ~]#wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
[18:05:31 root@k8s-master ~]#ll /etc/yum.repos.d/docker-ce.repo
-rw-r--r-- 1 root root 2081 8月 13 18:04 /etc/yum.repos.d/docker-ce.repo
#同理,其他node节点也需要配置:后续都是需要安装docker
#下载安装docker:
[18:05:40 root@k8s-master ~]#yum -y install docker-ce-18.06.3.ce-3.el7
[18:10:18 root@k8s-master ~]#docker --version
Docker version 18.06.3-ce, build d7080c1
#同理其他两个Node节点也是需要安装docker:
[18:10:01 root@k8s-worker-node1 ~]#yum -y install docker-ce-18.06.3.ce-3.el7
[18:04:55 root@k8s-worker-node2 ~]#yum -y install docker-ce-18.06.3.ce-3.el7
#启动docker ,并且设置为开机自启:
[18:10:24 root@k8s-master ~]#systemctl enable --now docker.service
#其他的node节点:
[18:12:06 root@k8s-worker-node1 ~]#systemctl enable --now docker.service
[18:12:09 root@k8s-worker-node2 ~]#systemctl enable --now docker.service
#设置Docker镜像加速器:
[18:23:33 root@k8s-master ~]#cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
#复制改配置文件到node节点:
[18:22:44 root@k8s-master ~]#scp /etc/docker/daemon.json 10.0.0.17:/etc/docker/
[18:23:55 root@k8s-master ~]#scp /etc/docker/daemon.json 10.0.0.27:/etc/docker/
#添加阿里云的YUM软件源:
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#拷贝该配置文件到各个node节点:
[18:26:01 root@k8s-master ~]#scp /etc/yum.repos.d/kubernetes.repo 10.0.0.17:/etc/yum.repos.d/
[18:27:05 root@k8s-master ~]#scp /etc/yum.repos.d/kubernetes.repo 10.0.0.27:/etc/yum.repos.d/
#构建一下缓存:
所有节点执行:
# yum makecache
#这里指定版本号部署:
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
#附:为了实现Docker使用的cgroup drvier和kubelet使用的cgroup drver一致,建议修改"/etc/sysconfig/kubelet"文件的内容:
vim /etc/sysconfig/kubelet
# 修改
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
#设置为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动:
# systemctl enable kubelet
部署k8s的Master节点:
部署k8s的Master节点(10.0.0.7):
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库的地址:
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址
kubeadm init \
--apiserver-advertise-address=10.0.0.7 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
#根据提示信息,在Master节点上使用kubectl工具:
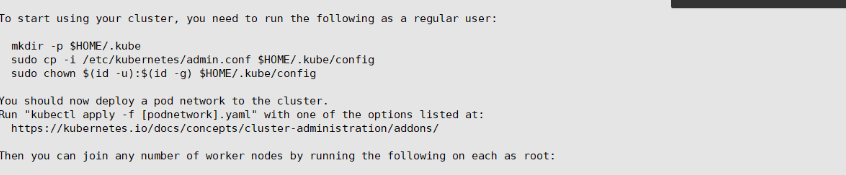
# Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.0.0.7:6443 --token v5hx88.ul4y1bl0vtttliw3 \
--discovery-token-ca-cert-hash sha256:410d3799534232808afa42d2c12269dcdb3299ce7a66af78fc868602dc807ff9
#根据提示信息,在Master节点上使用kubectl工具:
[19:05:12 root@k8s-master ~]#mkdir -p $HOME/.kube
[19:44:34 root@k8s-master ~]#cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[19:44:53 root@k8s-master ~]#chown $(id -u):$(id -g) $HOME/.kube/config
#看一下状态:
[19:44:59 root@k8s-master ~]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady master 40m v1.18.0
#添加k8s的Node节点:
在10.0.0.17和10.0.0.27上添加如下的命令:
kubeadm join 10.0.0.7:6443 --token v5hx88.ul4y1bl0vtttliw3 \
--discovery-token-ca-cert-hash sha256:410d3799534232808afa42d2c12269dcdb3299ce7a66af78fc868602dc807ff9
##############node节点加入master节点报错解决方法################
#这边实验kubeadm 加入到集群里 报错:
....
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused.
...
###############说明是kublet服务状态问题###############
#先将kubelet服务关了:systemctl stop kubelet
#(原因)该服务先不要开启,当使用kubeadm join 命令加入到master节点时,会自动开启。
#之后再执行一遍:kubeadm join...
#这时会报错:
...
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR FileAvailable--etc-kubernetes-bootstrap-kubelet.conf]: /etc/kubernetes/bootstrap-kubelet.conf already exists
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
...
#此时再使用:kubeadm join...最后面加上--ignore-preflight-errors=all
#忽略文件存在的错误警告,因为之前加入过一次集群,有些文件已经存在了,所以会报错;或者初始化也行-强制重置(kubeadm reset -f):再继续执行 kubeadm join... 即可!
#注意一定要确保docker服务是正常启动的!
#附知识扩展 【点击打开】
#附知识扩展:默认的token有效期为24小时,当过期之后,该token就不能用了,这时可以使用如下的命令创建token:
kubeadm token create --print-join-command
# 生成一个永不过期的token
kubeadm token create --ttl 0#根据提示,在Master节点使用kubectl工具查看节点状态:
kubectl get nodes
[20:40:03 root@k8s-master ~]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady master 124m v1.18.0
k8s-worker-node1 NotReady <none> 23m v1.18.0
k8s-worker-node2 NotReady <none> 16m v1.18.0
#在Master节点部署CNI网络插件(可能会失败,如果失败,请下载到本地,然后安装):
[21:09:55 root@k8s-master ~]#wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#######wget直接下载对应的配置文件,可能会失败(,国外网站,原因你懂得),可以用浏览器通过某种方式先下载到本地,再进行安装。###############################
[21:09:55 root@k8s-master ~]#wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
--2022-08-13 21:15:31-- https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
正在解析主机 raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.111.133, ...
正在连接 raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... 失败:拒绝连接。
正在连接 raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:4583 (4.5K) [text/plain]
正在保存至: “kube-flannel.yml”
100%[=========================================================================================>] 4,583 --.-K/s 用时 0.1s
2022-08-13 21:15:58 (39.5 KB/s) - 已保存 “kube-flannel.yml” [4583/4583])
#或者:kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[21:18:50 root@k8s-master ~]#ll kube-flannel.yml
-rw-r--r-- 1 root root 4583 8月 13 21:15 kube-flannel.yml
[21:19:55 root@k8s-master ~]#kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
#查看部署CNI网络插件进度:
[21:21:21 root@k8s-master ~]#kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-cr9p8 1/1 Running 0 137m
coredns-7ff77c879f-mnnd6 1/1 Running 0 137m
etcd-k8s-master 1/1 Running 3 137m
kube-apiserver-k8s-master 1/1 Running 3 137m
kube-controller-manager-k8s-master 1/1 Running 2 137m
kube-proxy-6s258 1/1 Running 0 29m
kube-proxy-7k7qd 1/1 Running 0 35m
kube-proxy-mj2sg 1/1 Running 2 137m
kube-scheduler-k8s-master 1/1 Running 2 137m#此时再次在Master节点使用kubectl工具查看节点状态:
[21:22:41 root@k8s-master ~]#kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 138m v1.18.0
k8s-worker-node1 Ready <none> 37m v1.18.0
k8s-worker-node2 Ready <none> 30m v1.18.0
#此时已经是Ready状态!
#再查看集群健康状态:
[21:24:04 root@k8s-master ~]#kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
本文来自博客园,作者:一念6,转载请注明原文链接:https://www.cnblogs.com/zeng666/articles/16584384.html
